【ComfyUI插件】ComfyUI-LivePortraitKJ插件
前言:
LivePortrait 是一个能支持的实时面部驱动的虚拟换脸、表情重定向和面部特征合成的系统,通常用于将一个人的面部特征映射到另一个人的面部模型上。它能够使一个人的面部表情、动作、或者姿态实时地映射到另一个人的面部形象上,或者用在基于视频的动画中,例如虚拟人物的面部动画。
本期使用的示例工作流在网盘:小黄瓜知识星球资料分享/插件节点讲解视频/LivePortrait文件夹中
目录:
先行:安装方法
一、Load LivePortaitModels节点
二、LivePortrait Load MediaPipeCropper节点
三、LivePortrait Load InsightFaceCropper节点
四、LivePortrait Load FaceAlignmentCropper节点
五、LivePortrait Cropper节点
六、LivePortrait KeypointsToImage节点
七、LivePortrait Process节点
八、LivePortrait Retargeting节点
九、LivePortrait Composite节点
安装方法:
在ComfyUI\custom_nodes目录里面输入CMD回车。
在弹出的CMD命令行输入git clone xxx,即可开始下载。
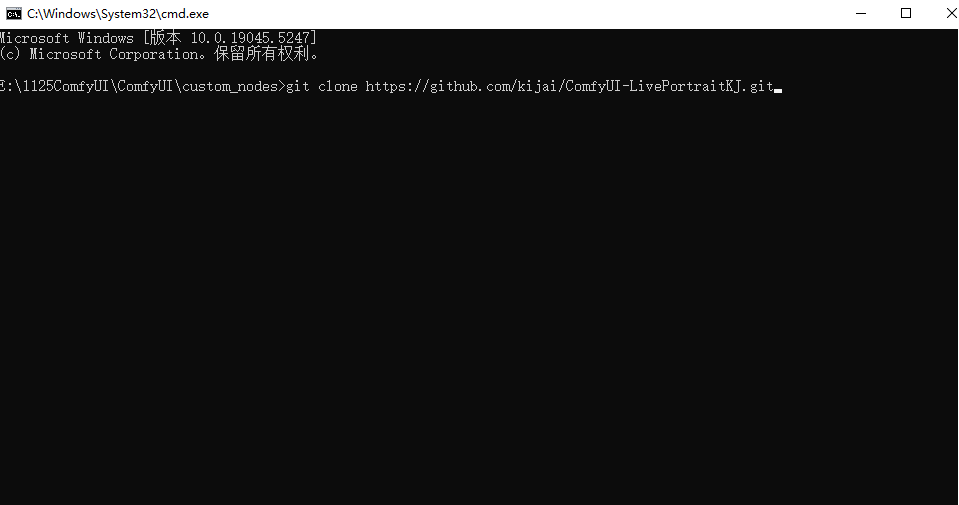
github项目地址:https://github.com/kijai/ComfyUI-LivePortraitKJ.git
一、 Load LivePortaitModels节点
节点功能:该节点作用是从远程仓库下载并加载与 LivePortrait 模块相关的预训练模型,并根据用户设置的精度(precision)和模式(mode)配置,返回一个已经加载的图像生成流水线对象 (LivePortraitPipeline)。
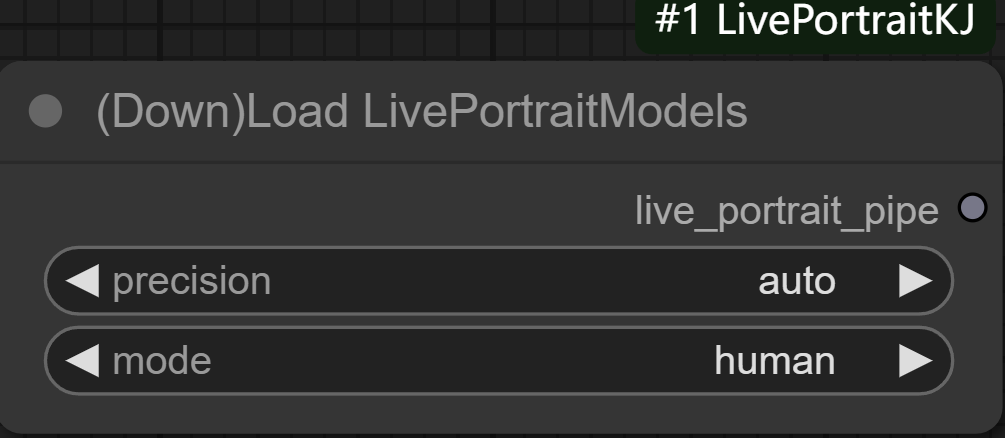
参数:
precision:指定模型推理的精度模式
- auto: 根据硬件和性能需求自动选择精度。
- fp16: 使用半精度浮点数,适合加速推理过程,降低内存占用。
- fp32: 使用单精度浮点数,适合需要更高数值精度的计算。
mode:
- human: 主要针对人的脸部进行检测
- animal: 主要针对动物的脸部进行检测
