【ComfyUI插件】ComfyUI Essentials插件(四)
前言:
该插件由cubiq大佬进行开发出来的(这个大佬也是Ipadapter和InstandID和Pulid的Comfyui插件的开发作者),此插件主要在图片处理、蒙版处理、采样器、文本编码器等多个方面提供了辅助节点帮助我们更好解决一些问题。(本节中主要是针对蒙版mask的处理操作,Ksampler 操作以及数学计算节点)
目录
先行:安装方法
一、Transition Mask节点
二、Mask Batch节点
三、Mask Expand Batch节点
四、Mask From Batch节点
五、Ksampler Stochastic Variations节点
六、Inject Latent Noise节点
七、Batch Count节点
八、Ksampler Variations with Noise Injection节点
九、Load CLIPSeg Models/Apply CLIPSeg节点
十、Display Any节点
十一、Draw Text节点
十二、Simple Math/Simple Math Int/Simple Math Float节点
十三、Simple Comparision节点
__ComfyUI Essentials插件(一): __https://articles.zsxq.com/essentials/1.html
__ComfyUI Essentials插件(二): __https://articles.zsxq.com/essentials/2.html
__ComfyUI Essentials插件(三): __https://articles.zsxq.com/essentials/3.html
__ComfyUI Essentials插件(五): __https://articles.zsxq.com/essentials/5.html
__ComfyUI Essentials插件(六): __https://articles.zsxq.com/essentials/6.html
本期使用的示例工作流在网盘:小黄瓜知识星球资料分享/插件节点讲解视频/Essentials/第四期文件夹中。
安装方法
安装方法,一共有2种
1、在manager里搜索ComfyUI Essentials,然后点击安装第一个即可
