[人物一致性]全套工作流详细指南(第二篇)图像修复以及分割多表情
前言:
人物一致性一直是难以解决的难题,最近从Mick大佬处获得灵感,我们可以使用Lora模型去进行人物特征的控制,从而完成一致人物的创作,但在这之前我们需要经过数据集生成,数据集处理以及Lora训练等过程,所以接下来我会用几篇文章将整个过程进行完整的复刻,并且会将中间产生的各种对比进行展示。
我基于这个方法训练的Lora模型:https://civitai.com/models/922842/a-character-named-ssx
全部内容整合包百度网盘:__ https://pan.baidu.com/s/1kMWahSx3_5Ht0m95yrl_XA?pwd=728c__
全部内容整合包夸克网盘:https://pan.quark.cn/s/f0aeb1899a47
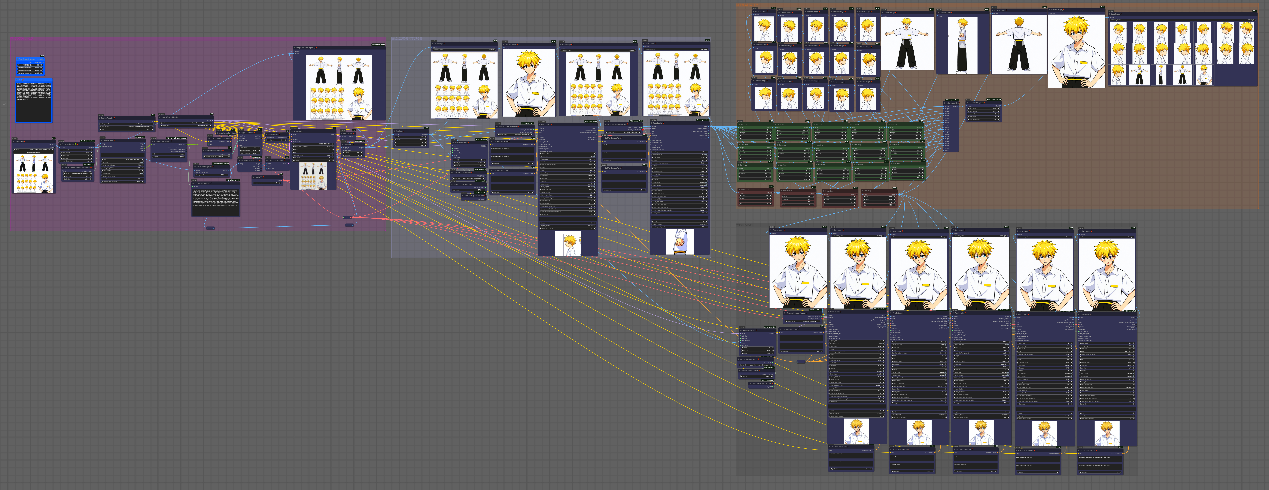