二、LivePortrait Load MediaPipeCropper节点
节点功能:模型加载以及对裁剪器对象进行初始化。
__
__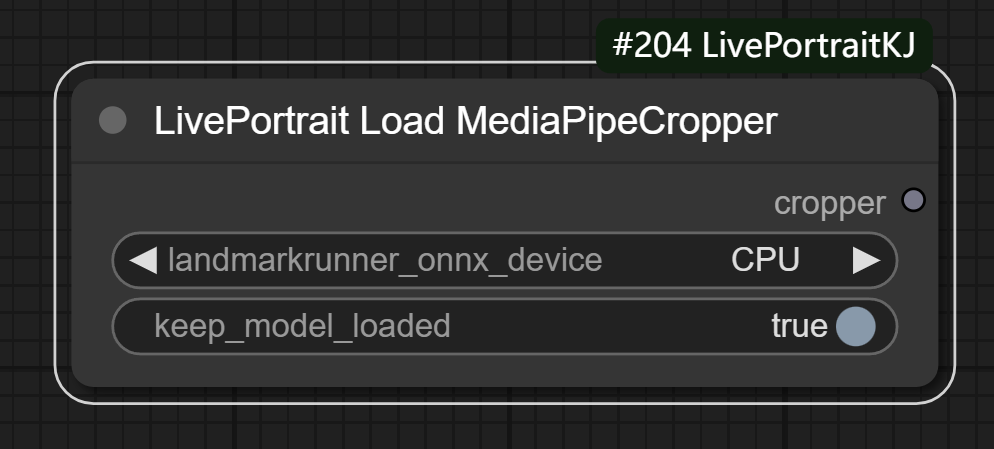
参数:
landmarkrunner_onnx_device: 该输入指定用于推理设备的类型。
- CPU: 使用 CPU 进行计算。
- CUDA: 使用支持 CUDA 的 NVIDIA GPU 进行计算。
- ROCM: 使用 AMD GPU 进行计算。
- CoreML: 使用 Apple 的 CoreML 框架进行计算。
- torch_gpu: 使用 PyTorch GPU 设备进行计算。
keep_model_loaded: 是否保持模型加载状态。默认为 True,表示保持模型在内存中加载,以加快后续推理操作的速度。如果设置为 False,则每次推理时都会重新加载模型。
但事实上,在选择推理设备时,只有torch_gpu会有所区别,其他的都一样。在选择torch_gpu时此处会调用pth模型,选择其他选项时都是调用onnx模型。
三、LivePortrait Load InsightFaceCropper节点
节点功能:和上述节点类似,负责处理面部对齐和裁剪。
__
__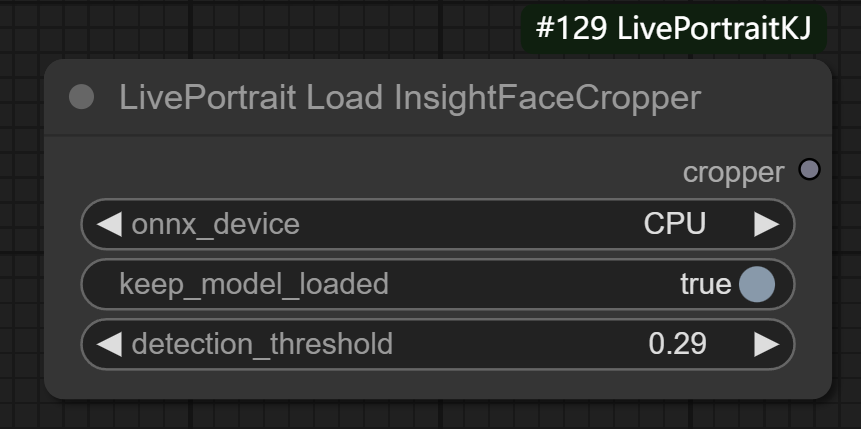
参数:
onnx_device: 设备类型,用于指定模型推理时使用的设备
keep_model_loaded: 是否保持模型加载状态。默认为 True,表示保持模型在内存中加载,以加快后续推理操作的速度。如果设置为 False,则每次推理时都会重新加载模型。
detection_threshold: 面部检测的阈值,浮动值,范围从 0.05 到 1.0,默认为 0.5。该值控制面部检测器的灵敏度。当面部检测的置信度高于该值时,才会认为检测到面部,进行后续的裁剪操作。较低的值可能导致更多的检测结果,但也可能产生误检;较高的值会减少误检,但可能漏掉一些面部。
四、LivePortrait Load FaceAlignmentCropper节点
节点功能:依旧和二、三节点功能类似(对动物脸部检测更加友好,图片中包含多张人脸时也更加友好)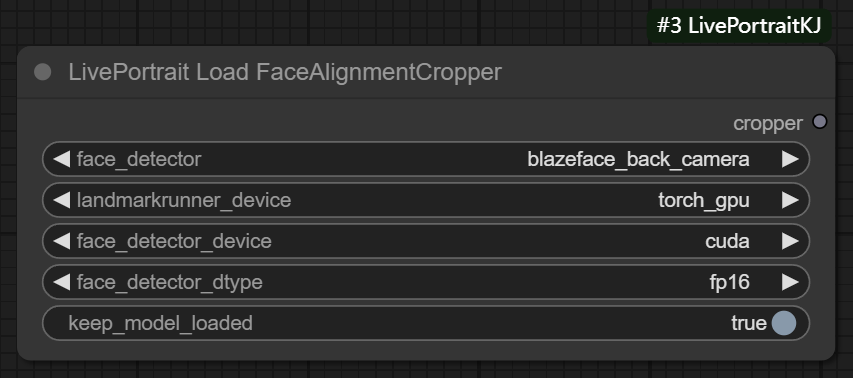
参数:
face_dctceor: 指定的面部检测裁剪器类型