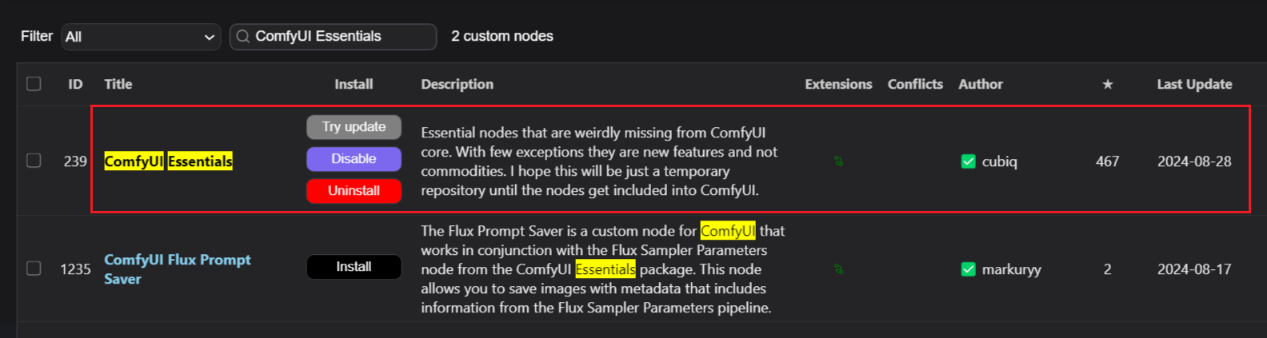
__2、在custom_nodes目录下调用cmd,然后输入git clone __https://github.com/cubiq/ComfyUI_essentials.git

项目地址:https://github.com/cubiq/ComfyUI_essentials.git
一、Transition Mask节点
节点功能:该节点的功能是生成一组用于图像或视频处理的过渡掩码(masks),这些掩码随着时间变化,按照指定的过渡类型和缓动函数,从一种状态平滑过渡到另一种状态。主要用于制作动态遮罩效果,例如滑动、渐变或门样式的打开与关闭。
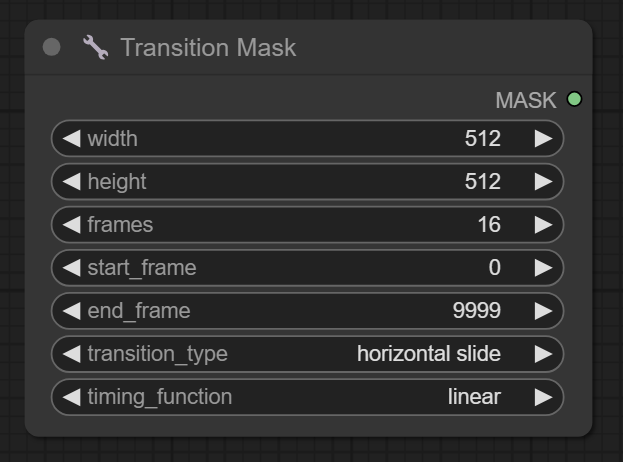
参数:
width -> 生成目标蒙版的宽度
height -> 生成目标蒙版的高度
frames -> 生成过渡蒙版的数量
start_frame -> 开始生成过渡蒙版的起始帧数,也就是从第起始帧数+1张图片开始生成过渡蒙版,默认为0,即第一张
end_frame -> 结束生成过渡蒙版的结束帧数,也就是从第几张图片结束生成过渡蒙版,默认9999,如果end_frame小于frames,第end_frame即end_frame张后的图片都为白色蒙版
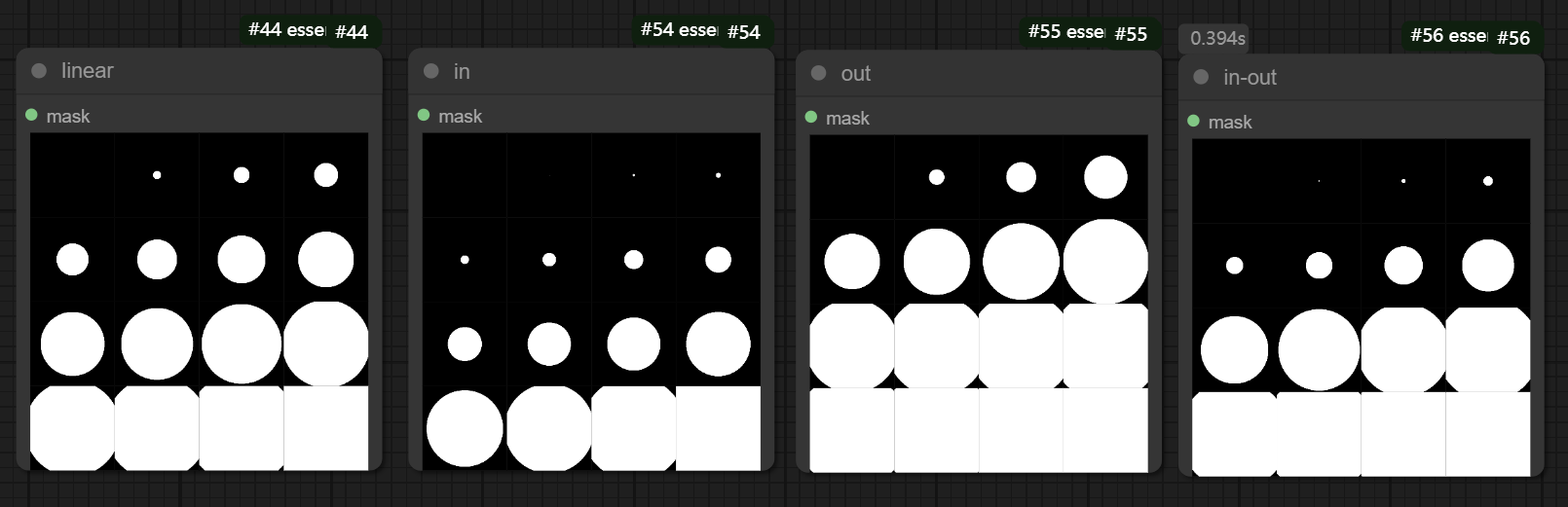
transition_type -> 影响生成过渡蒙版的方式,分为horizontal slide,vertical slide, horizontal bar,vertical bar,center box,horizontal door,vertical door,circle,fade,选择合适方式即可
timing_function -> 影响生成过渡蒙版的形状,分为linear,in,out,in-out,按需选择即可
输出:
MASK -> 生成的过渡蒙版

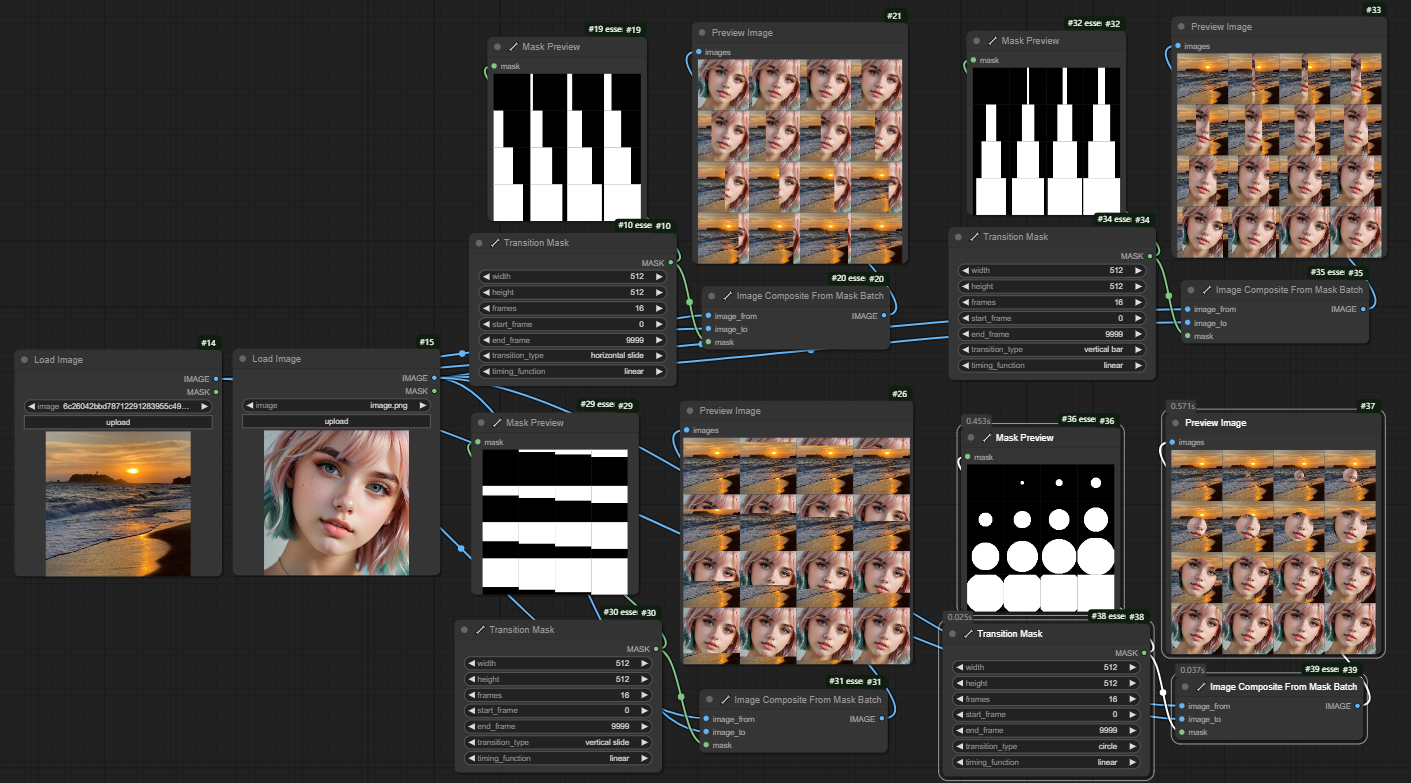
如下图所示,加载的图片会按照mask的形状进行过渡,类似于PPT里切换幻灯片特效一样。
