【ComfyUI插件】ComfyUI Easy Use插件(六)
前言:
该插件由B站大佬乱乱呀AI进行开发出来的,此插件主要在使用管道、简化工作流、提供简便工具和集成化等方面起到了明显作用。
目录
先行:安装方法
一、PromptReplace节点
二、Easy Apply IPAdapter (From Params)节点
三、Easy Apply IPAdapter (StyleComposition)节点
四、Easy Apply InstantID节点
五、Easy Apply PuLID节点
六、Easy Apply PuLID (Advanced)节点
七、Is Mask Empty节点
八、Human Segmentation节点
九、Image Chooser节点
十、Pixels W/H Norm节点
十一、EasyKSampler (Tiled Decode)节点
__ComfyUI Easy Use插件(一): __https://articles.zsxq.com/easyuse/1.html
__ComfyUI Easy Use插件(二): __https://articles.zsxq.com/easyuse/2.html
__ComfyUI Easy Use插件(三): __https://articles.zsxq.com/easyuse/3.html
__ComfyUI Easy Use插件(四): __https://articles.zsxq.com/easyuse/4.html
__ComfyUI Easy Use插件(五): __https://articles.zsxq.com/easyuse/5.htm__l
ComfyUI Easy Use插件(七): __https://articles.zsxq.com/easyuse/7.html
__ComfyUI Easy Use插件(八): __https://articles.zsxq.com/easyuse/8.html
本期使用的示例工作流在网盘:小黄瓜知识星球资料分享/插件节点讲解视频/ComfyUI_EasyUse/第六期文件夹中
安装方法
安装方法,一共有2种
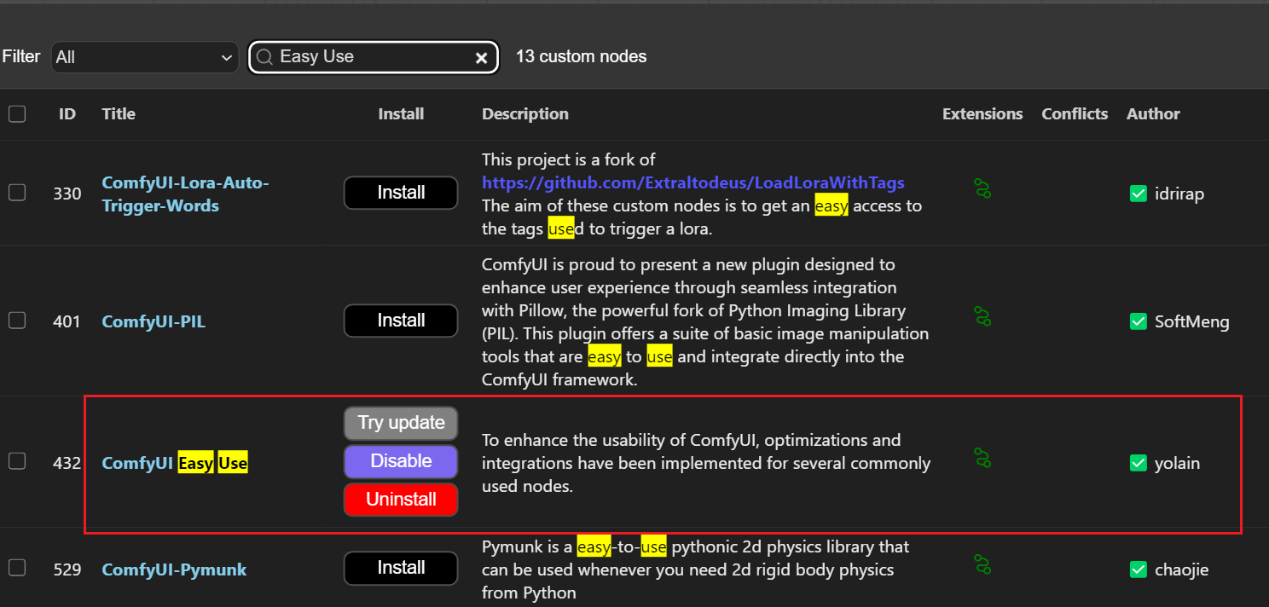
1、在manager里搜索Easy Use,然后点击安装第3个即可
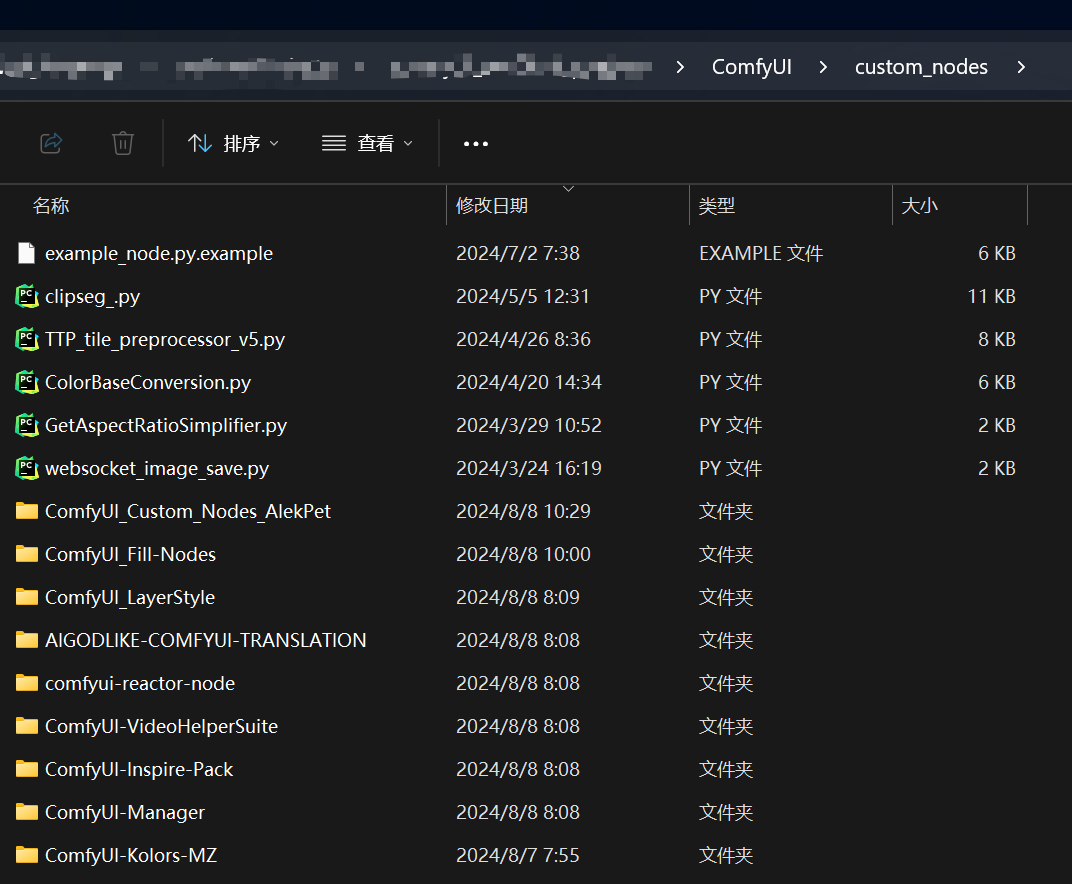
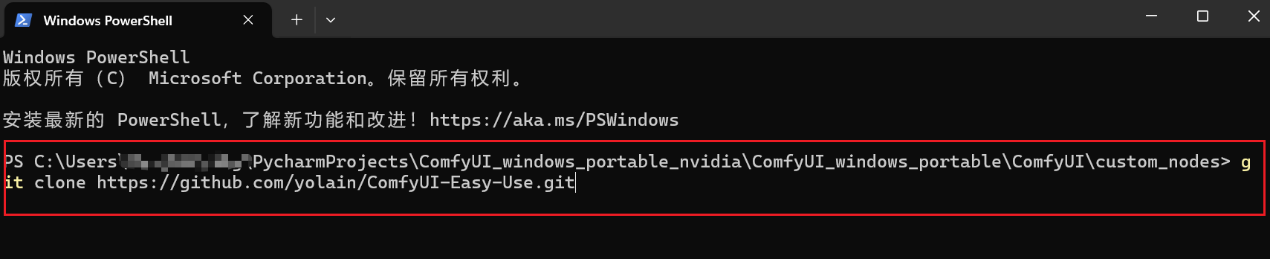
__2、在custom_nodes目录下调用cmd,然后输入git clone __https://github.com/yolain/ComfyUI-Easy-Use.git
项目地址:https://github.com/yolain/ComfyUI-Easy-Use.git