- blazeface back camera: 该模式会调用后置摄像头,因此对于较小的脸部来说,它比 MediaPipe(节点二) 更好。使用此功能时,第一次运行的预热可能需要很长时间,但后续运行很快。
- blazeface: 主要用于移动设备的检测模型。
- sfd: 另一种面部检测模型,可能具有不同的检测能力和速度。
andmarkrunner_onnx_device: 用于人脸关键点检测的设备选择
face_detector_device: 面部检测器的设备选择
face_detector_dtype: 面部检测计算精度
keep_model_loaded: 是否保持模型加载状态。默认为 True,表示保持模型在内存中加载,以加快后续推理操作的速度。如果设置为 False,则每次推理时都会重新加载模型。
五、LivePortrait Cropper节点
节点功能:主要功能是处理面部图像裁剪、面部关键点提取、特征提取和相关处理。它将输入的图像通过裁剪器进行处理,提取图像中的面部区域,并对裁剪后的图像执行进一步的处理操作,包括关键点和特征提取。
__
__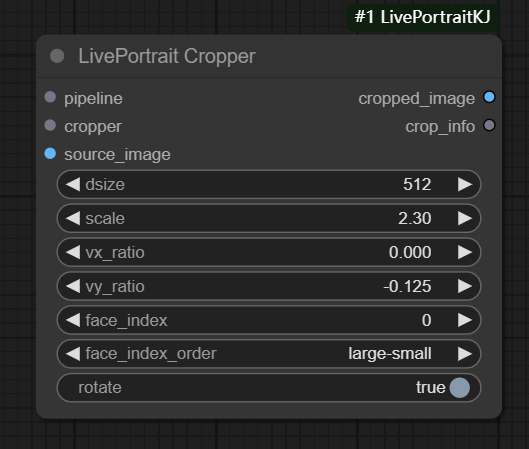
输入:
pipeline: 负责进行进一步的面部处理操作(如面部关键点提取、特征提取等)
cropper: 负责图像裁剪
source_image: 源图像数据
参数:
dsize: 裁剪后图像的大小,默认为 512,范围从 64 到 2048。
scale: 图像缩放比例,默认为 2.3,范围从 1.0 到 4.0。
vx_ratio: 水平位移比例,默认为 0.0,范围从 -1.0 到 1.0。
vy_ratio: 垂直位移比例,默认为 -0.125,范围从 -1.0 到 1.0。
face_index: 用于选择裁剪的面部索引,默认为 0,最大值为 100。
face_index_order: 指定面部索引的排序顺序,支持多种排序方式
- large-small: 从大到小
- left-right: 从左到右
- right-left: 从右到左
- top_bottom: 从上到下
- bottom-top:从下到上
- small-large:从小到大
- distance-from-retarget-face: 根据和驱动脸部的相似度进行排序,越小的排在前面。
rotate: 是否进行旋转操作,一般旋转角度较小。主要调整面部位置,使其保持正确方向(一般是比较直立的方向)
当scale系数为1时,只有脸部信息。