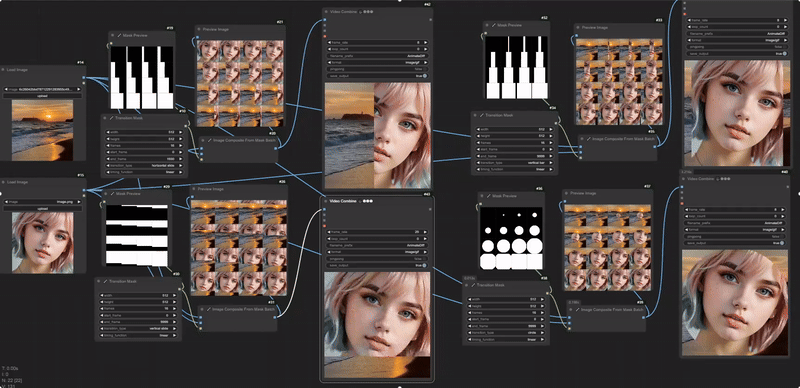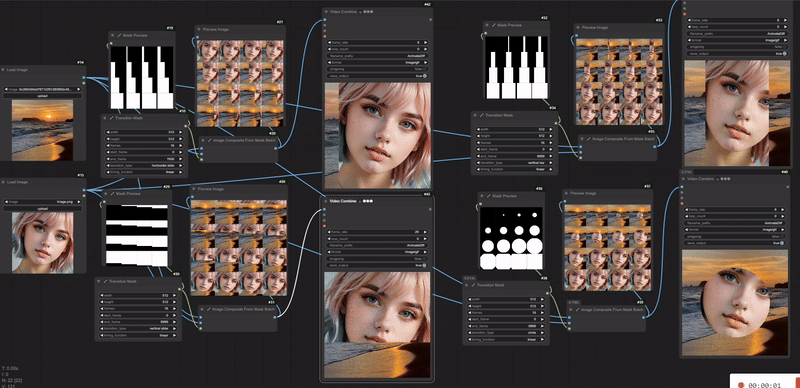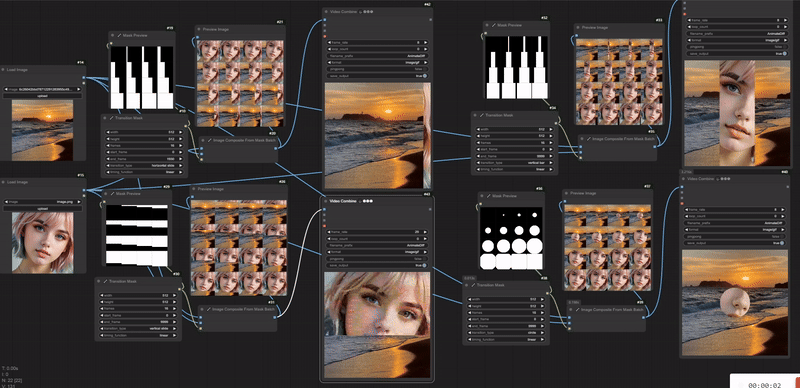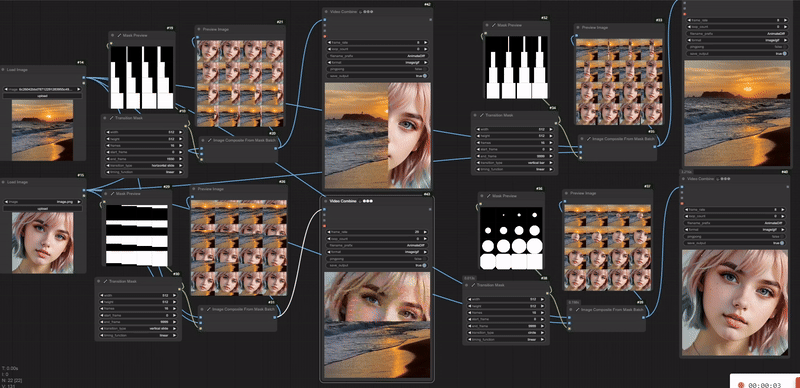
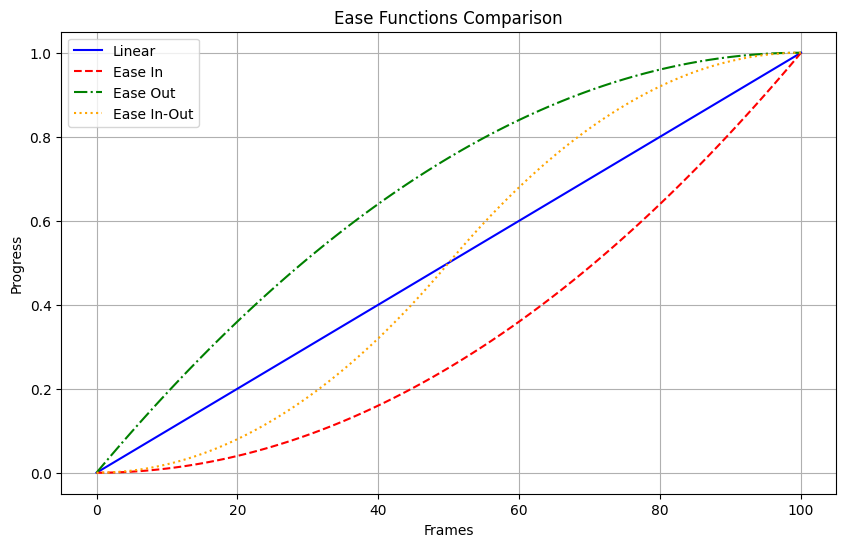
以下是__timing_function__模式下 ,mask过渡的区别。可以看出,__linear__中,mask是线性变大的,而__in__则是开始初期变大比较缓慢,__out__则是结束的时候比较缓慢,__in-out__则是初期和后期都缓慢,中期加速。如果想看到更强烈的区别,其实可以把__frames__调大一些。
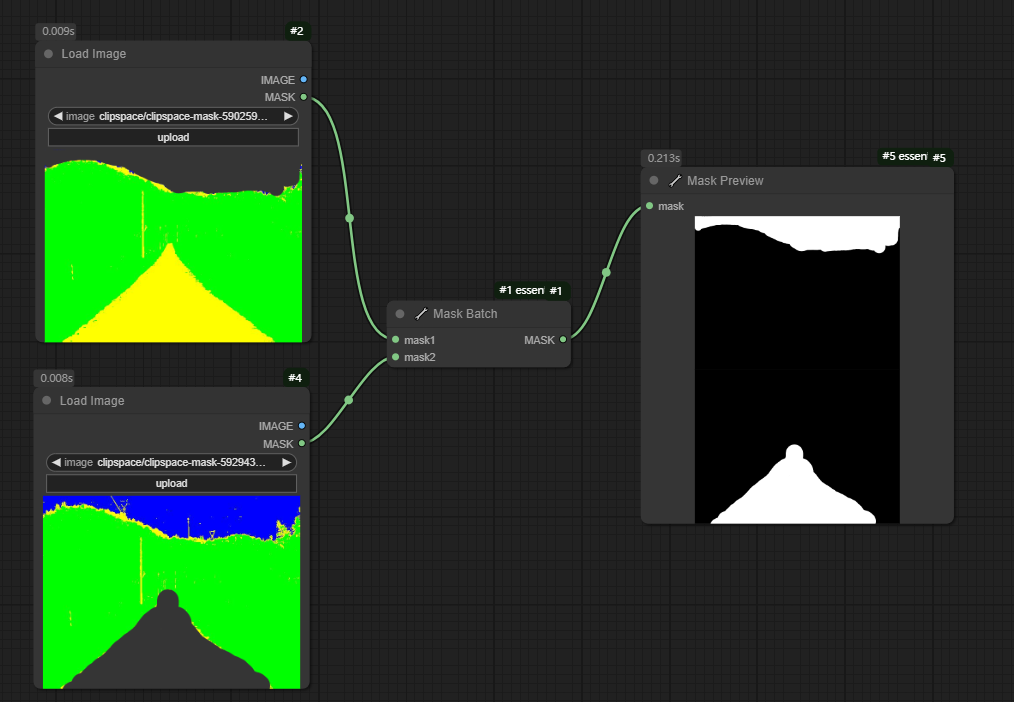
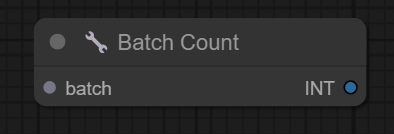
二、Mask Batch节点
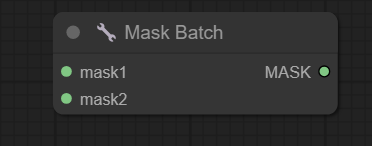
节点功能:该节点是将输入的2个蒙版变成1批蒙版
参数:
mask1 -> 输入的蒙版1
mask2 -> 输入的蒙版2
输出:
MASK -> 输出的1批蒙版,注意:生成的批次蒙版大小和蒙版1一样
如下图,将2张蒙版合成一张蒙版。
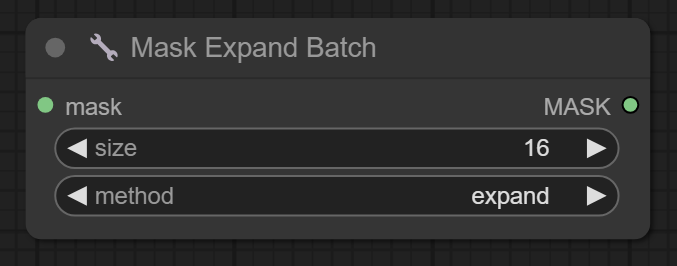
三、Mask Expand Batch节点
节点功能:该节点的功能是对输入的掩码 (mask) 进行批量扩展或重复,以生成一个新的批量掩码
输入:
mask -> 输入蒙版
size -> 目标一批蒙版里的蒙版数量
method -> 扩展蒙版的方式
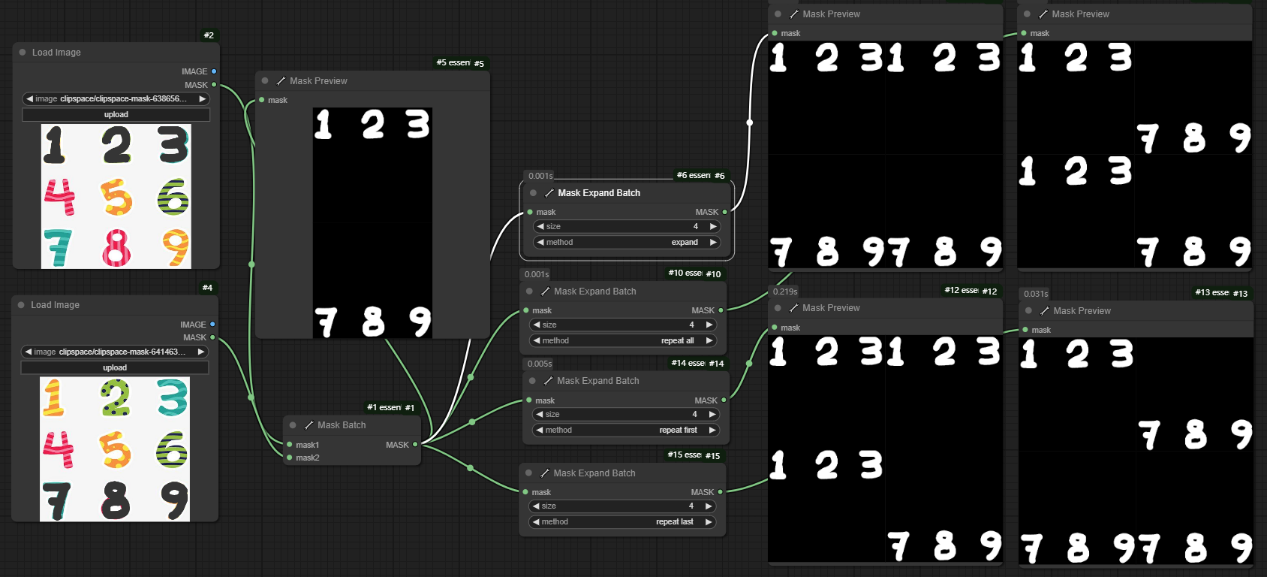
- expand: 通过扩展掩码的数量,生成与 size 相等的批量掩码。
- repeat all: 将整个输入批量的掩码重复
- repeat first: 仅重复第一个掩码
- repeat last: 仅重复最后一个掩码
输出:
MASK -> 输出的新的一批蒙版
以下为不同__method__下模板的扩展与重复。
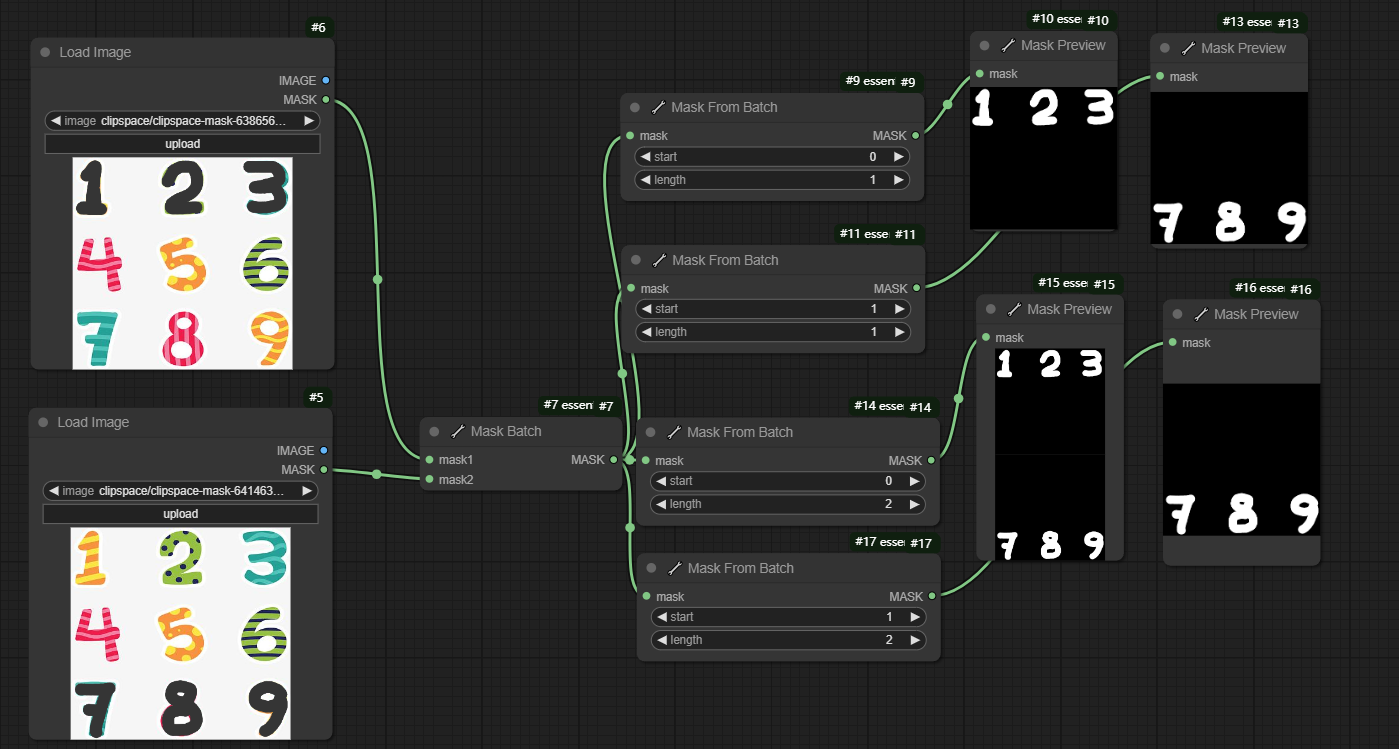
四、Mask From Batch节点
节点功能:从一批蒙版中获取部分蒙版