该阶段工作流如上图所示,此时的放大不仅要增加图像的分辨率而且需要对原图毁坏部分进行重绘,所以我选择Flux+UPscaler的方式进行图像的高清修复,因为该过程需要涉及到扩散并且会对原图产生一定的修复,同时又能够利用Flux模型优秀的美学特征能力,而且在一整张图像进行扩散的时候能够从全局进行一致性人物的控制,综上所述,初步的放大阶段,使用该方式。
一、下图为放大模块的主要工作流,其中有几个注意事项一定要重视。
- Florence提示词反推要在反推后卸载模型
当我们对图像进行高清修复时,因为要进行扩散,所以需要引入提示词,如果能够提供符合原图的提示词,那么一定会使扩散的过程更加的稳定可控,所以我们需要使用到合适的提示词反推模型去完成图片的描述,F__lux模型使用Clipl+T5模型作为文本编码模块,在训练的过程中使用自然语言进行图像的标注,所以我们需要选择LLM进行提示词的反推,诸如“prompt styler,WD14”的短词提示词反推模型就不适合在Flux模型中使用,而诸如Ollama,joycaption,molmo等模型就能更好地完成任务,而__LLM对显存的占用会到较高的程度,所以我们必须在模型反推完提示词之后进行模型的卸载,不然会严重影响我们出图的速度,毕竟后续是使用了Flux+upscaler+1536*1536的出图尺寸。即上图节点必须关闭keep_model_loaded参数。
- UPscaler模型的强度会较为影响出图效果
在测试的过程中发现UPscaler模型的强度对最终的出图效果会有较为强烈的影响,当我们设置模型的强度过高,则会导致模型在扩散的过程中更见偏向与拟合输入的图像(即毁坏的图像),所以修复程度较低。
下图为1.0的控制强度,最终出图区域拟合原图中毁坏的地方,所以约等于重绘幅度很低,最终出图人物的面部特征修复并不明显,特别是较小的脸部(左下角),会导致无面部特征。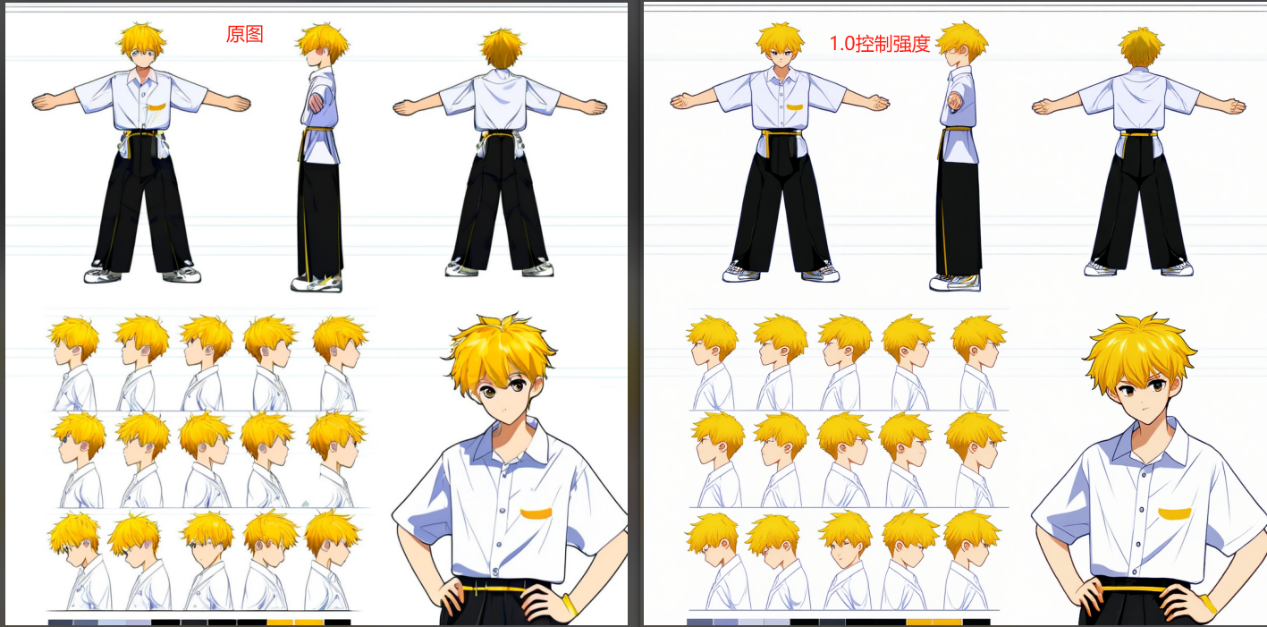