当裁剪图像中只有脸部时,在生成动画的时候也只有脸部细节在动。

当scale系数为1时,图像中包含脸部以外的信息。
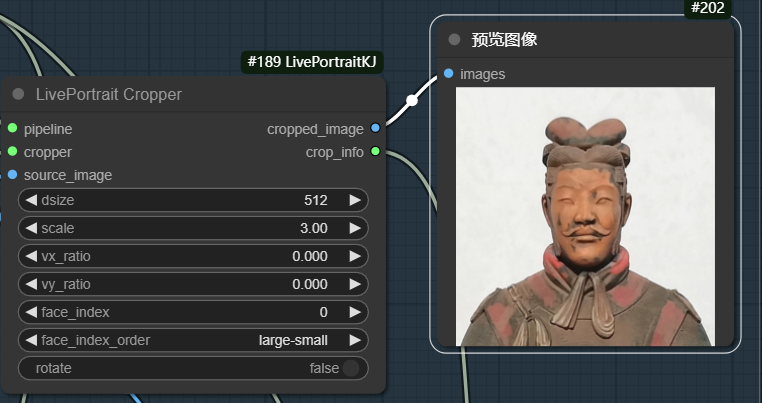
当裁剪图像中包含脸部以外的信息时,生成的动画除脸部外也会动,如下图,动画中肩部也会动。

设置vx_ratio为0.5时,图像整体向左平移0.5*width像素
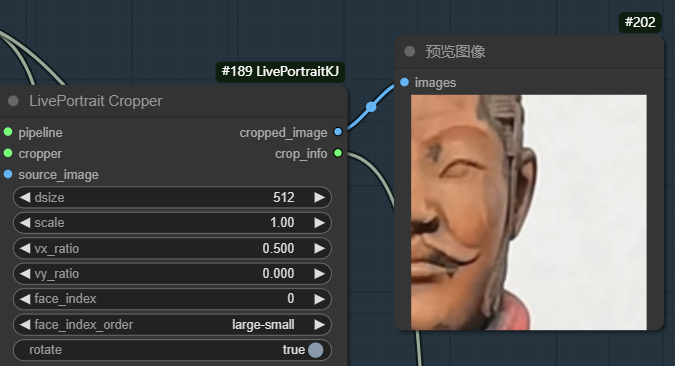
生成的动画中只有检测到的右半部分脸部在动。

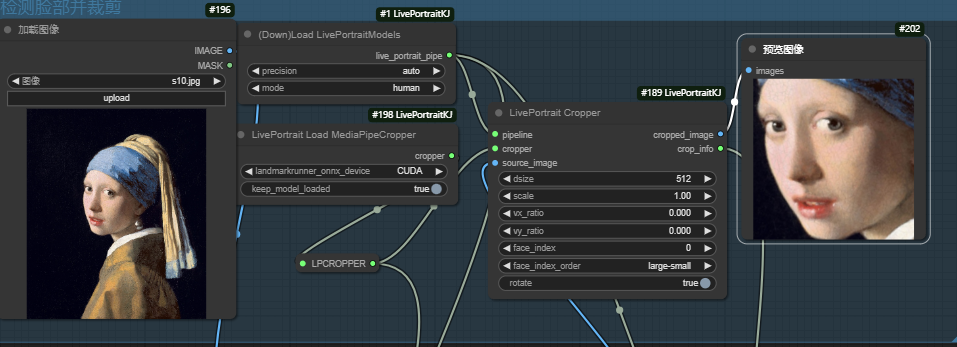
rotate=false,生成图像脸部和原图方向一样
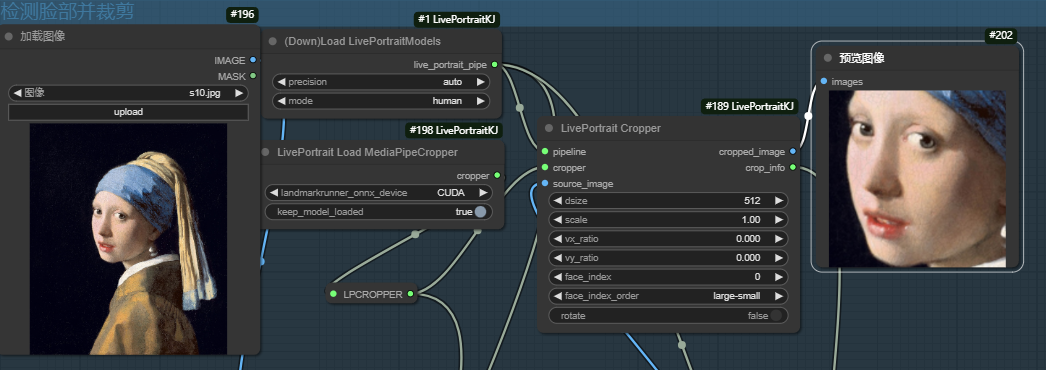
rotate=ture,生成图像脸部调整的更平直。
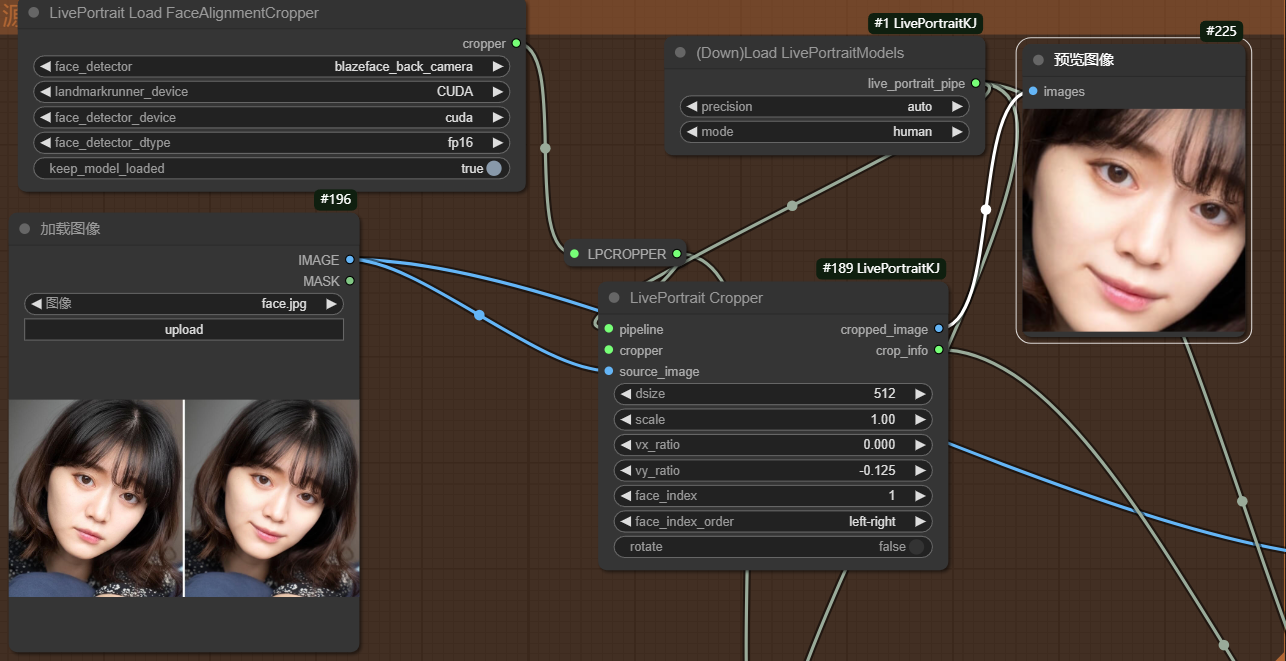
在检测多张人脸时,最好使用__LivePortrait Load FaceAlignmentCropper节点。__如下图,人物中包含两张人脸,当face_index_order选择left-right时,即对检测到的人脸从左到右依次排序,face_index=0代表左边的第一张人脸。
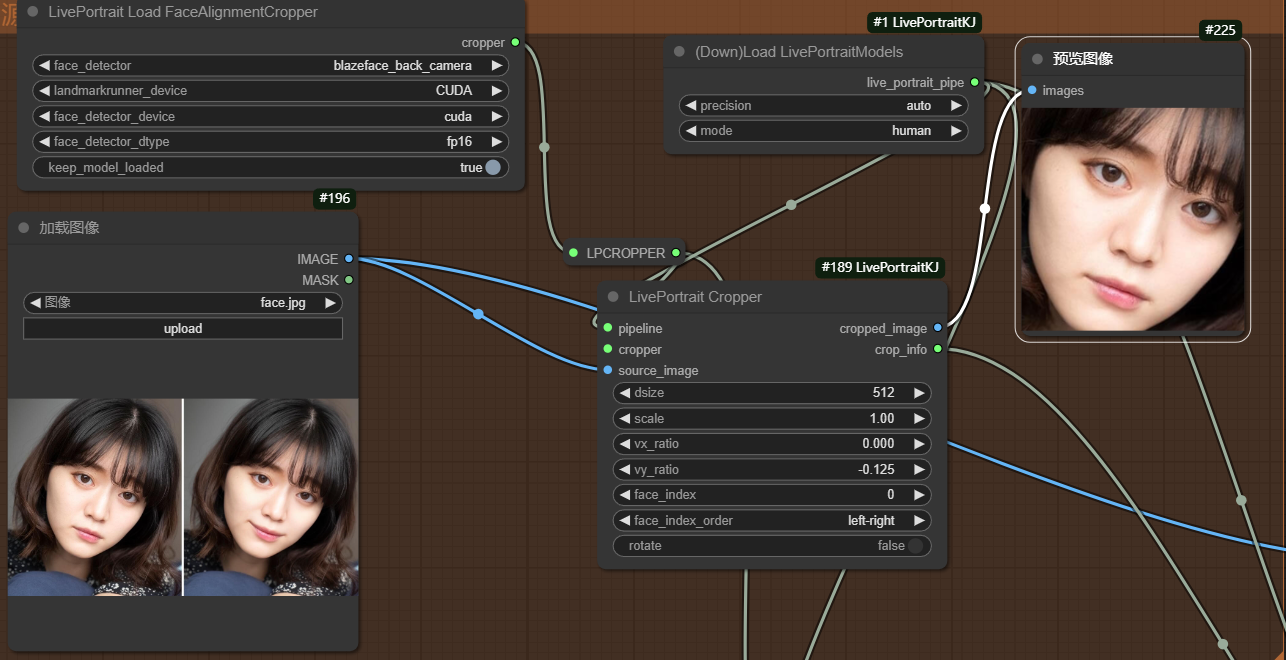
当face_index选择1时,则显示右边人脸。
六、LivePortrait KeypointsToImage节点
节点功能:在处理面部识别或面部特征时,将关键点可视化,以便更好地理解和验证模型的预测结果。
输入:
crop_info: 它包括了面部图像中的关键点数据,用于将这些关键点绘制在图像上。
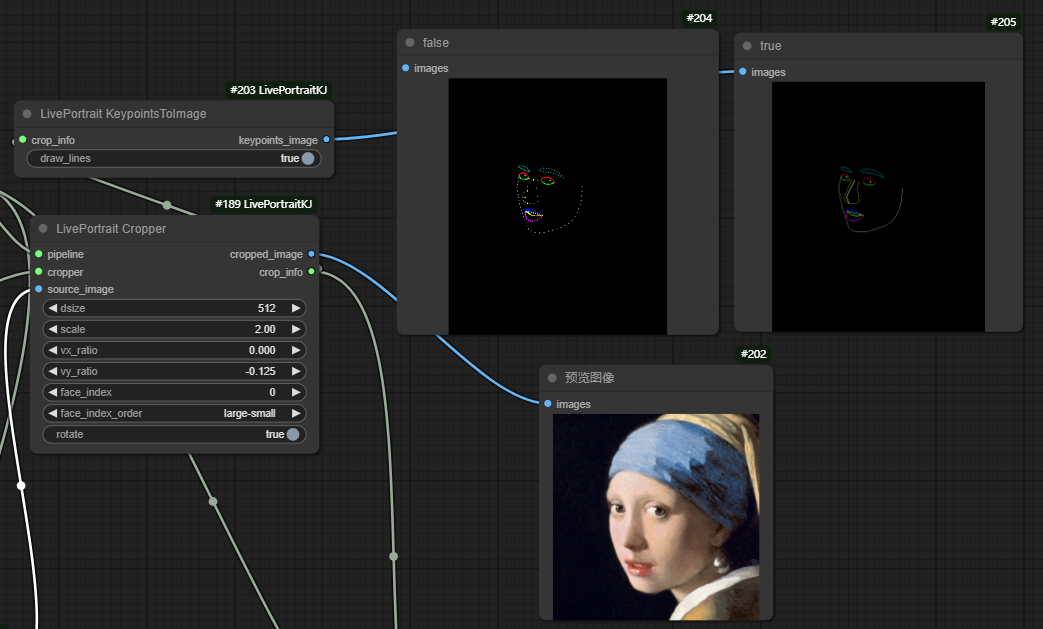
参数:
draw_lines: 控制是否在关键点之间绘制连接线。如果 True,则会连接相邻的关键点;如果 False,则只绘制单独的点。
七、LivePortrait Process节点
节点功能:基于源图像和驱动图像的输入,结合面部关键点和其他配置信息,生成经过面部驱动动画处理后的图像。这种处理广泛应用于人脸动画、表情迁移、以及动态面部表情合成等任务。
__
__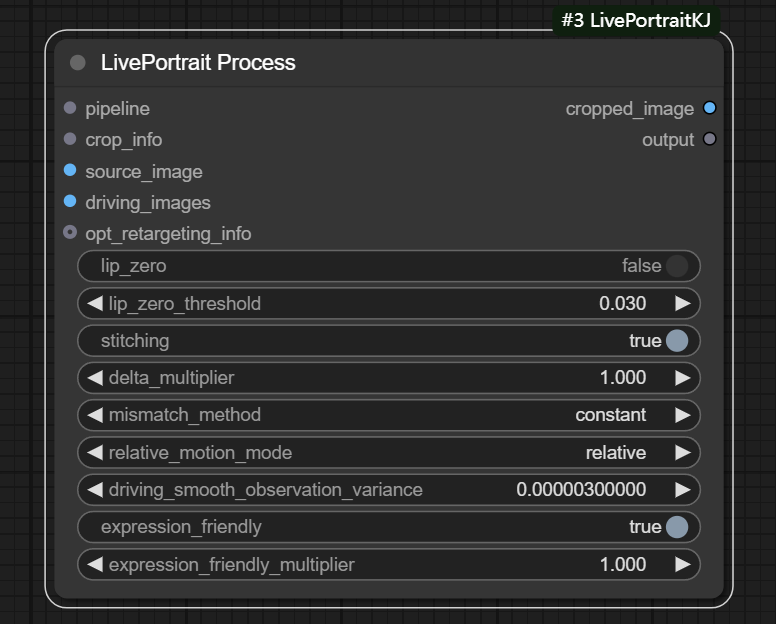
输入:
pipeline: 整个面部动画处理管道。
crop_info: 包含裁剪信息,通常是面部的关键点数据。