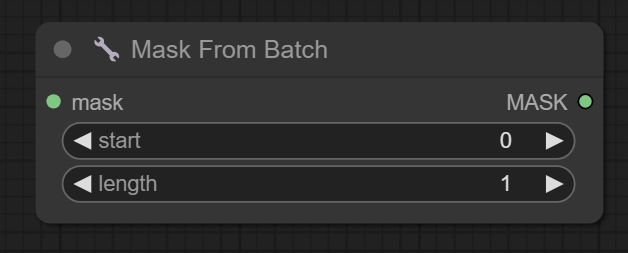
输入:
mask -> 输入的一批蒙版
参数:
start -> 从一批蒙版中获取的起始蒙版序号
length -> 从起始蒙版开始获取蒙版的数量
输出:
MASK -> 输出的获取的蒙版
__start__就是从第几张开始输出,__length__就是输出的张数,虽然第四章图中设置了__length__为2,__start__是从1开始,mask只有一张了,故只输出了一张。
五、Ksampler Stochastic Variations节点
节点功能:随机变化K采样器, 本质是两个设置特定参数K采样器串联来达到图片在一定幅度范围内发生变化的采样方法
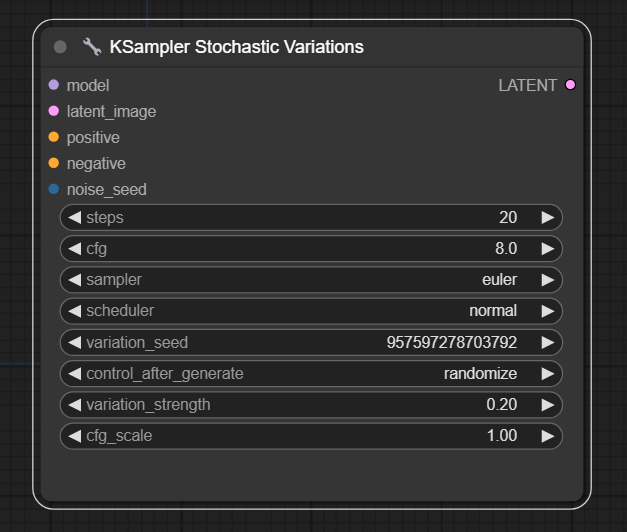
输入:
model -> 输入的模型名
latent_image -> 输入的潜空间图片
positive -> 输入的正向条件
negative -> 输入的负向调节
noise_seed -> 输入的种子,第一个采样器的种子数
参数:
steps -> 采样步数
cfg -> 提示词引导系数,引导提示词效果强弱,第一个采样器使用的cfg值
sampler -> 使用的采样器,只是第一个采样器的采样方法
scheduler -> 使用的调度器,两个采样器使用的共同参数
variation_seed -> 变异种子数,实际上就是第二个K采样器的种子数,且第二个K采样器默认的采样方法是dpmpp_2m_sde
variation_strength -> 设置变化强度,最小0,最大1,本质就是调节两个采样器分配步数的比例
cfg_scale -> 提示词引导系数的因子,与cfg相乘的得到的结果在不小于1的情况下构成第二个采样器的cfg值
输出:
LATENT -> 输出的潜空间图片
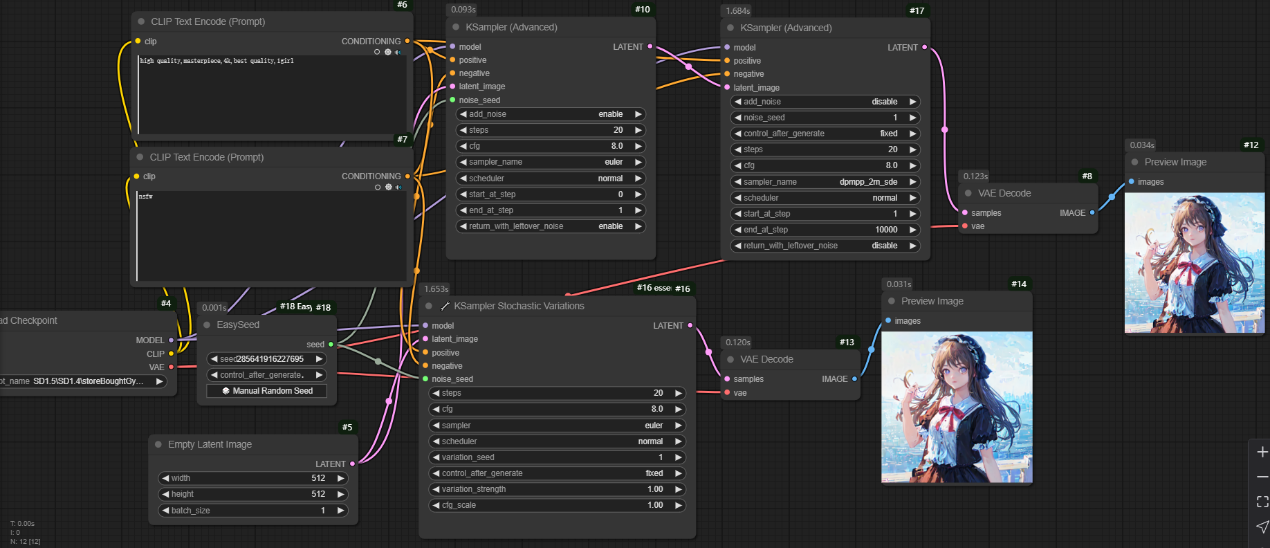
如下图,上面两个__KSamler(Advanced)__的效果和下面一个__Ksampler Stochastic Variations__的效果是一样的。但是在实践过程中发现第二个__KSamler(Advanced)__的采样器只能选择__dpmpp_2m_sde__才能达到相同效果。第一个__KSamler(Advanced)__的采样器要和__Ksampler Stochastic Variations__的采样器设置成一样。__cfg_scale__相当于第二个__KSamler(Advanced)__的__cfg__除以第一个__KSamler(Advanced)__的__cfg__值。