一、PromptReplace节点
节点功能:将提示词按照自己设置的替换词进行替换从而形成新的提示词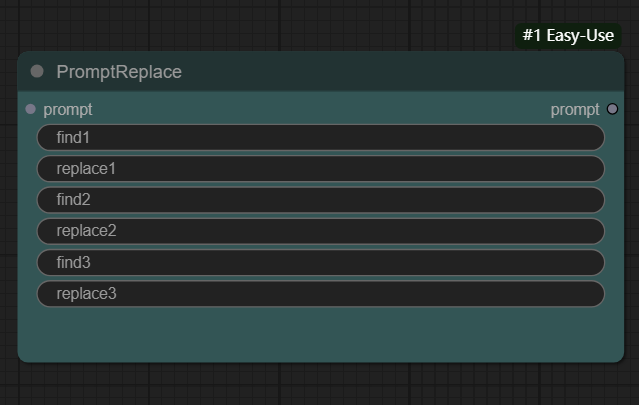
输入:
prompt -> 输入的提示词
参数:
find1 -> 设置想要替换的提示词中的名词1
replace1 -> 设置提示词中的名词1对等的替换词1
find2 -> 设置想要替换的提示词中的名词2
replace2 -> 设置提示词中的名词2对等的替换词2
find3 -> 设置想要替换的提示词中的名词3
replace3 -> 设置提示词中的名词3对等的替换词3
prompt -> 输出提示词替换后的新提示词
如下图,其中的1gril提示词被替换成了1boy。
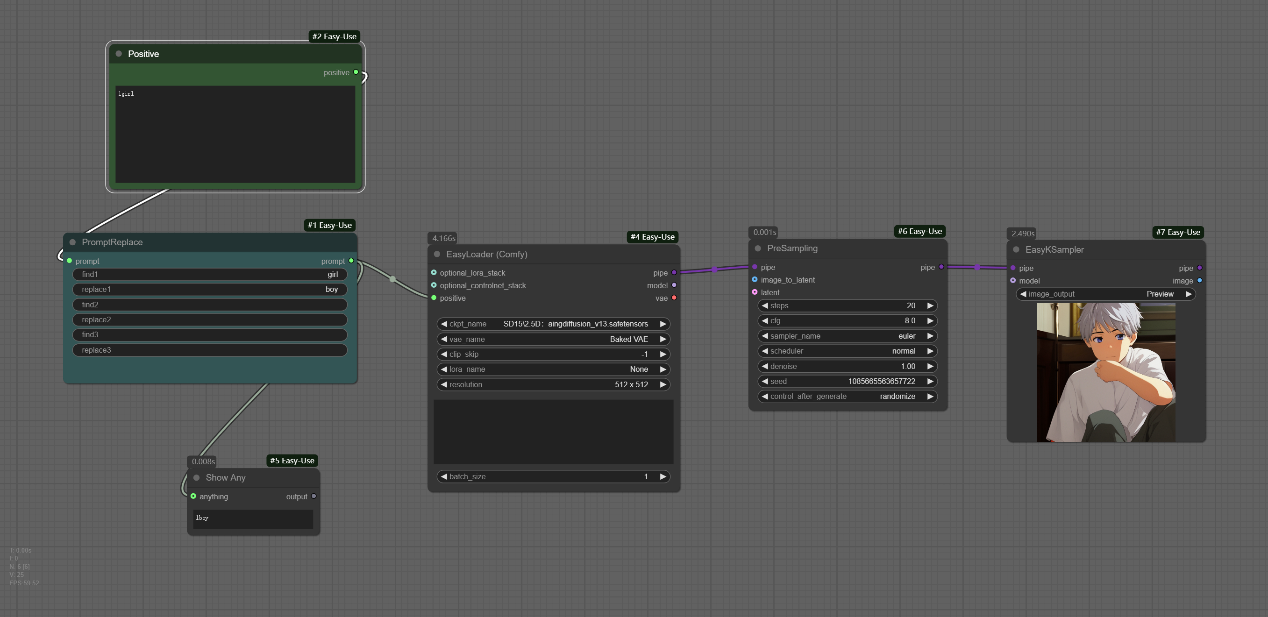
二、Easy Apply IPAdapter (From Params)节点
节点功能:接收IPA参数并输出调节后的模型,可用来和Easy Apply IPAdapter (Regional)节点一起使用完成对图片的区域控制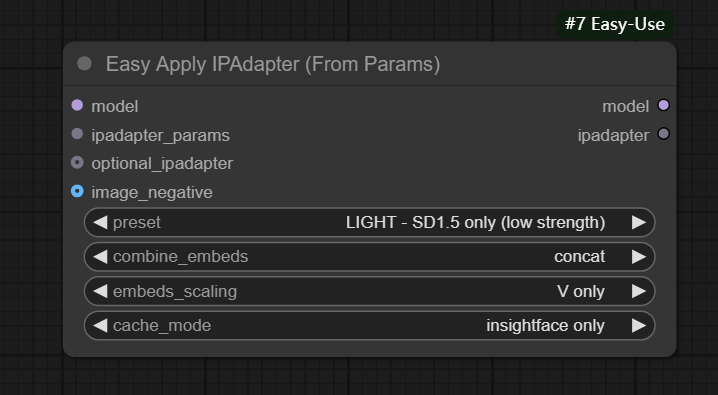
输入:
model -> 输入模型
ipadapter_params -> 输入ipadapter参数值
optional_ipadapter -> 输入ipadapter模型