source_image: 源图像
driving_images: 驱动图像,表示源图像的表情或动作的来源,通常是驱动源图像表情或动作的目标图像。
opt_retargeting_info:可选择的重定位信息(通常是修改嘴巴或眼睛是否闭合),与LivePortrait Retargeting节点一起使用。(可选)
参数:
lip_zero: 控制是否禁用嘴唇的运动。
lip_zero_threshold: 控制嘴唇运动禁用的阈值。
stitching: 制是否启用拼接效果,通常用于合成多个区域或视角时保持一致性。
delta_multiplier: 应用于表情变化的比例因子。系数越大,表情变化越明显,容易崩,负数也是一样,负的越多,表情变化越明显。
mismatch_method: 控制处理过程中如何处理不匹配区域的方式
- constant: 使用常量填充不匹配区域,通常是黑色或其他指定的颜色值(如白色或透明)。
- cycle: 循环使用图像中的像素,通常会将不匹配区域从图像的另一部分(例如,边缘)循环填充过来。
- mirror: 将不匹配区域的像素进行镜像反转填充,即将图像的某部分(例如,边缘或对称的区域)进行镜像映射到不匹配区域。
- cut: 直接切割掉不匹配的部分,只保留有效的图像区域。这意味着不匹配区域会被剪裁掉,可能会造成一些部分的缺失。(在输入源是视频的时候,使用该方法时可以的)
relative_motion_mode: 控制运动模式
- relative: 源图像面部(包括表情和比例)会根据驱动面部的相对运动进行变化(平移,旋转)。
- relative_rotation_only: 源图像面部(包括表情和比例)只有旋转的时候会根据驱动面部的相对运动进行变化。
- source_video_smoothed: 主要针对输入源也是视频,通过对源视频中的运动进行平滑化,减少或去除源视频中可能存在的抖动、噪声或不自然的变化,以便获得更平滑、自然的输出效果。
- single_frame: 使用单帧进行变换,主要用于生成单张的转绘图片。
- off: 禁用运动变换,源图像面部不跟随驱动面部进行旋转或平移。
driving_smooth_observation_variance: 该参数需要和source_video_smoothed模式一起使用,控制对驱动面部的旋转和表情数据应用多少平滑处理。值越大,平滑度越高,使面部动画过渡更加渐进、更不突然。值越低,平滑度越弱,从而使得帧之间出现更直接、更不平滑的过渡。