六、Inject Latent Noise节点
节点功能:对潜空间图片进行注入噪声,使得图片的可变化性增强,适用于图生图,高清放大、补充细节等场景中
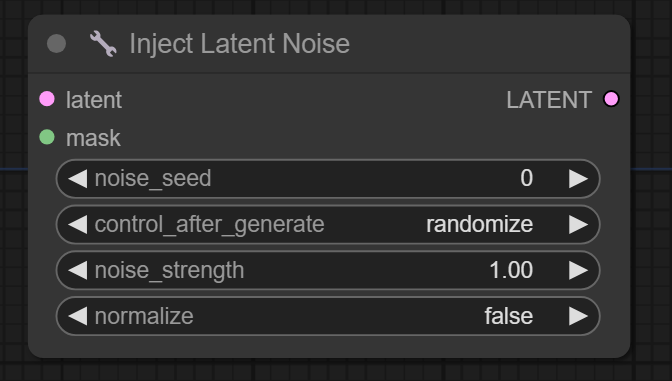
输入:
latent -> 输入的潜空间图片
mask -> 输入的噪声注入影响的蒙版区域
参数:
noise_seed -> 注入噪声的种子数
control_after_generate -> 种子数生成的控制方式,一般常用
randomize和fixed
noise_strength -> 噪声注入的强度,选择非归一化处理可以选择0到20范围内,选择归一化处理最好选择0-3范围内
normalize -> 在噪声注入过程中是否进行归一化处理,这里的归一化处理就是对产生随机潜空间噪声根据原始的潜空间噪声进行标准差和均值运算
输出:
LATENT -> 输出的噪声注入后的潜空间图片
以下为__noise_strength__不同值下效果图,可以看到,__noise_strength__值越大,噪声越多,步数少则无法去除噪声。需要注意:若normalize为false,则使用Inject Latent Noise节点生成的图片和不用几乎没什么区别。
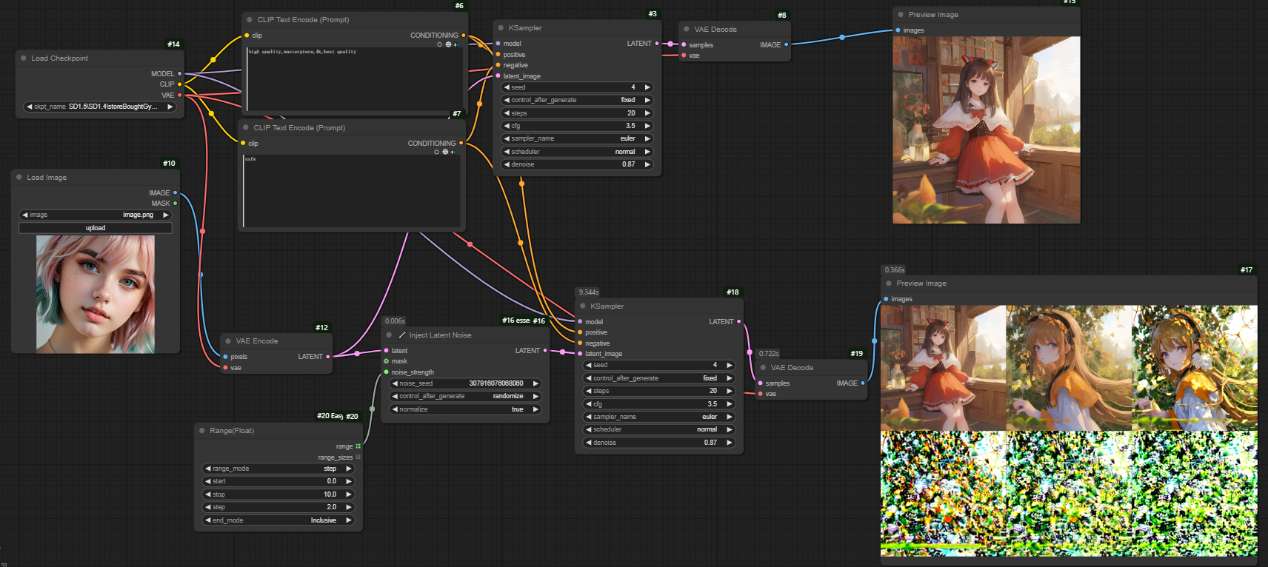
七、Batch Count节点
节点功能:统计一批图片或蒙版里含有的图片或蒙版数量
 参数:
参数:
batch -> 输入的一批图片或蒙版
int -> 输出的一批图片或蒙版里含有的图片或蒙版数量
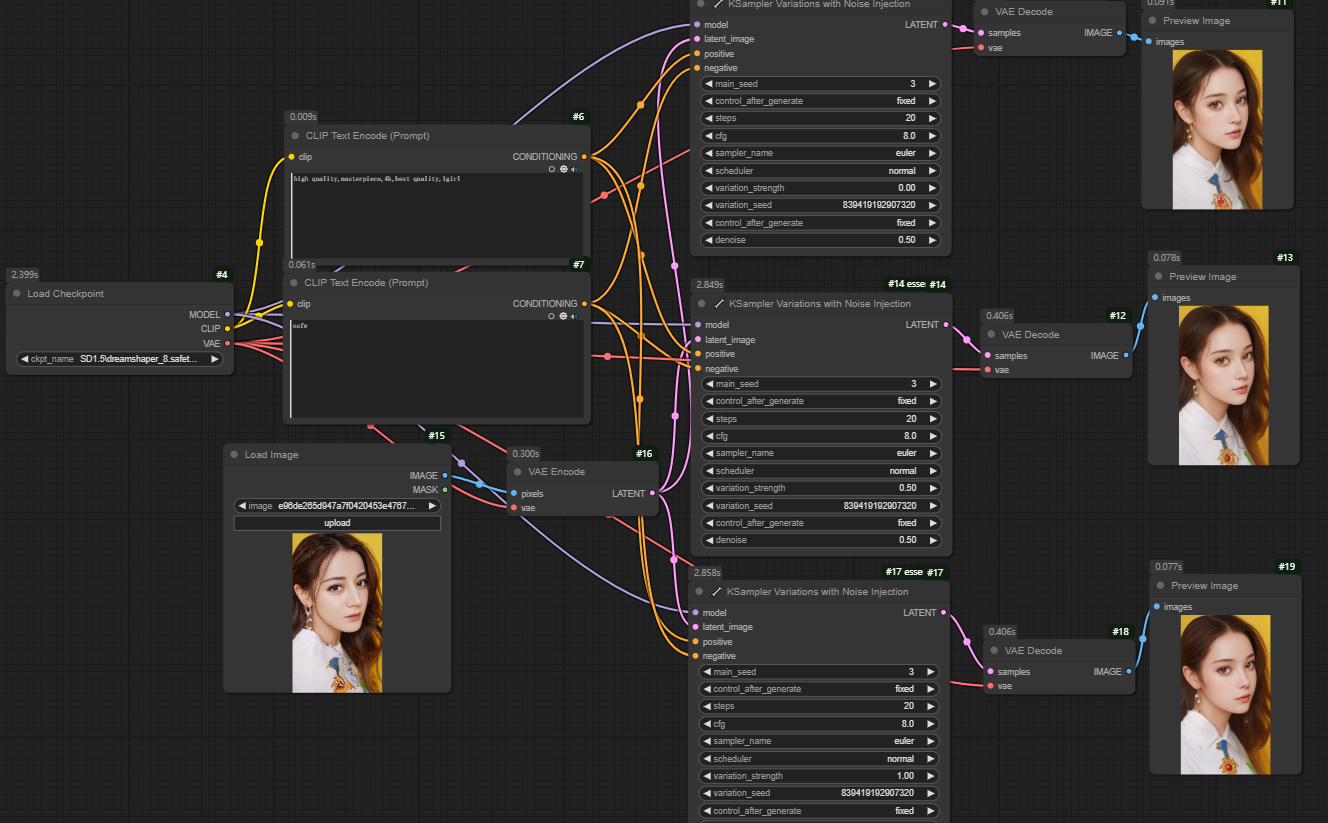
八、Ksampler Variations with Noise Injection节点
节点功能:通过噪声注入实现生成图片可以在一定范围内变化的采样器节点
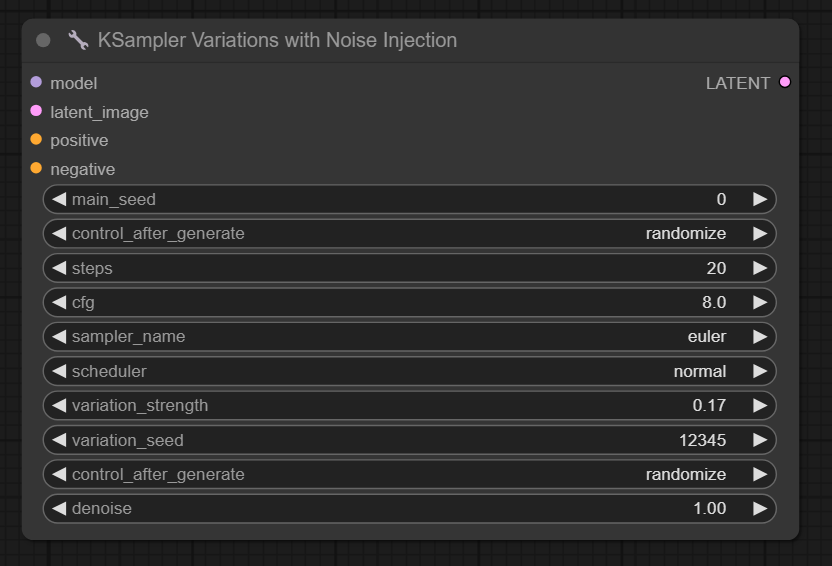
输入:
model -> 输入的模型