下图为0.5的控制强度,可以看到减弱控制强度相当于增强模型的重绘幅度,最终出图完成了人物的面部修复,并且在较小的面部仍然能够很好地完成面部特征描绘。
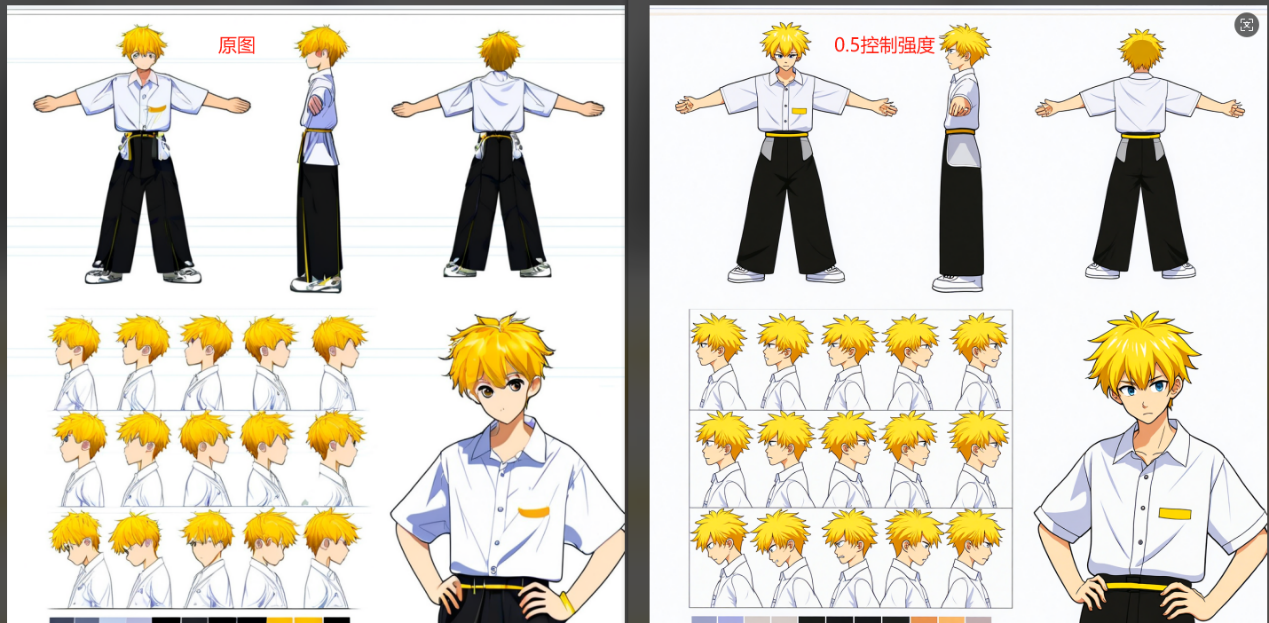
下图为0.5的控制强度,以及0.5的end_persent,这只是提供的一种参考参数设置,大家可以按照自己的想法创建,从对比结果来看效果跟上面的0.5控制强度差不多,但是我个人想让模型能够有更大的空间去发挥自己的性能,所以在end_persent就多给出了0.5的自我发挥时间。

- Color match进行色彩匹配
当我们使用UPscaler进行图像放大后,因为放给了模型一定的自我发挥空间,所以就会带来一定的副作用,比如最终出图会影响原图的色彩信息,如下图所示,当我们完成了图像的修复以及分辨率放大,图片的背景就不再是纯白色,进而带来的就是图片发灰,而背景和主体的颜色对比会影响,(当图片主体和背景的对比产生变化,会导致最终出图受影响,最明显的就是在人物换装插件中,如果上传参考衣服背景不是纯白,换装后衣服会产生色差),所以我就做了一个color