expression_friendly: 控制动画是否应优先考虑表情流畅度或真实感。如果设置为True,算法将相应地修改动画。如果False,面部表情可能会产生不连贯的动作,而不会对表情进行平滑调整。(只适用于处理输入源是单张图片而不是视频源)
expression_friendly_multiplier: 与delta_multiplier类似,系数大了表情容易崩坏。

当lip_zero设置为false, 对原图嘴巴的初始状态控制没有变化。
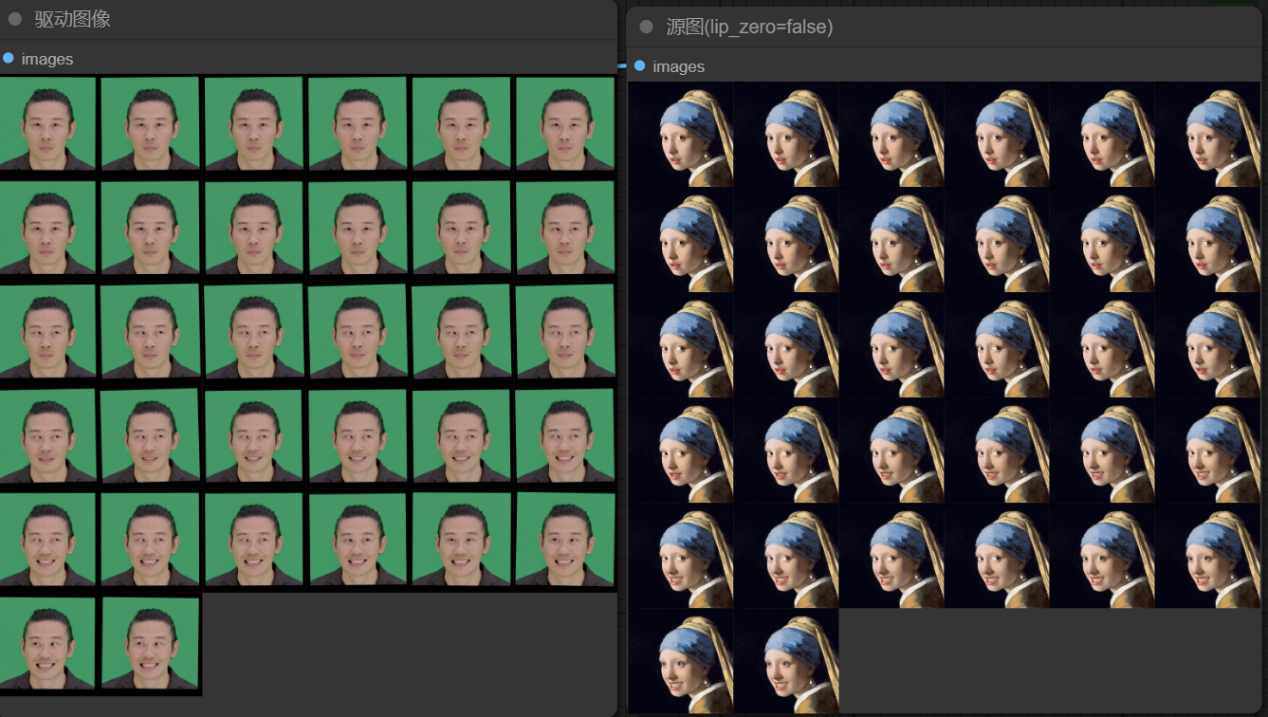
当lip_zero设置为True,lip_zero_threshold为0.03,图像中前几帧嘴巴几乎是闭合的,控制在阈值内变化,最终图相比上面嘴巴的张开缩小了些。
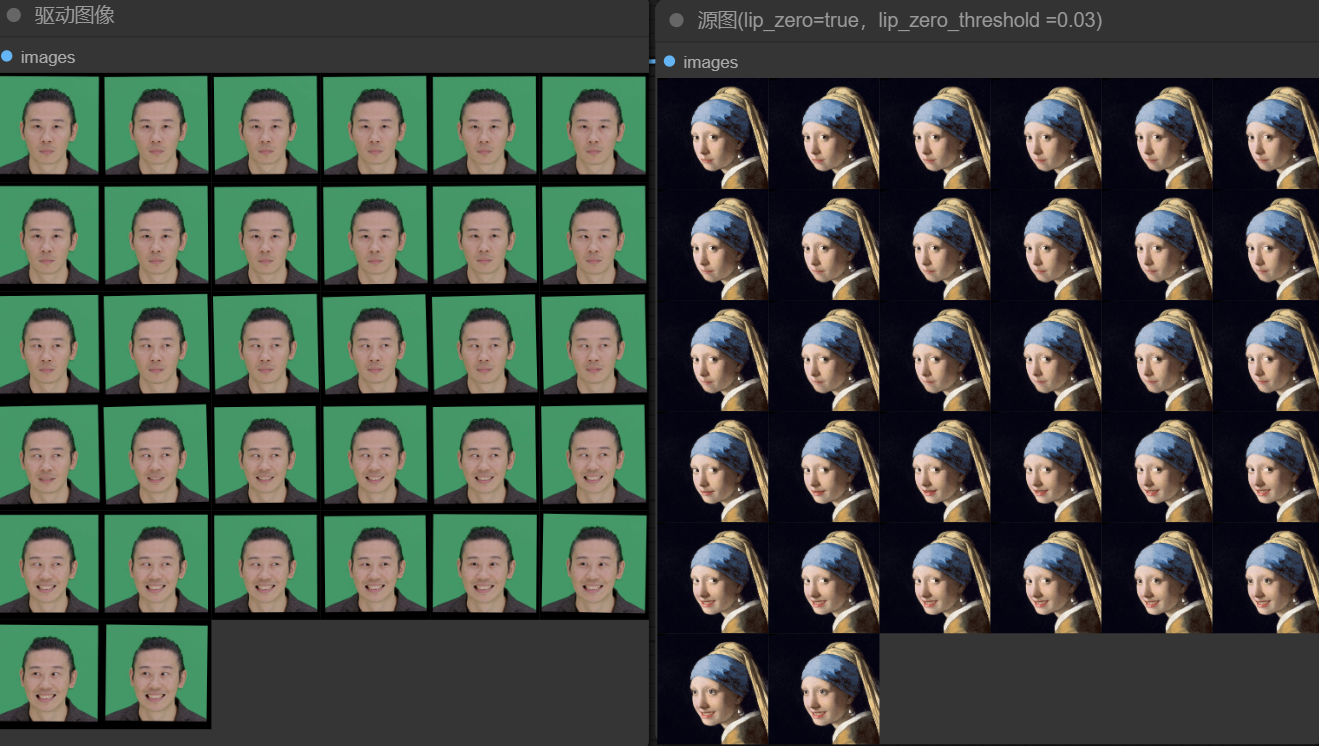
当lip_zero设置为True,lip_zero_threshold为2,图像中的嘴巴变化幅度又比0.03时更大。
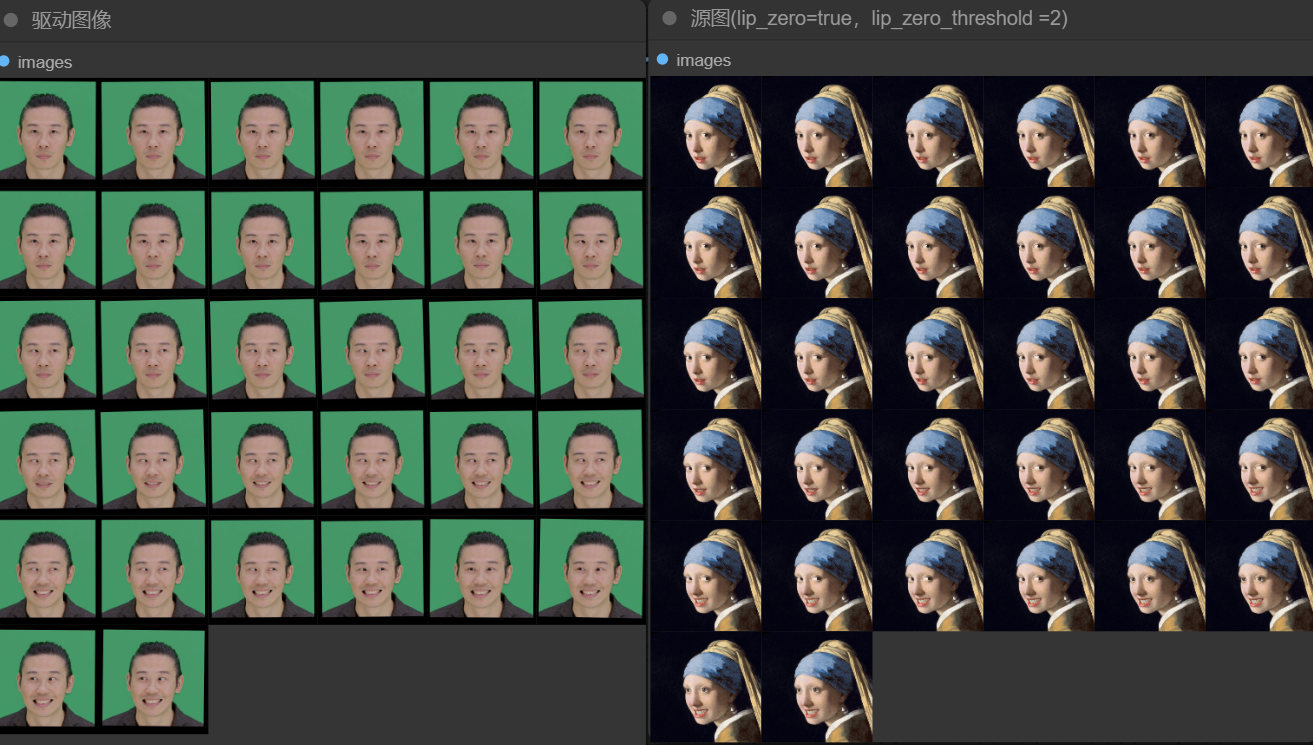
当设置不同的delta_multiplier值时,人物表情的变化如下图,可以看到,当delta_multiplier值设置过大时,人物表情是崩坏的。
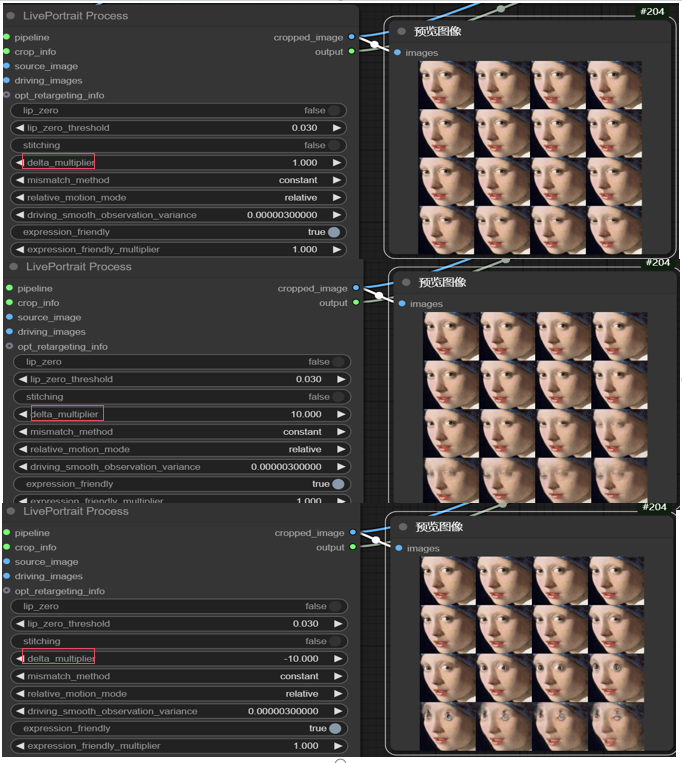
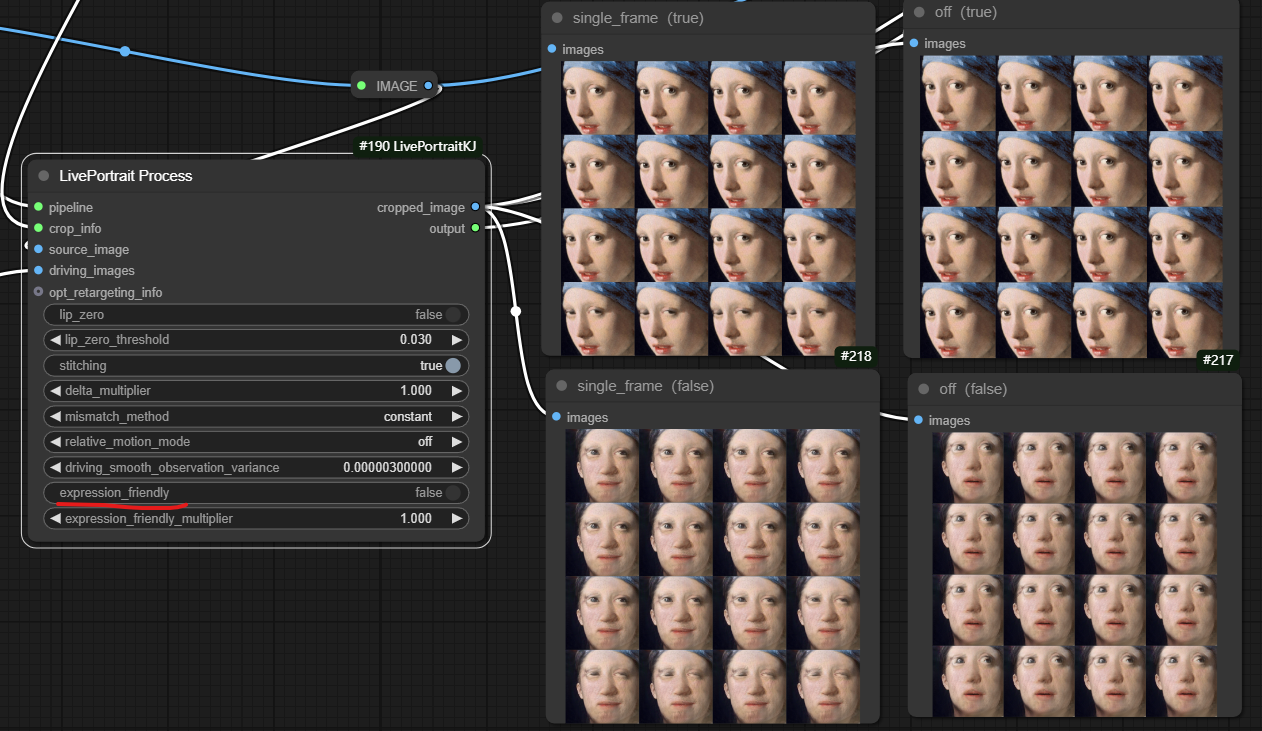
在选择mismatch_method中方法时,constant,cycle,mirror方法目测差距不大,输入源为单张图片时,在使用cut方法时,cropped_image只会输出单帧图片。如下图,在使用constant方法时,cropped_image输出为16帧(帧数与驱动视频帧相关,当然也可以手动设置帧数)图片,而cut方法只有单帧图片,这会导致生成动画中人物表情不会有变化。
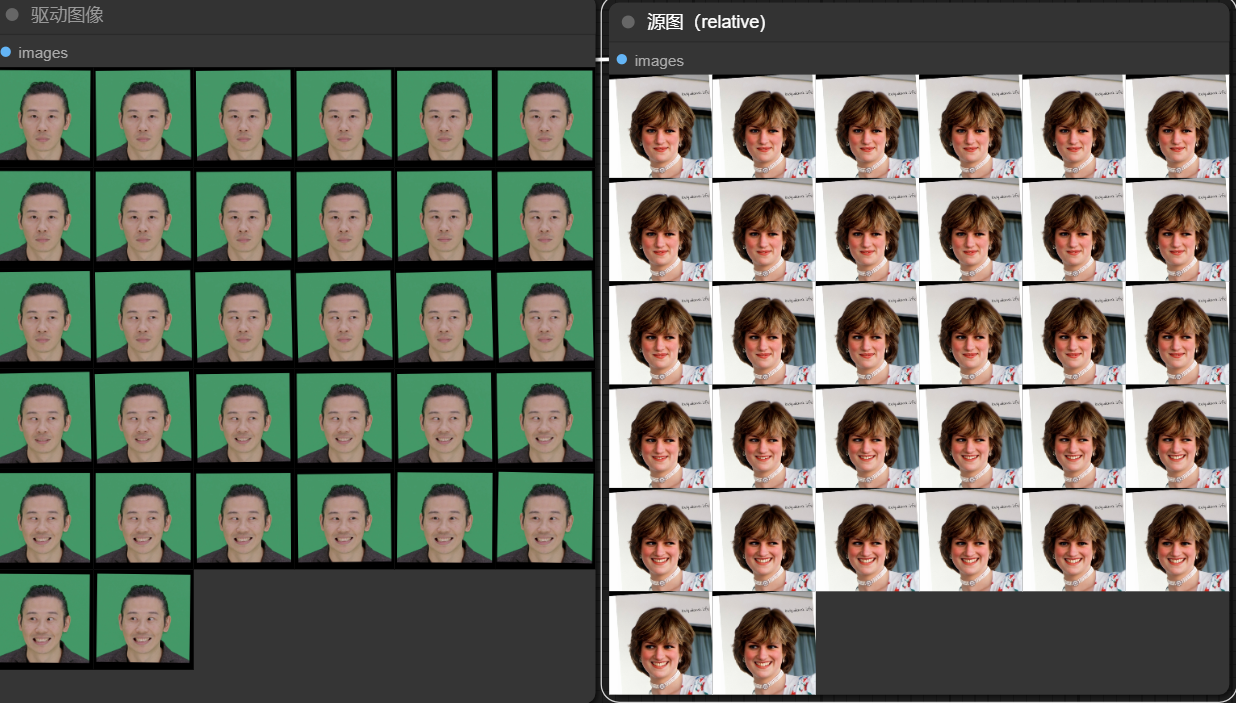
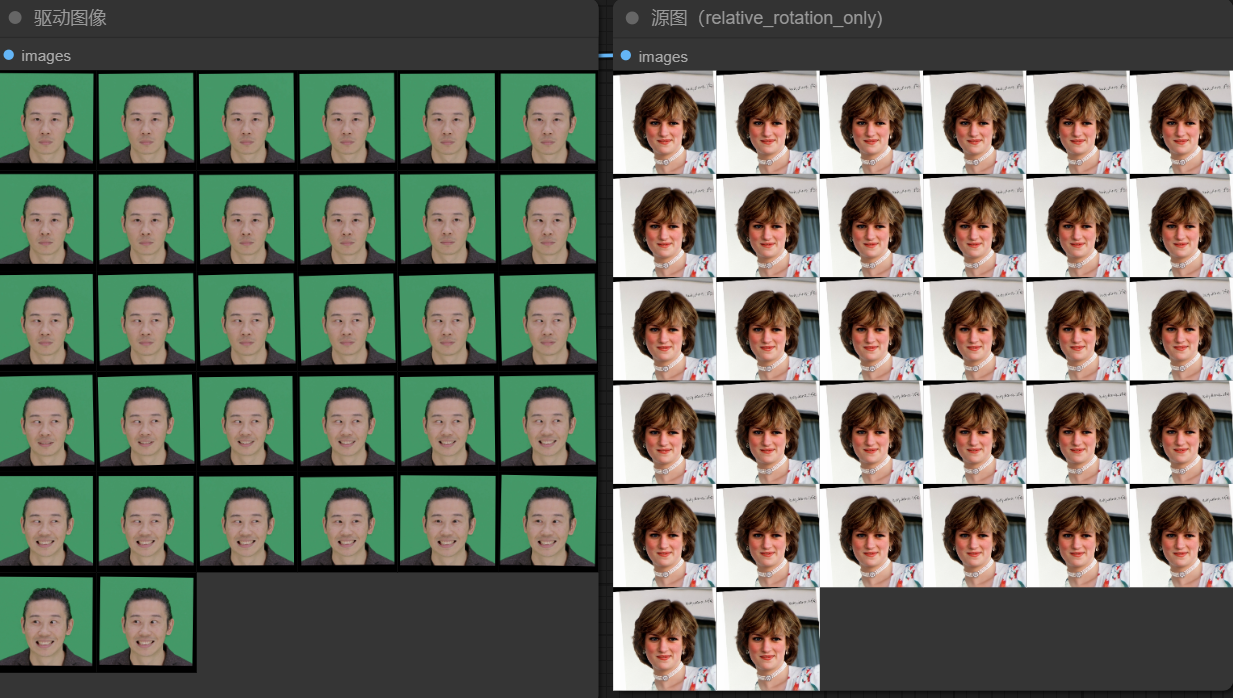
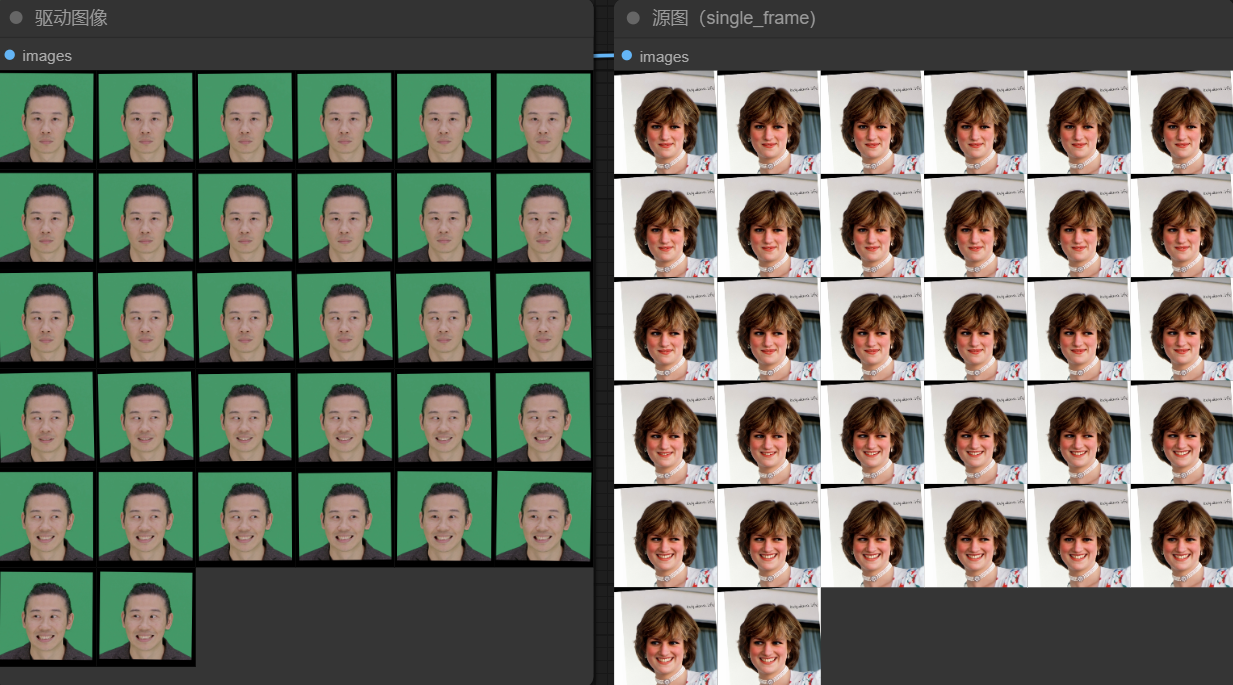
当设置relative_motion_mode=relative,人物表情的运动会随着驱动视频中人物表情运动。如下图,可以看到,relative和single_frame模式随着驱动人物眼睛闭合源图也会逐渐闭合。而relative_rotation_only和off模式表情并没有什么变化。