image_negative -> 输入负向图片,用于剔除不想要的元素
参数:
preset -> 设置使用的ipadapter模型
combine_embeds -> 设置多个ipadapter参数之间的嵌入方式,分为concat(参数合并连接)、add(参数求和,增强共同特征)、subtract(参数求差,增强不同特征)、average(参数求平均值,平衡化)、norm average(参数求归一化平均值,更精细的平衡化)、max(取最大)、min(取最小)
embeds_scaling -> 分为V only、K+V、K+V w/C penalty、K+mean(V) w/C penalty,决定了嵌入在模型内的缩放或组合方式
cache_mode -> 选择模型加载到缓存,分为insightface only(只加载insightface模型)、clip_vision only(只加载clip模型)、ipadapter only(只加载ipadapter模型)、all(全加载)、none(不加载)
输出:
model -> 输出调节后的模型
ipadapter -> 输出使用的ipadapter模型
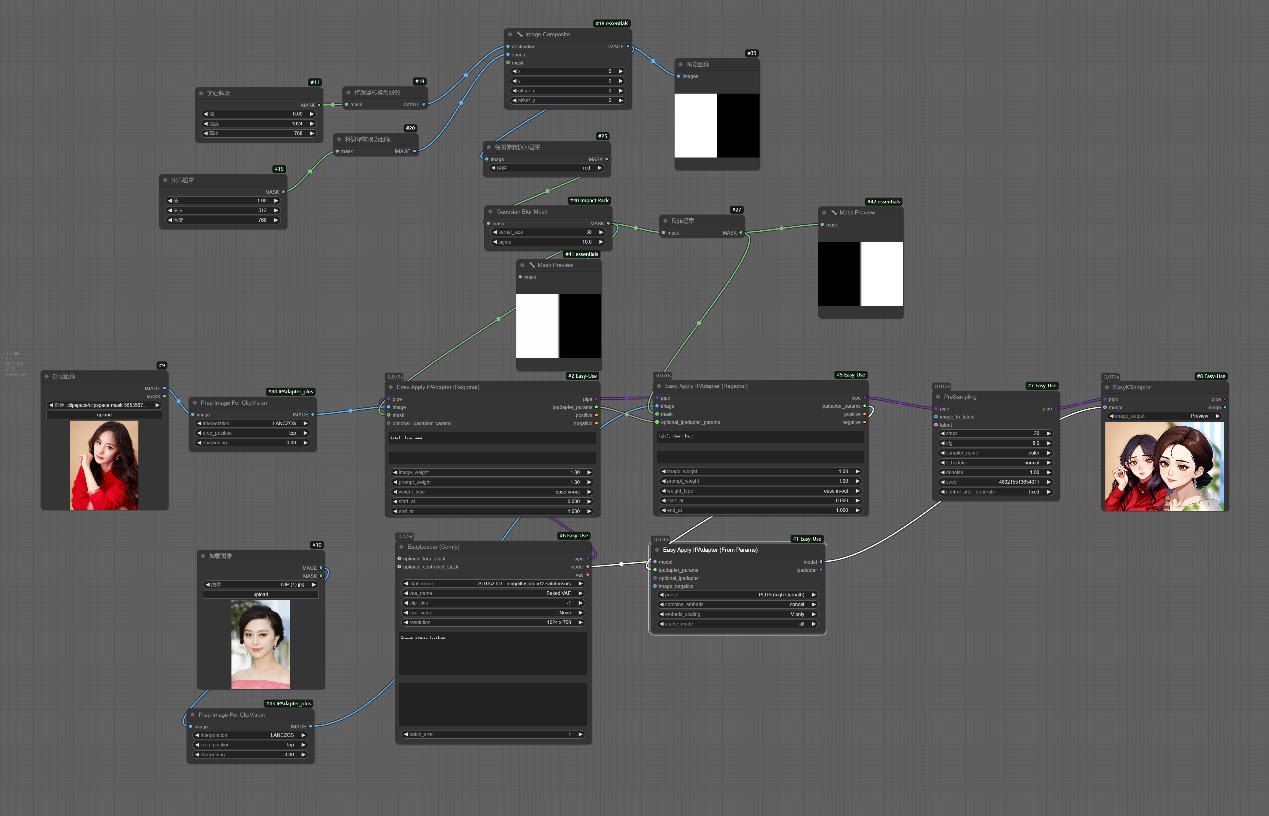
通过制作蒙版来控制生图的区域,从而让人物画面各自保持在各自的区域,但是在实践过程中发现该工作流有点随机,很难保证控图正确。想要更严格的__分区控制图片生成方法,大家可跳转b站:啦啦啦的小黄瓜。__