match操作,(也可能是多虑了,反正大家自己考虑是否使用)。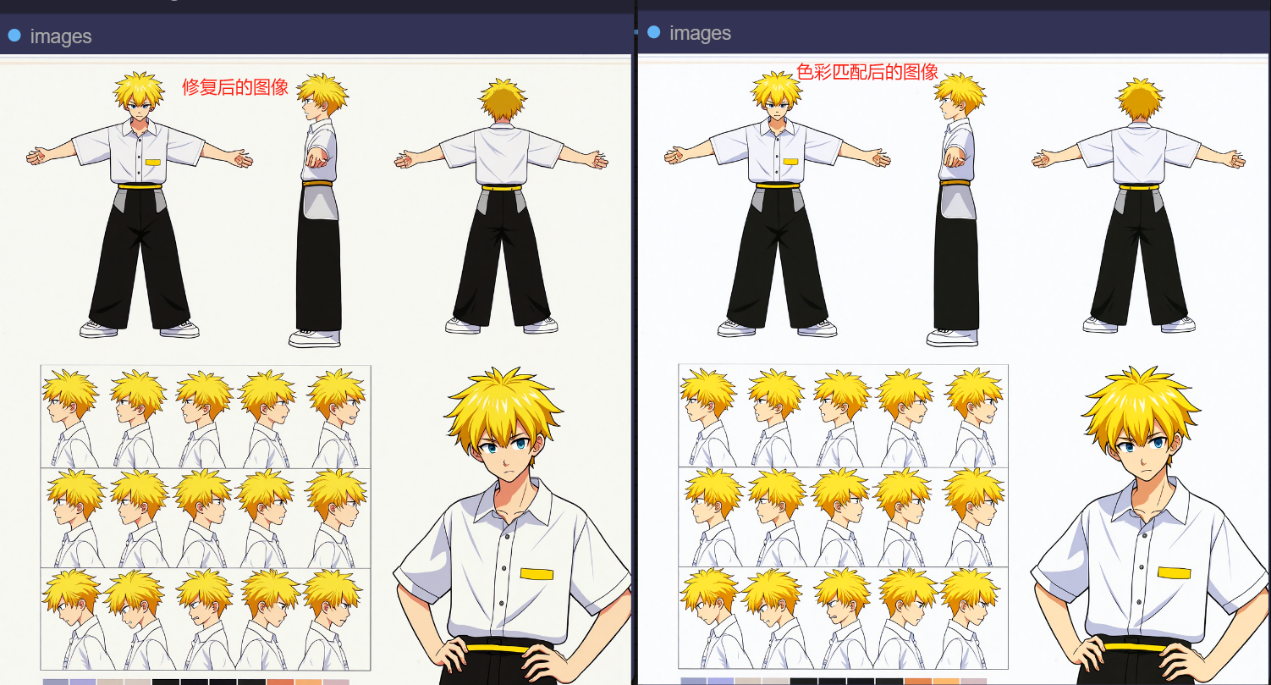
二、下图为修复模块的工作流
在该模块使用两个facedetailer节点用来做原图的修复,根据上传BBox探测器的不同完成不同部分的修复,比如当我们上传hand检测模型,则该节点功能为对原图进行手部修复。
在进行脸部修复之前,我加载了Pulid模型来增强面部的相似程度,因为该节点是分区域进行重绘,并不如Flux upscaler模型一样进行全局的重绘,所以在这个阶段我们有必要去保持人物面部的相似程度,那么当前在Flux模型中,面部迁移就使用Pulid就可。
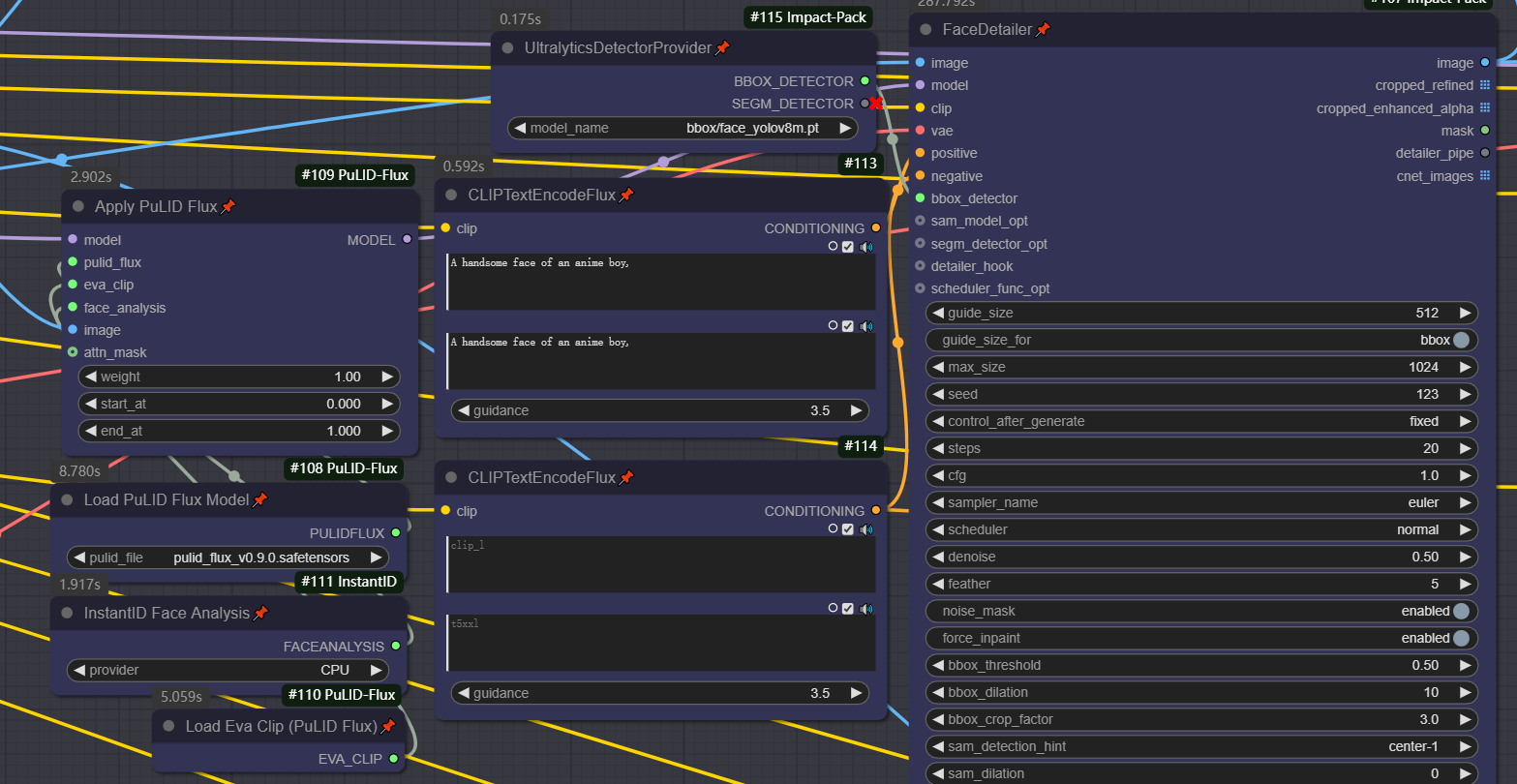
下方节点可以通过选择不同的模型去完成不同区域的重绘,所以大家需要根据自己的图像需要修复的区域去选择对应的模型。