latent_image -> 输入潜空间图片
positive -> 输入的正向条件
negative -> 输入的负面条件
参数:
main_seed -> 输入的种子数
control_after_generate -> 种子数生成的控制方式,一般选择randomize和fixed
steps -> 采样器采样步数
cfg -> 提示词引导系数,引导提示词效果强弱
sampler -> 使用的采样器
scheduler -> 使用的调度器
variation_strength -> 变异的强度,默认0.17,取值范围从0到1,值越大变异效果越大
variation_seed -> 变异的种子数
control_after_generate -> 变异种子数生成的控制方式,一般选择randomize和fixed
denoise -> 降噪强度,默认为1,降噪强度低越接近传入的潜空间图片,降噪强度高更接近于提示词
三个__Ksampler Variations with Noise Injection__中参数几乎一样,只有__variation_seed__不同,可以看到,图片只有一些微小的变化。需要注意:denoise需要设置小一点,这样才能更接近于输入图,太大则变动也会很大。
九、Load CLIPSeg Models/Apply CLIPSeg节点
节点1功能:加载CLIPSeg模型,一个用于分割的模型。但目前不推荐使用这个CLIPSeg模型,因为有很多更好的分割模型和节点比如LayerStyle插件里的分割节点
节点2功能:使用CLIPSeg模型根据提示词去生成对应蒙版的处理节点。
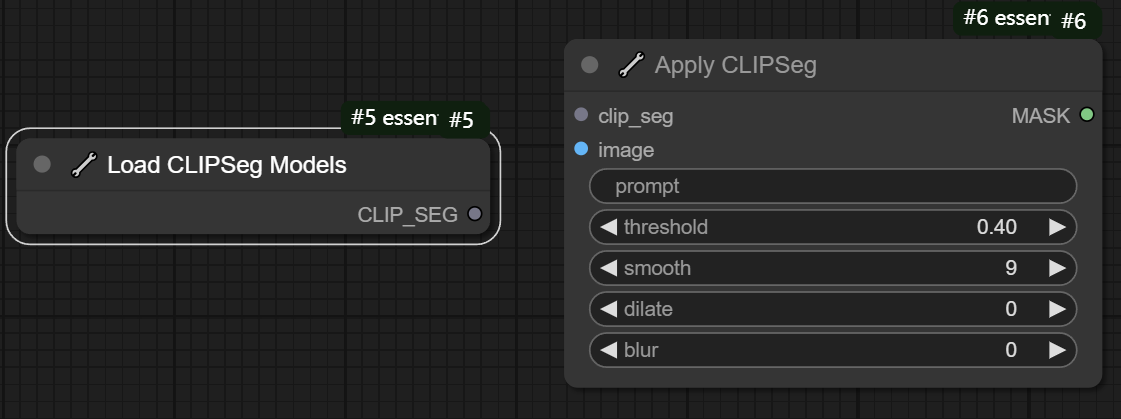
节点1参数:
CLIP_SEG -> 输出的加载的CLIPSeg模型
节点2输入:
clip_seg -> 输入的CLIPSeg模型
image -> 输入的图片
节点2参数:
prompt -> 输入的提示词,用于接下来分割图片的引导
threshold -> 设置的分割阈值,取值范围0到1,一般默认即可
smooth -> 设置分割蒙版的平滑度,值越大,蒙版过渡越平滑
dilate -> 设置蒙版的扩展值,值越大,蒙版扩展越明显,按需选择即可
blur -> 设置蒙版模糊,值越大,蒙版模糊程度越大
节点2输出:
MASK -> 输出分割蒙版