三、Easy Apply IPAdapter (StyleComposition)节点
节点功能:该节点主要用于在图像生成和风格化任务中,将图像的风格和组成进行结合与调整。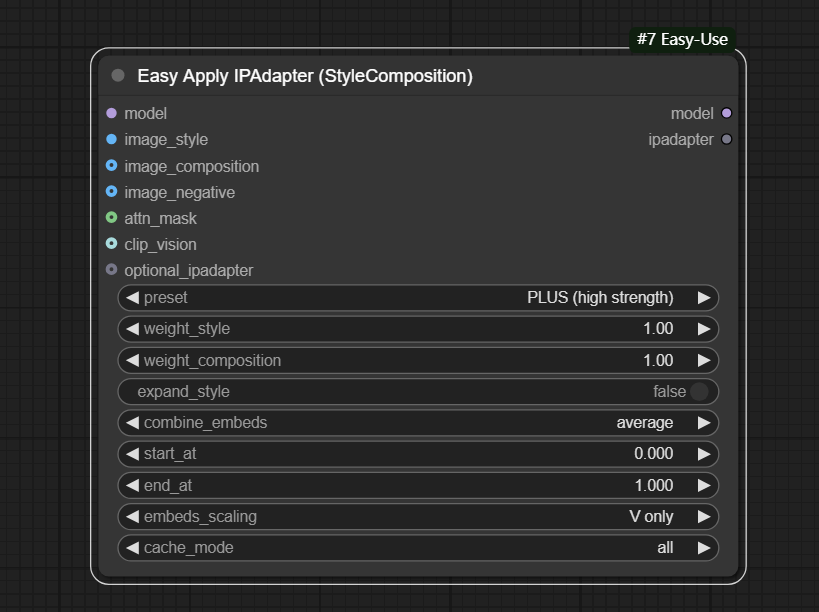
输入:
model -> 输入的模型
image_style -> 输入的风格参考图片
image_composition -> 输入的构图参考图片
image_negative -> 输入的负向参考图片
attn_mask -> 输入的图片蒙版
clip_vision -> 输入的clip模型
optional_ipadapter -> 可选择输入的ipadapter模型
参数:
preset -> 选择合适的ipadapter模型,按需选择即可
weight_style -> 设置风格迁移的权重
weight_composition -> 设置构图迁移的权重
expand_style -> 是否扩展风格
combine_embeds -> 在输入的多个参考图片使用的结合嵌入方式,分为concat、add、subtract、average、norm average
start_at -> 输入的ipadapter模型起始作用的时间,默认0代表从最开始就开始作用