三、多表情生成区域。
__
__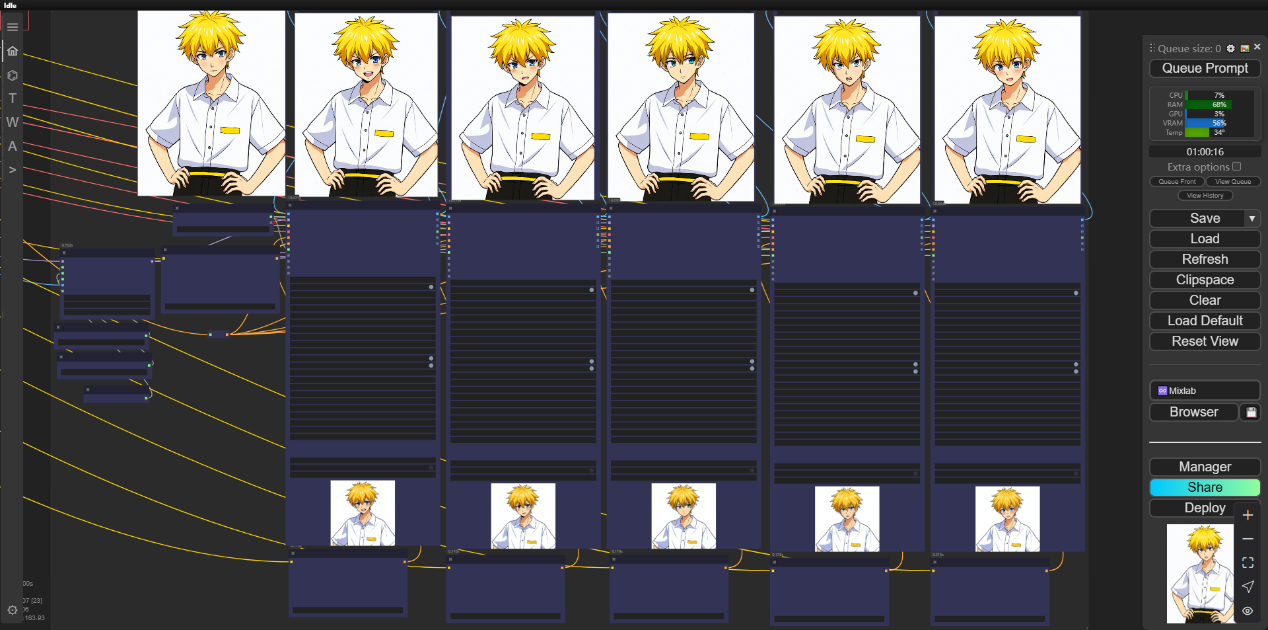
该部分依然使用多个facedetailer节点去进行面部表情的更换,依然需要加载Pulid模型去保证人物面部特征的统一,通过提示词和增加重绘幅度来完成面部表情的变换,因为使用了Flux模型,所以我们只需要修改正向提示词即可。
在我测试的过程中,发现提示词和Pulid并不能完全控制人物眼睛颜色变化,可能是由于重绘幅度并不高的原因,但是增加重绘幅度会导致出图的边缘融合度降低,所以需要大家自行选择或者尝试多次抽卡去完成数据集的生成。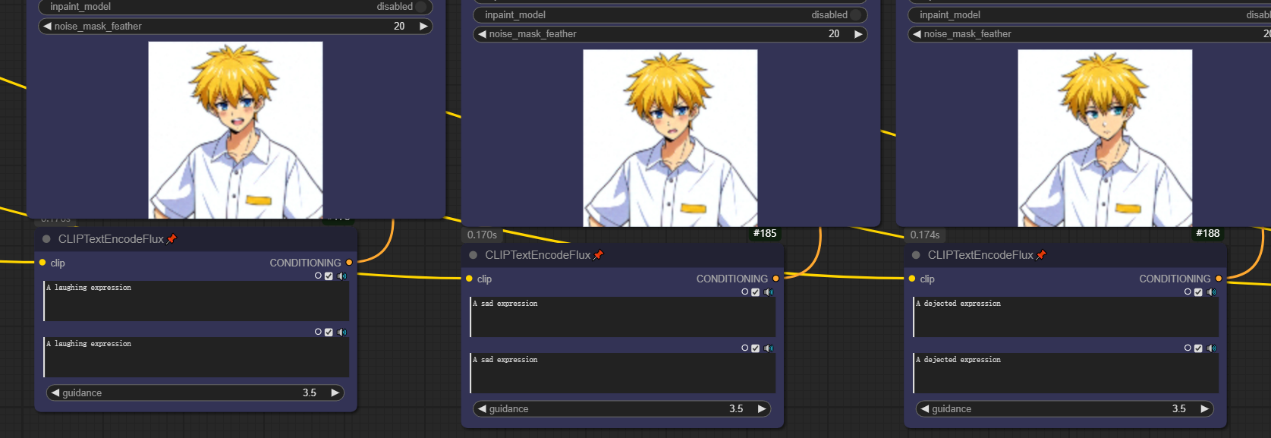
四、图像分割以及放大保存区域
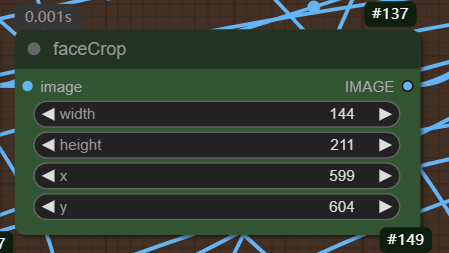
该区域需要完成图像的裁剪,因为坐标的不同以及图像大小的不同,所以可能需要大家自行调整参数。