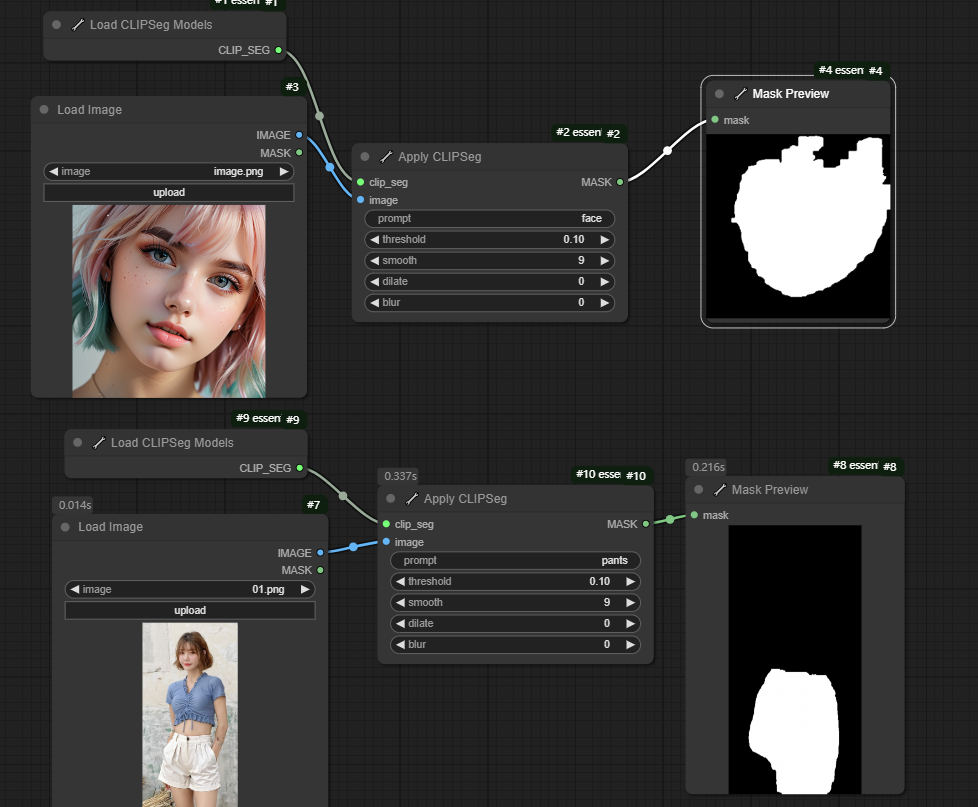
可以看出,该分割器的效果不是很好,需要不断调__threshold,__而且分割的边缘也不是很好。
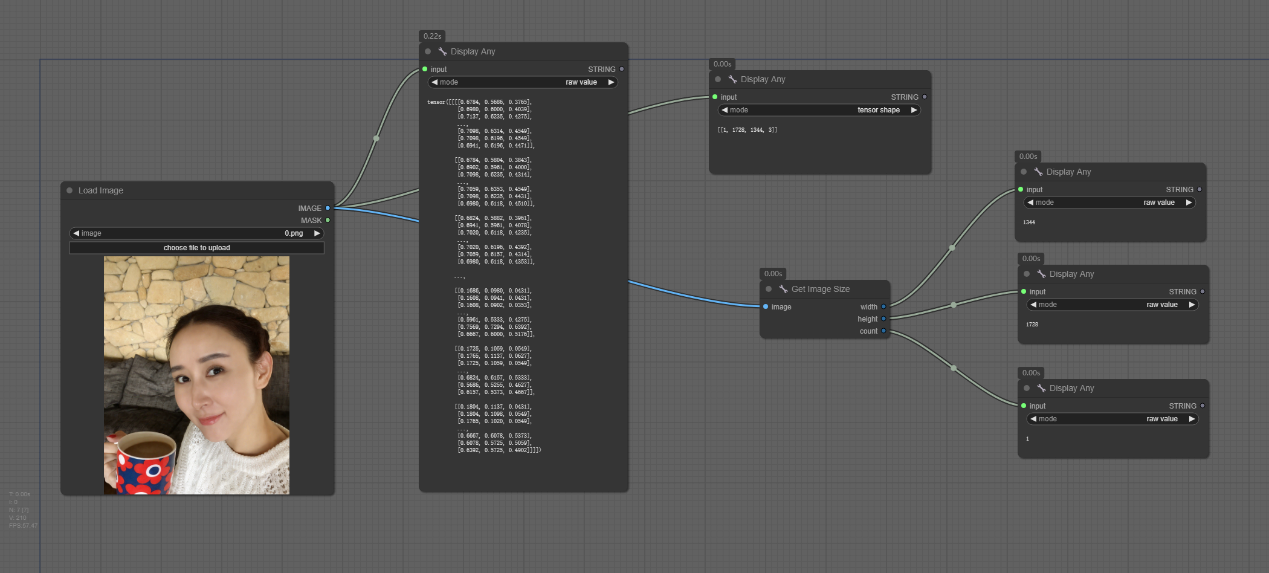
十、Display Any节点
节点功能:可将输入数值通过raw value或者tensor shape模式进行展示
输入:
input -> 输入的值,可以输入任何值
参数:
mode -> 选择展示的模式
- raw value:直接原始值输出,
- tensor shap: 是针对有tensor数据结构的输入进行显示其tensor shape大小,比如图片,如果没有tensor结构选择该模式,则会显示空列表
输出:
STRING -> 最后通过字符串形式输出
十一、Draw Text节点
节点功能:对输入图片进行写入文本形成新的图片
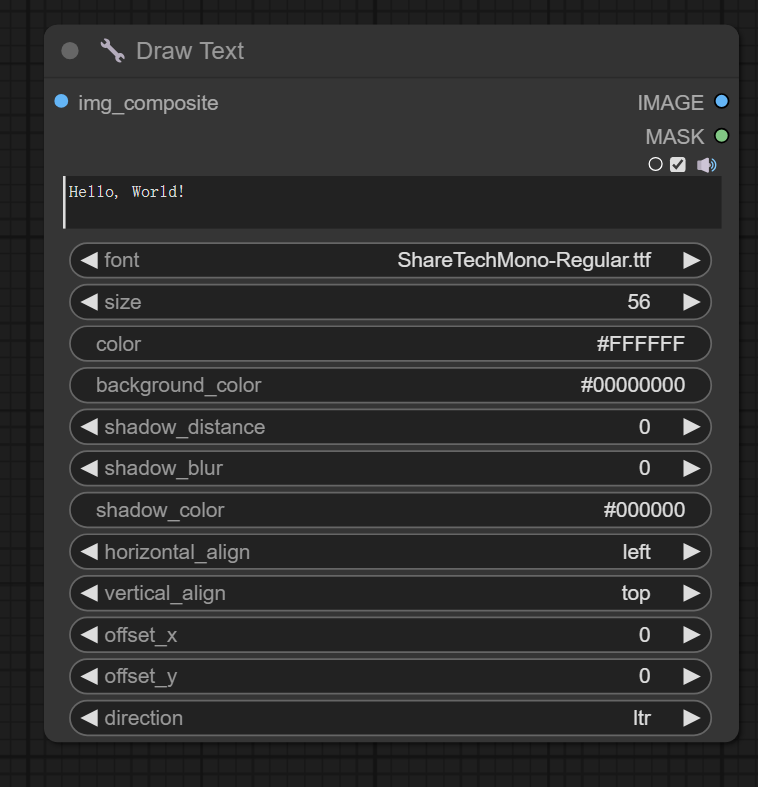
输入:
img_composite -> 输入的图片
参数:
文本框 -> 想要输入的文本
font -> 设置文本使用的字体文件,可custom_nodes\ComfyUI_essentials\fonts目录里添加新的字体文件
size -> 设置文本字体的大小
color -> 设置字体颜色
background_color -> 设置背景颜色,这里之所以#后面是8位是因为对应RGBA,即包括alpha通道颜色
shadow_distance -> 设置字体阴影举例字体的距离
shadow_blur -> 设置字体阴影的模糊程度
shadow_color -> 设置字体阴影的颜色
horizontal_align -> 调节字体水平对齐的模式,分为left(左对齐),center(中对齐)和right(右对齐)
vertical_align -> 调节字体垂直对齐的模式,分为top(上对齐),center(中对齐)和botton(下对齐)
offset_x -> 设置字体相对当前位置的x轴偏移值
offset_y -> 设置字体相对当前位置的y轴偏移值
direction -> 设置字体的展示方向,分为ltr和rtl,即正常显示和反向显示
输出:
IMAGE -> 输出的带有文字的图片
MASK -> 输出的文字蒙版