relative模式
relative_rotation_only模式
single_frame模式
off模式
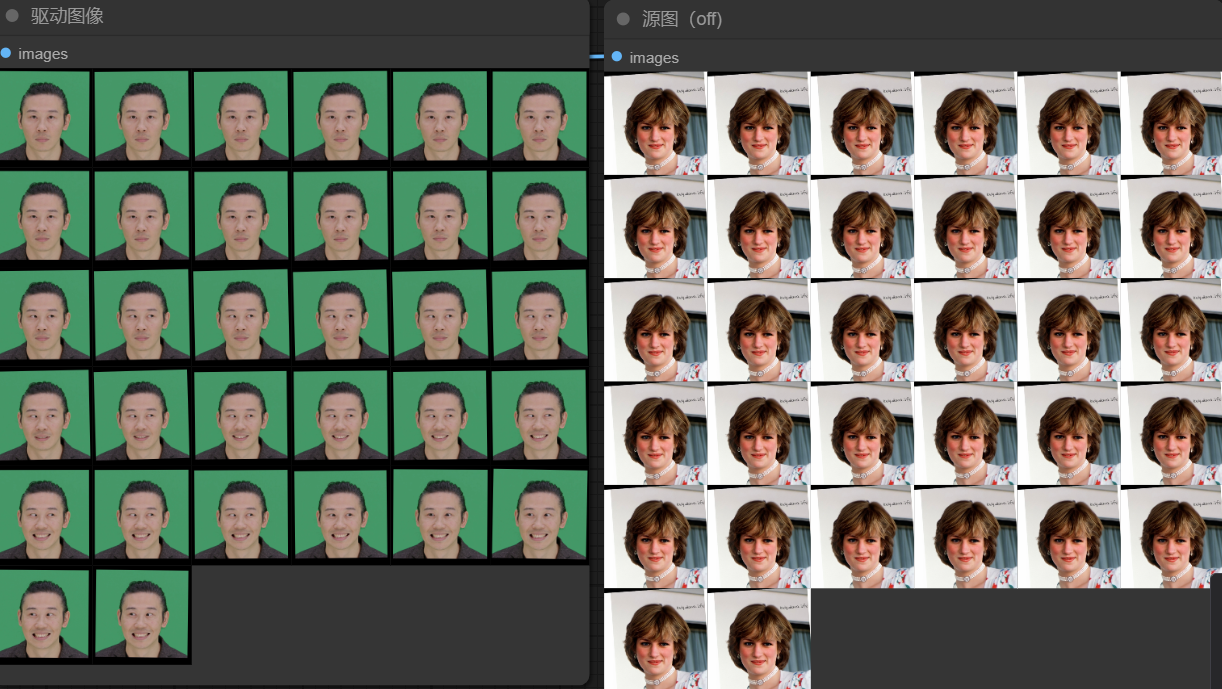
需要注意的是,在使用single_frame模式和off模式时,expression_friendly许设置为true,否则图像会比较崩。
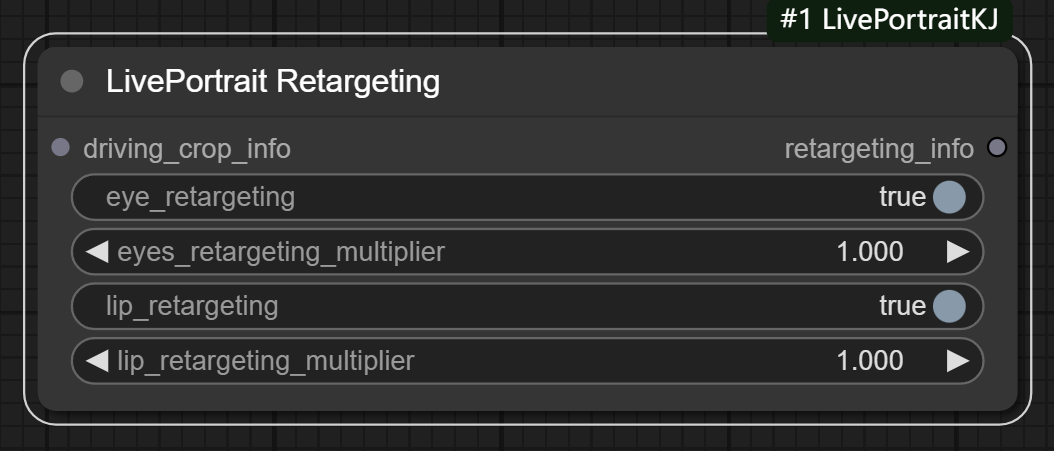
八、LivePortrait Retargeting节点
节点功能:主要功能是处理面部特征的重定向(retargeting),尤其是眼睛和嘴唇的目标面部特征。它基于输入的驱动面部图像和特定的重定向选项,生成相应的重定向信息。(主要控制眼睛和嘴巴运动状态)
__
__
输入:
driving_crop_info: 驱动图像的裁剪信息(通常包括驱动图像的面部特征点和相关的裁剪区域)。它是一个包含多个图像裁剪信息的列表
参数:
eye_retargeting: 控制是否进行眼睛重定向。如果为 True,则表示驱动面部的眼睛特征将被应用到目标面部。
eyes_retargeting_multiplier: 控制眼睛重定向的强度。值越大,眼睛的重定向效果越明显。
lip_retargeting: 控制是否进行嘴唇重定向。如果为 True,则表示驱动面部的嘴唇特征将被应用到目标面部。
lip_retargeting_multiplier: 控制嘴唇重定向的强度。值越大,嘴唇的重定向效果越明显。
当eye_retargeting为true,源图会跟随驱动图像的眼睛变化而变化。
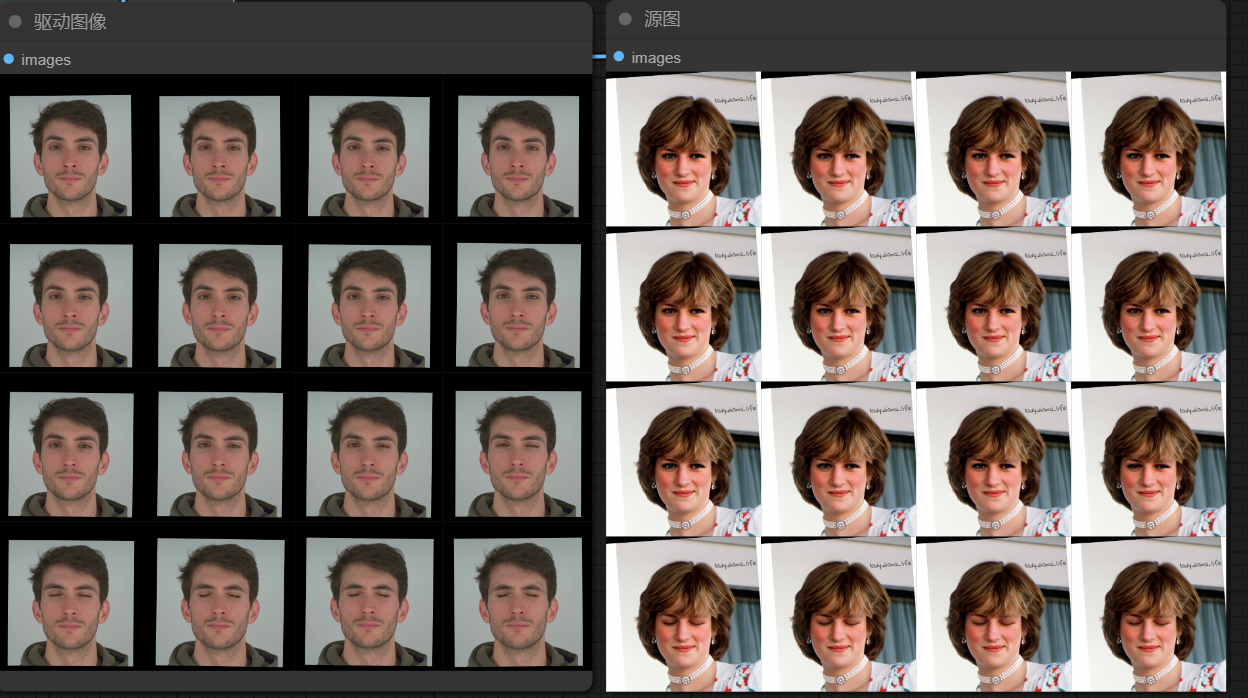
当lip_retargeting为true,源图会跟随驱动图像的嘴巴变化而变化。__
__
注意:当设置lip_retargeting为false时,无论LivePortrait Process节点中设置lip-zero为true还是false,源图都不会跟随驱动图像的嘴巴变化而变化。
九、LivePortrait Composite节点
节点功能:主要功能是将裁剪后的面部图像与源图像进行融合,生成完整的合成图像,并根据需要应用掩模。它主要用于在面部驱动和面部特征迁移等任务中,合成目标面部和源面部特征,以便生成最终的图像输出。该操作通常在实时图像生成和视频处理任务中使用。