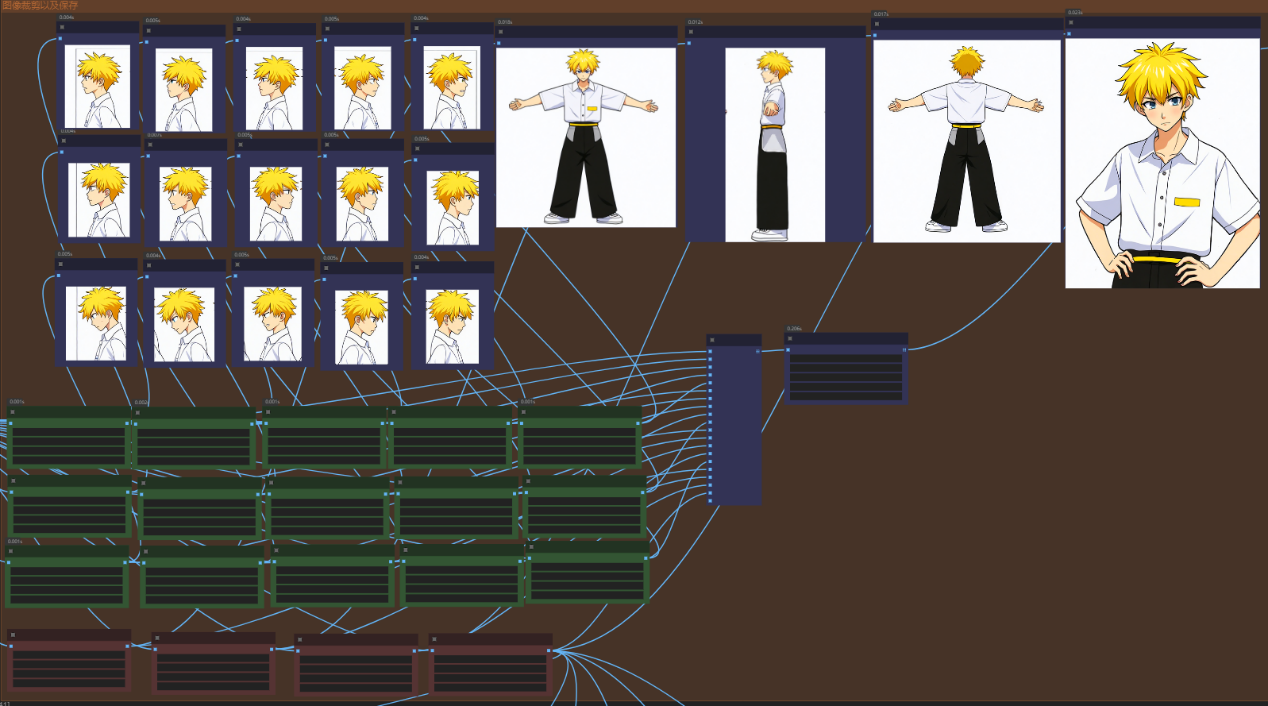
下面的节点为设置裁剪图像的长宽,然后设置裁剪的坐标起始位置,在ComfyUI中,坐标原点从图像的左上角开始(不同的插件可能有区别),所以如果大家跑图的时候出现在裁剪图像不符合原图,则需要大家自行进行参数的调整。
图像尺寸调整完毕之后,我们需要将图像进行保存,但是保存之前我们要将尺寸调整到适合Flux的lora训练的大小,在SD1.5模型中,使用到的数据集是512*512的尺寸,但是在SDXL和SD3架构下的大模型,训练集使用的是1024*1024的尺寸,所以我们需要将我们的图像调整到1024附近。下图所示的节点即完成了图像到list的处理,并且完成了图像尺寸的调整,同时保持数据集的分辨率。但是此时的数据集还不能够使用,需要在做下一步的去噪和放大。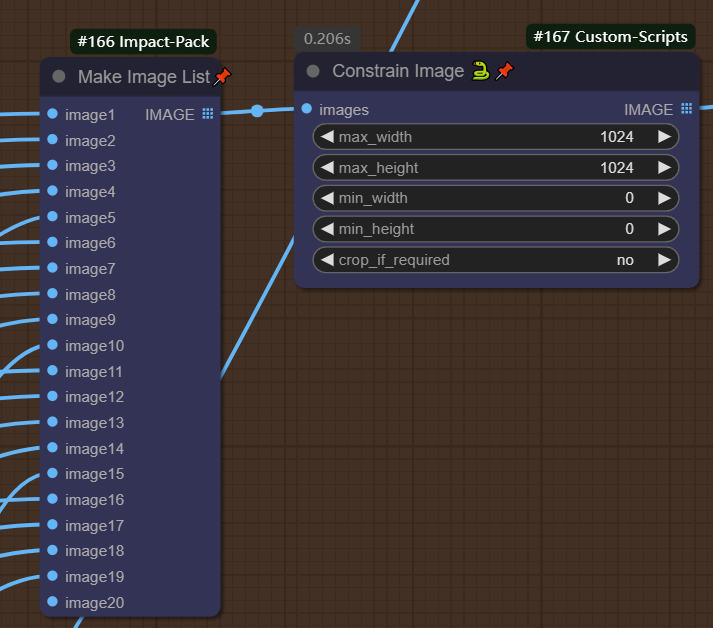
数据集的保存文件夹为output/im/下。