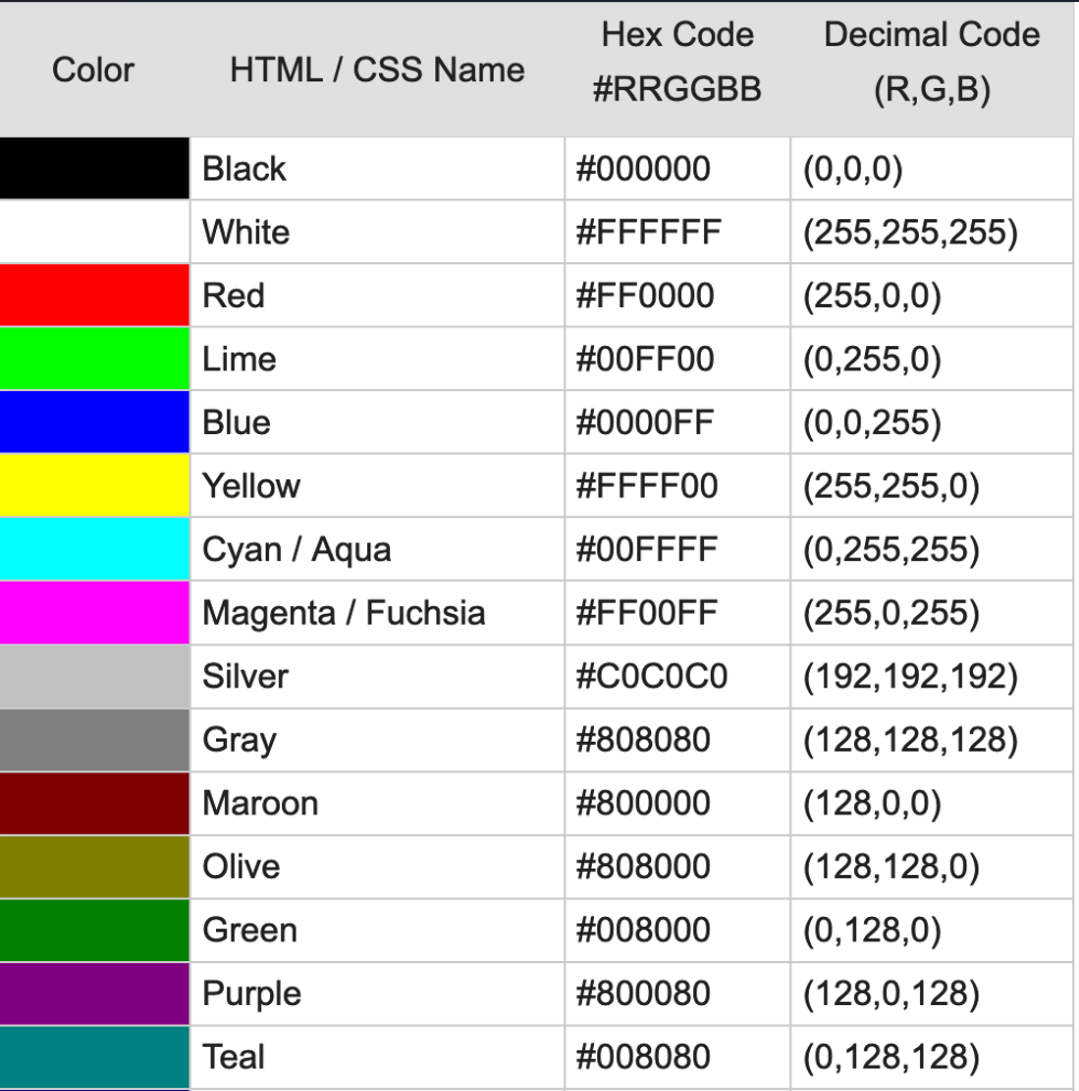
常用的十六进制颜色码:
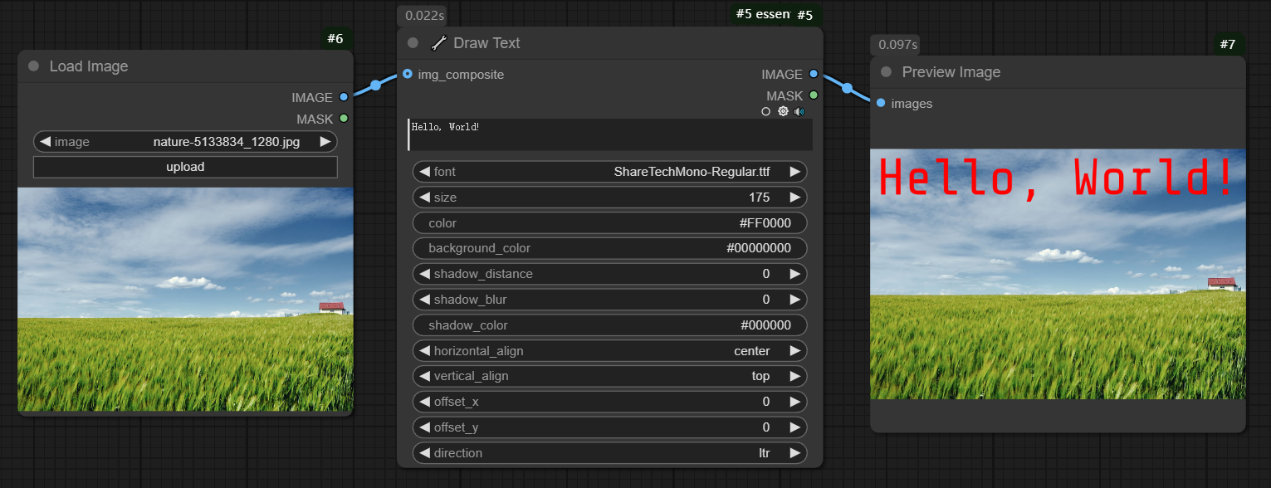
效果如下所示
十二、Simple Math/Simple Math Int/Simple Math Float节点
节点功能:设置整数类型的数值输入/设置浮点类型类型的数值输入,一般和Simple Math节点相配合
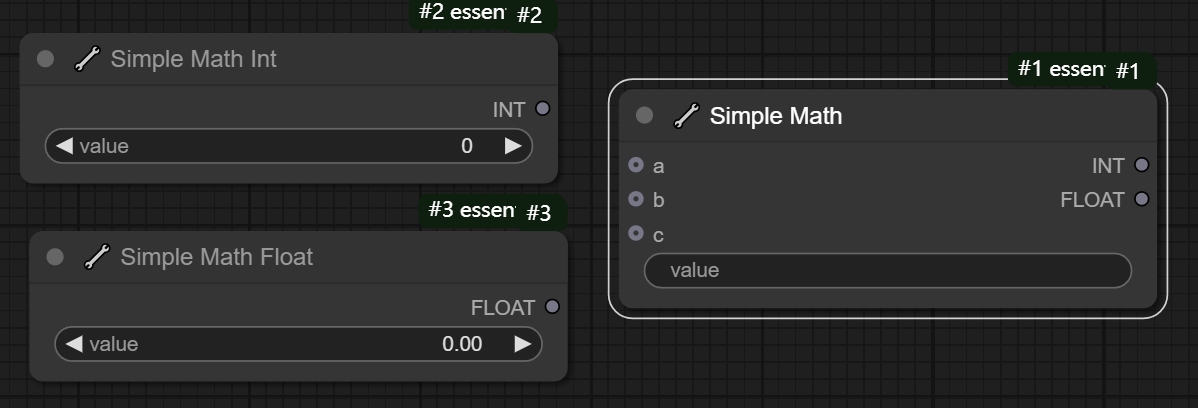
Simple Math参数:
value文本框 -> 对前面输入数值的计算公式
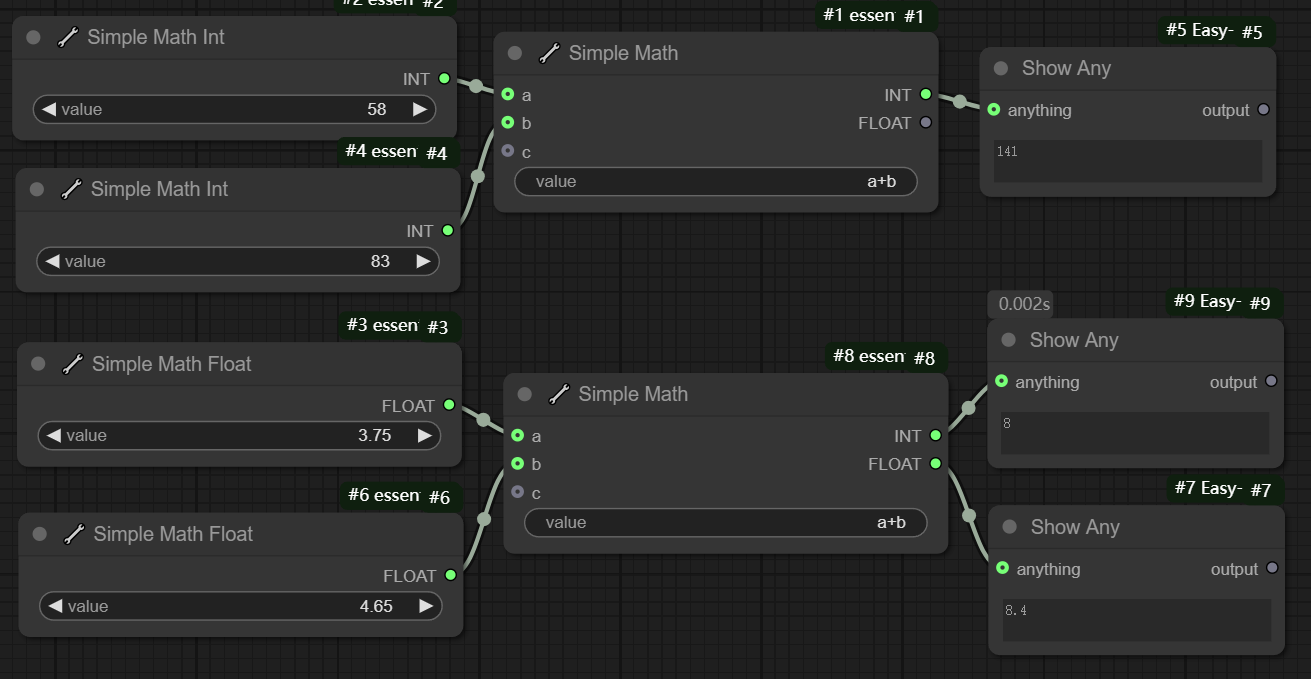
需要注意的是,若是float计算,输出int时会将后面的小数进行截断
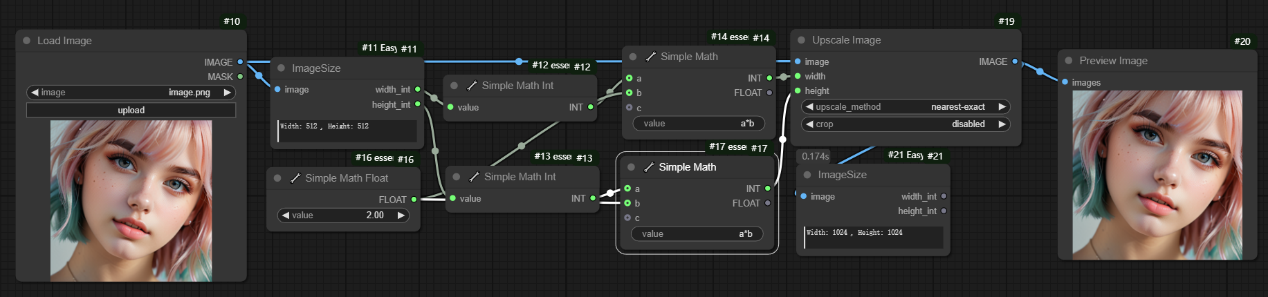
将图片的宽和高都放大2倍。
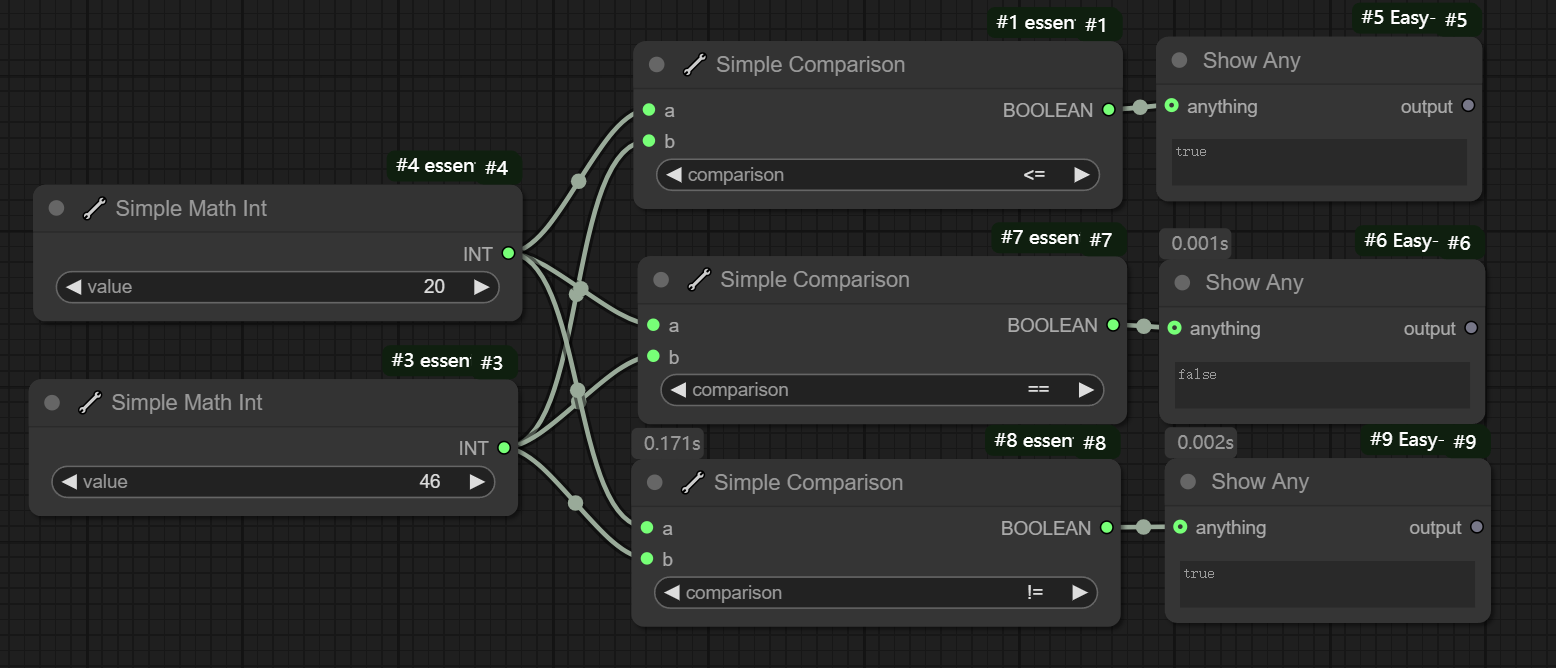
十三、Simple Comparision节点
节点功能:通过实现简单的比较,完成判断,一般与IF节点联合使用
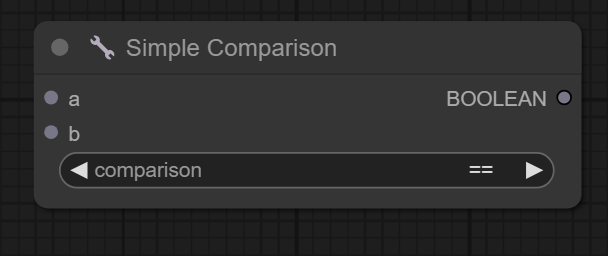
输入:
a -> 输入的数值a
b -> 输入的数值b
参数:
comparision -> 输入的a和b的比较方式
输出:
BOOLEAN -> 比较判断的结果,是True或者False
__ComfyUI Essentials插件(一): __https://articles.zsxq.com/essentials/1.html
__ComfyUI Essentials插件(二): __https://articles.zsxq.com/essentials/2.html
__ComfyUI Essentials插件(三): __https://articles.zsxq.com/essentials/3.html
__ComfyUI Essentials插件(五): __https://articles.zsxq.com/essentials/5.html
__ComfyUI Essentials插件(六): __https://articles.zsxq.com/essentials/6.html