输入:
source_image: 源图像
cropped_image: 裁剪后的图像
liveportrait_out: 输入由LivePortrait Process节点处理后的输出,其中包含转换后的图像帧、裁剪数据(crop_info)以及(mismatch_method)
mask: (可选)这是一个可选的掩模图像,用于指定哪些部分应该被融合。如果未提供,使用默认的掩模模板。
输出:
full_images:输出合成后的完整图像。这些图像是将裁剪后的脸部图像合成到源图像上之后的结果。该输出是按帧合成的
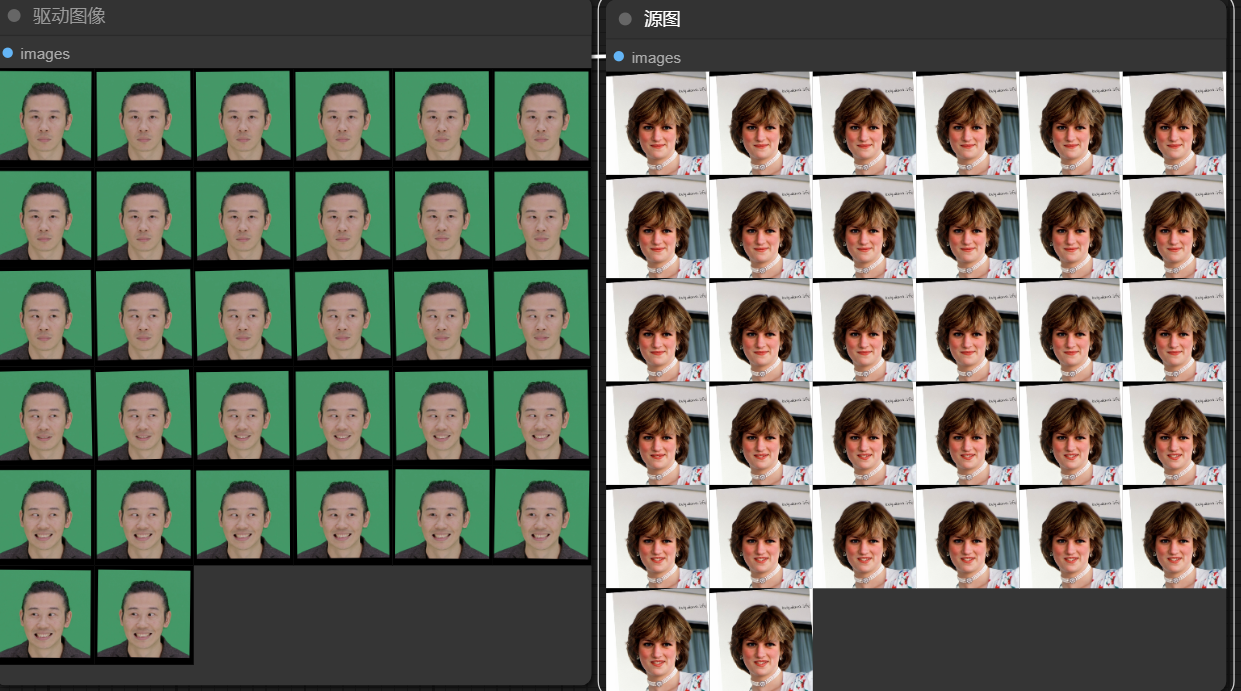
如下图,人脸部分图像恢复到原始图像上
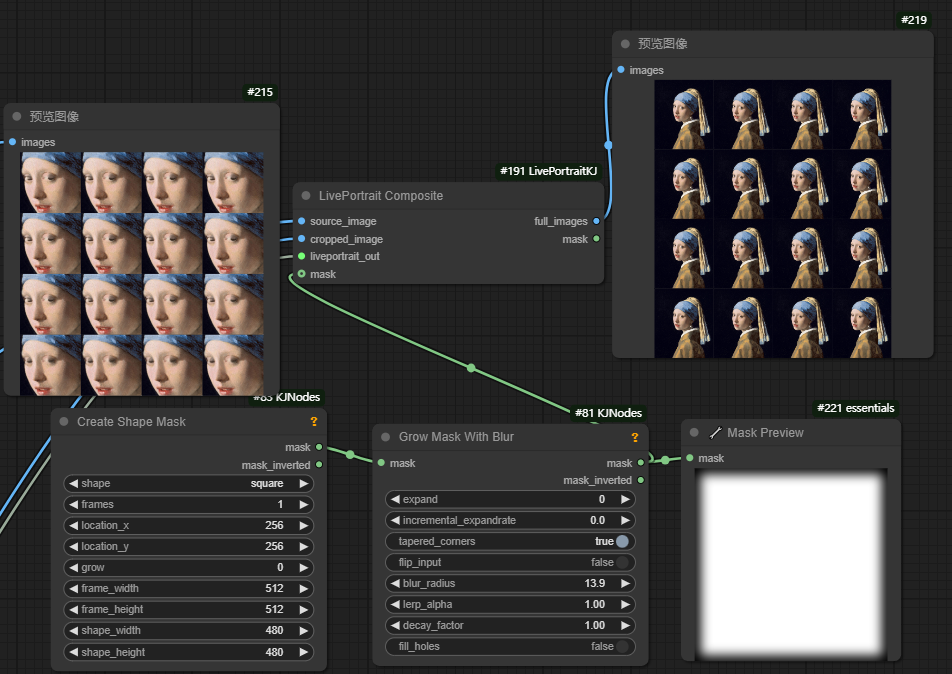
在LivePortrait Composite节点中输入项还有个mask输入,如果不使用自己创建的mask,该节点会加载该插件中自带的mask。在该插件的resource文件夹中。
如果要使用自己创建mask,最好对mask进行模糊处理,因为模糊蒙版可以去除图像中产生的尖锐边界,在图像的特定区域应用效果时,使得过渡更自然。左边是使用了模糊处理蒙版生成的图像,右边则是没有模糊处理。可以考到,在人物的嘴巴部分右图有些不衔接。

十、默认实例工作流
该工作流位置插件对应的custom_nodes\ComfyUI-LivePortraitKJ\examples目录中
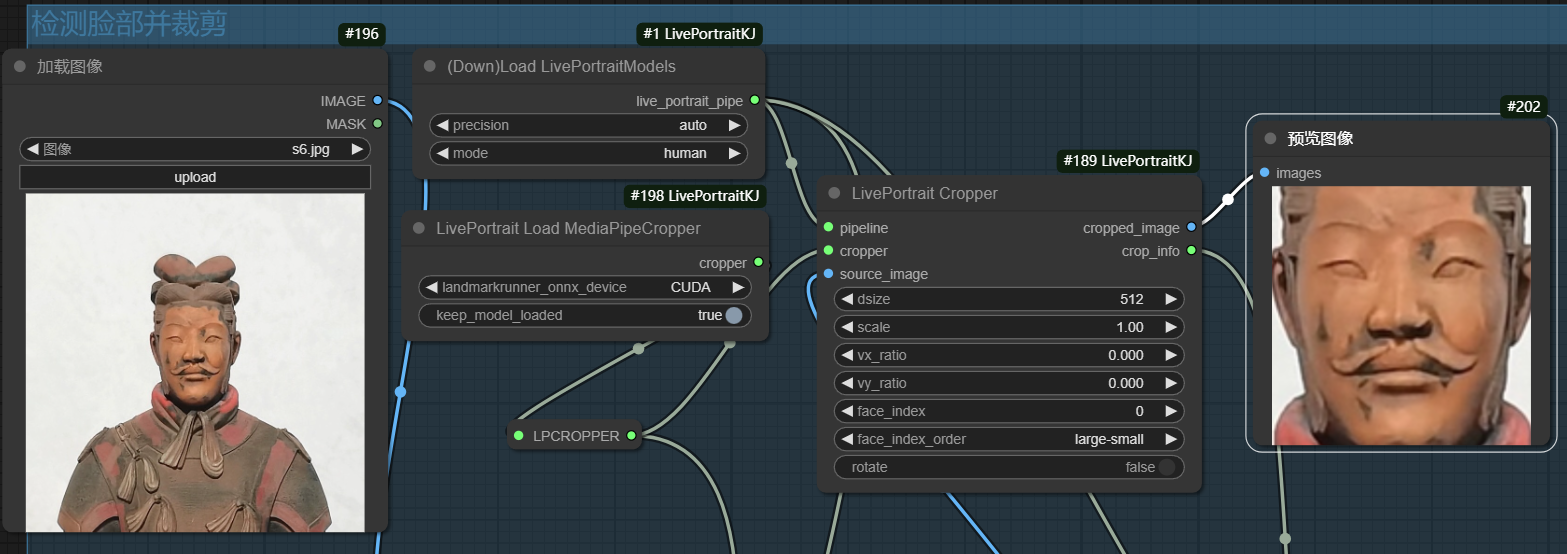
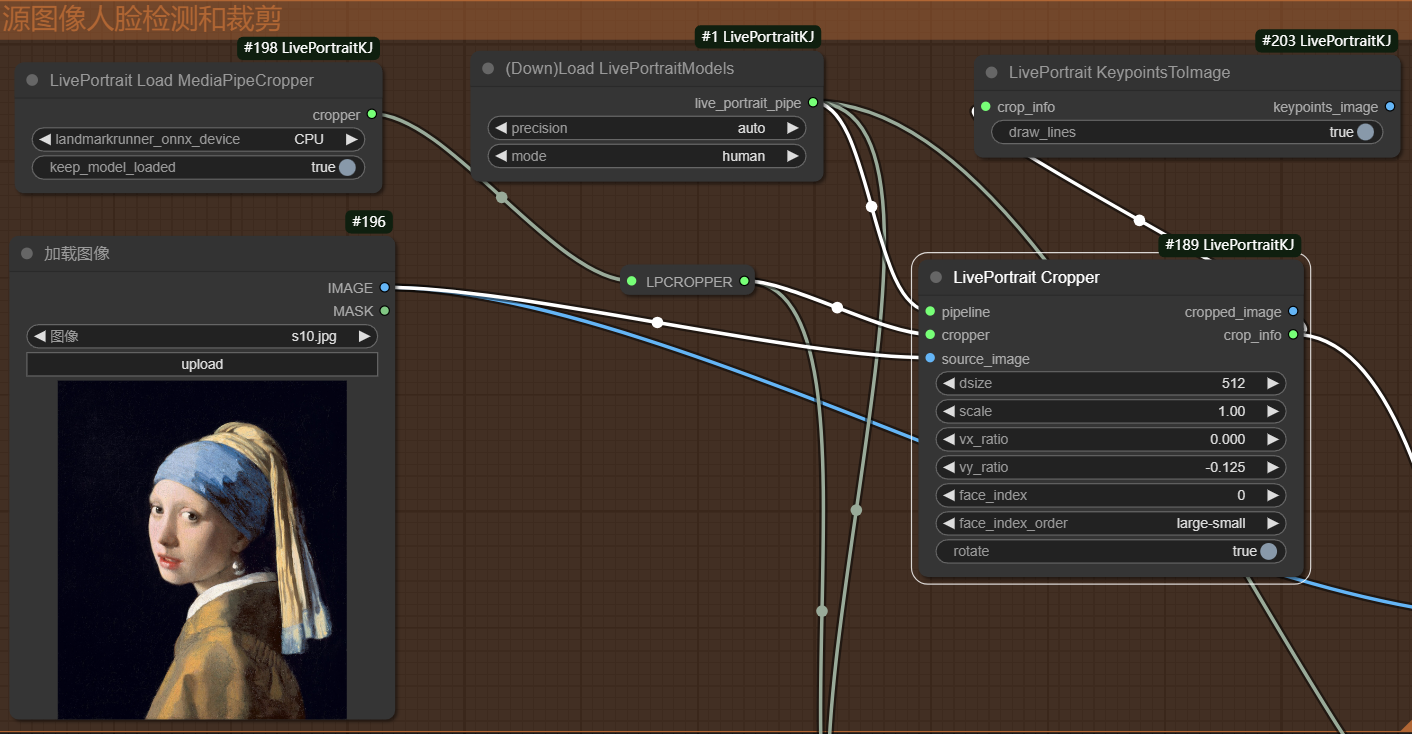
首先自动加载默认的检测模型对上传的图像中人物脸部进行检测,然后对脸部进行裁剪,输出裁剪图片以及相应的裁剪信息(关键点坐标等)。
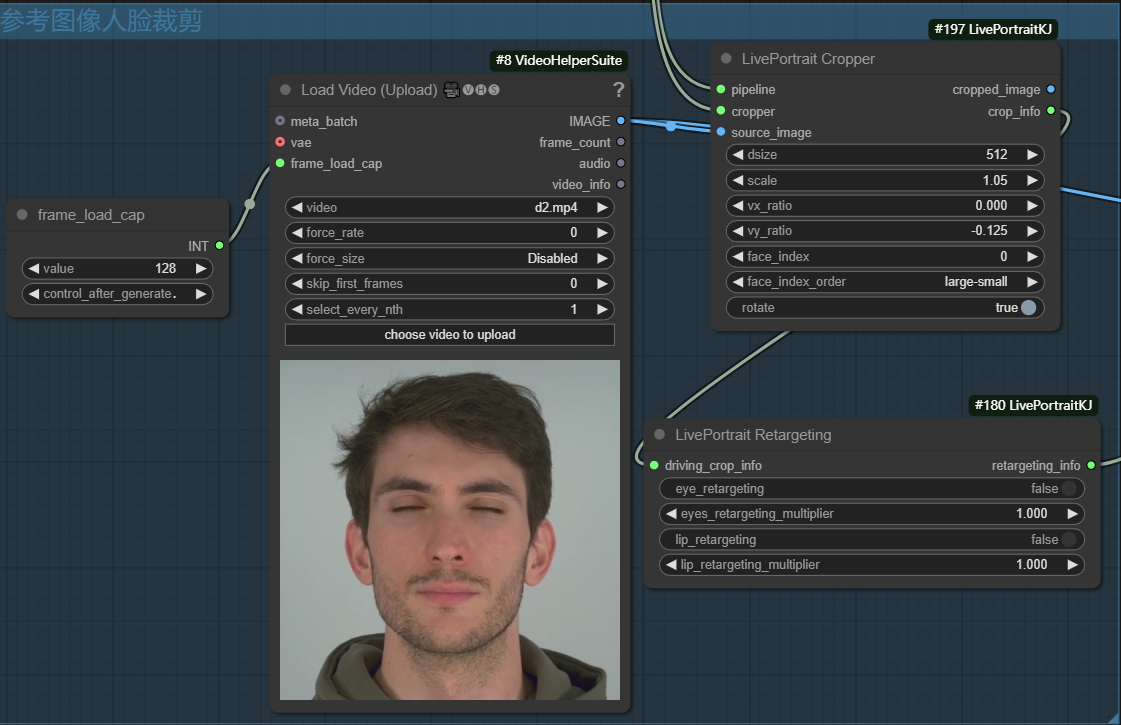
其次要对上传的视频也进行逐帧人脸裁剪,输出相应的裁剪帧图片以及相应的裁剪信息。当然在fram_load_cap中可以自己设置帧数输出,如果视频帧小于该value,则取视频帧的帧数,若视频帧大于设置的value值,则帧数取该value值大小。
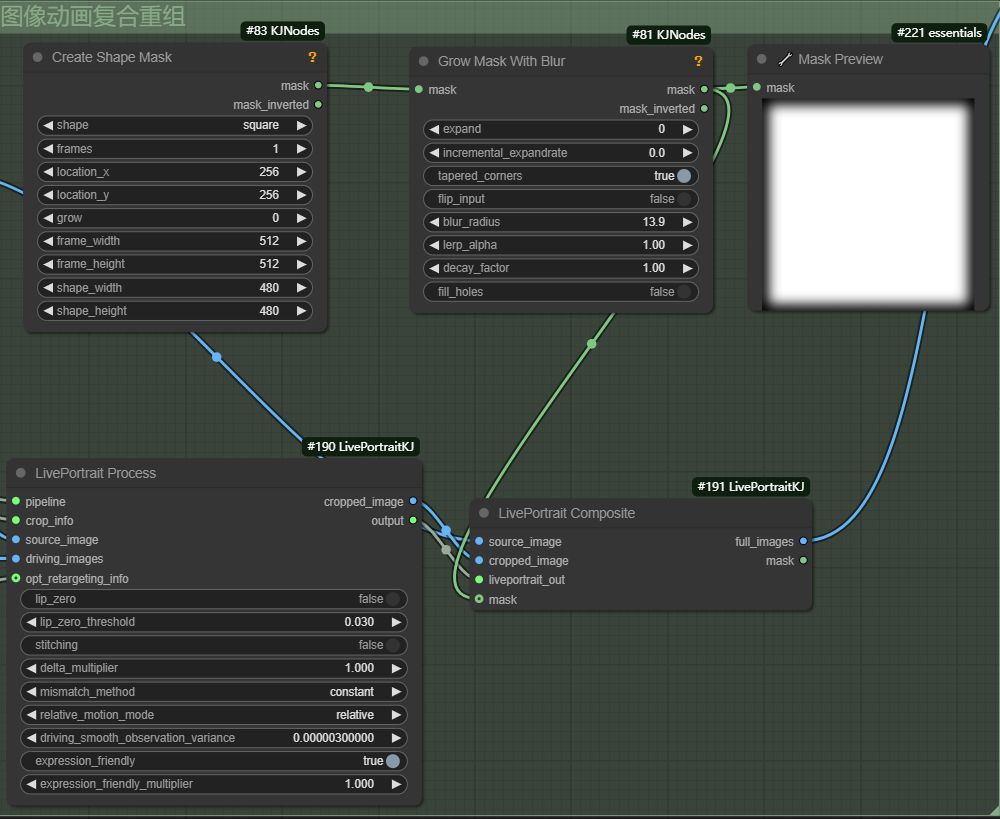
最终源图表情变化随着驱动图像的变化而变化的裁剪图片与源图像进行融合,还原到原来的位置。并引入mask指定哪些部分应该被融合。
最终的效果图。