end_at -> 输入的ipadapter模型结束作用的时间,默认1代表作用到最后
embeds_scaling -> 分为V only、K+V、K+V w/C penalty、K+mean(V) w/C penalty,决定了嵌入在模型内的缩放或组合方式
cache_mode -> 选择模型加载到缓存,分为insightface only(只加载insightface模型)、clip_vision only(只加载clip模型)、ipadapter only(只加载ipadapter模型)、all(全加载)、none(不加载)
输出:
model -> 输出经过ipadapter模型调节后的模型
ipadapter -> 输出的ipadapter模型
其中__weight_style__越大,原图的风格越强,__weight_composition__越大,则构图的风格越强。
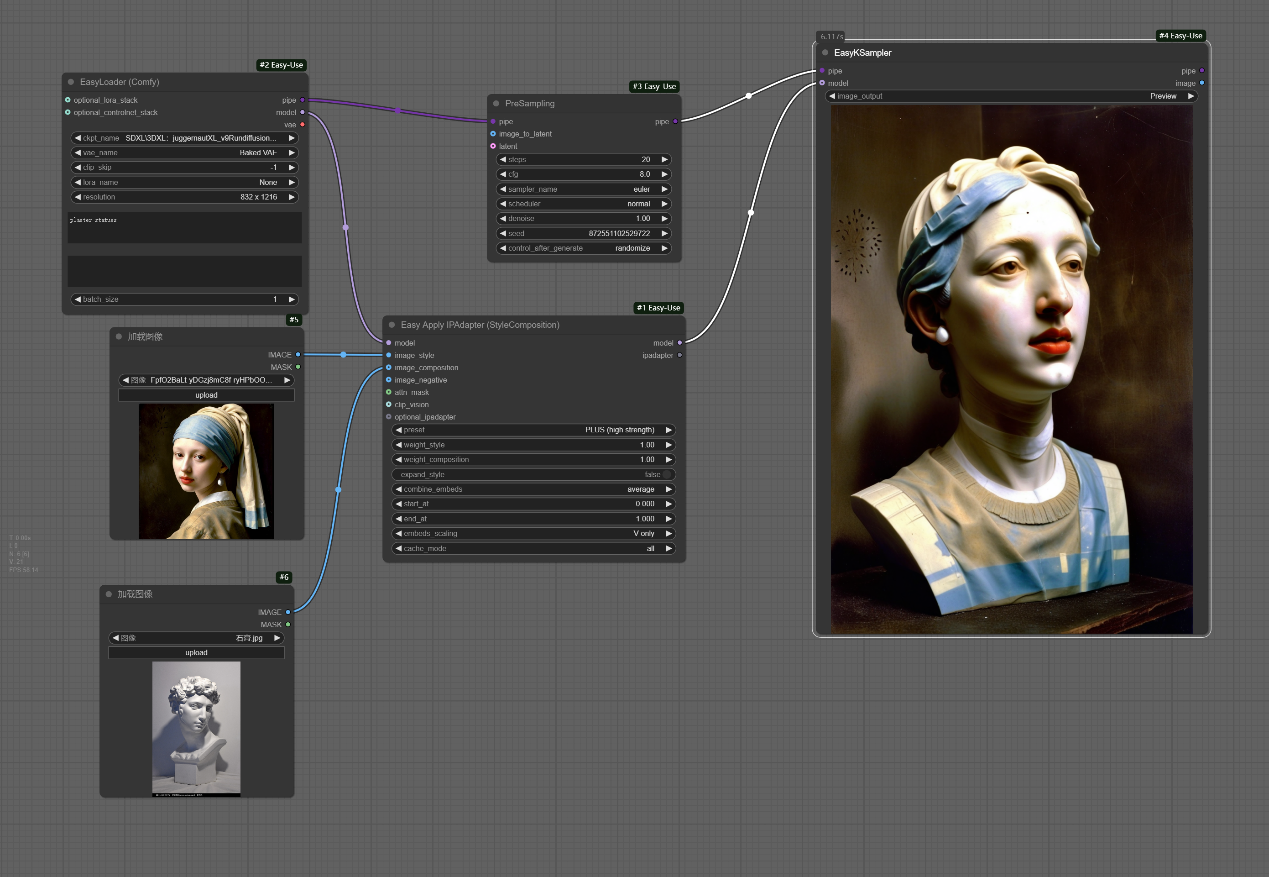
四、Easy Apply InstantID节点
节点功能:该节点用于将 instantID 模型的功能整合到图像处理管道中。其主要作用是结合预定义的 instantID 文件(如身份标识模板),对输入图像进行处理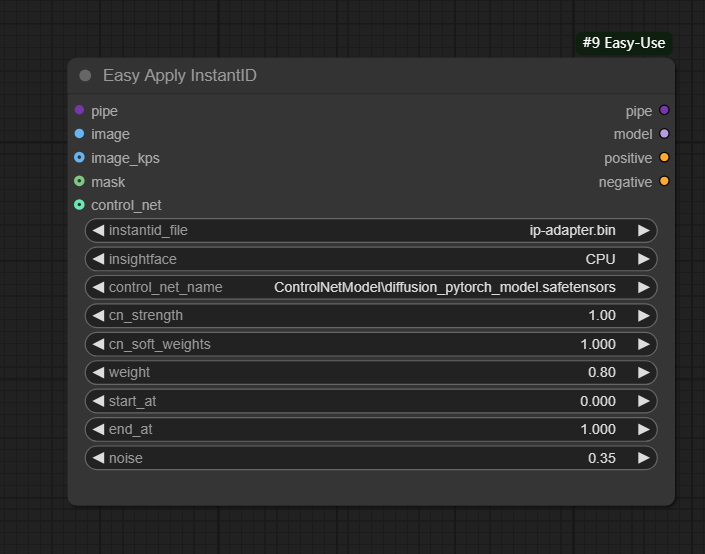
输入:
pipe -> 输入的管道
image -> 输入的人物面部参考图片
image_kps -> 输入的人物面部姿势参考图片
mask -> 输入的蒙版,可选项
control_net -> 输入的controlnet模型,可选项
参数:
instant_file -> 设置使用的instantID中的IPA模型
insightface -> 设置使用的insightface模型加载方式,分为CPU、CUDA和ROCM,一般选择CPU即可
control_net_name -> 设置使用的controlnet模型
cn_strength -> 设置controlnet模型作用强度
cn_soft_weights -> 设置controlnet模型作用比例系数,与前面的cn_strength相乘得到实际使用的controlnet模型作用强度
weight -> 设置instandID模型中IPA模型的强度
start_at -> 设置模型起始作用时间
end_at -> 设置模型终止作用时间
noise -> 设置的负向噪声输入,默认为0.35
因为原始instantid生成的图片会出现一定程度的烧毁图片,所以使用负向噪声进行调节改变这一情况
输出:
pipe -> 输出调节参数后的管道
model -> 输出调节后的模型
positve -> 输出调节后的正向条件
negative -> 输出调节后的负向条件
如下图,该节点基本就是把原图的脸部姿势变为参考图的脸部姿势。
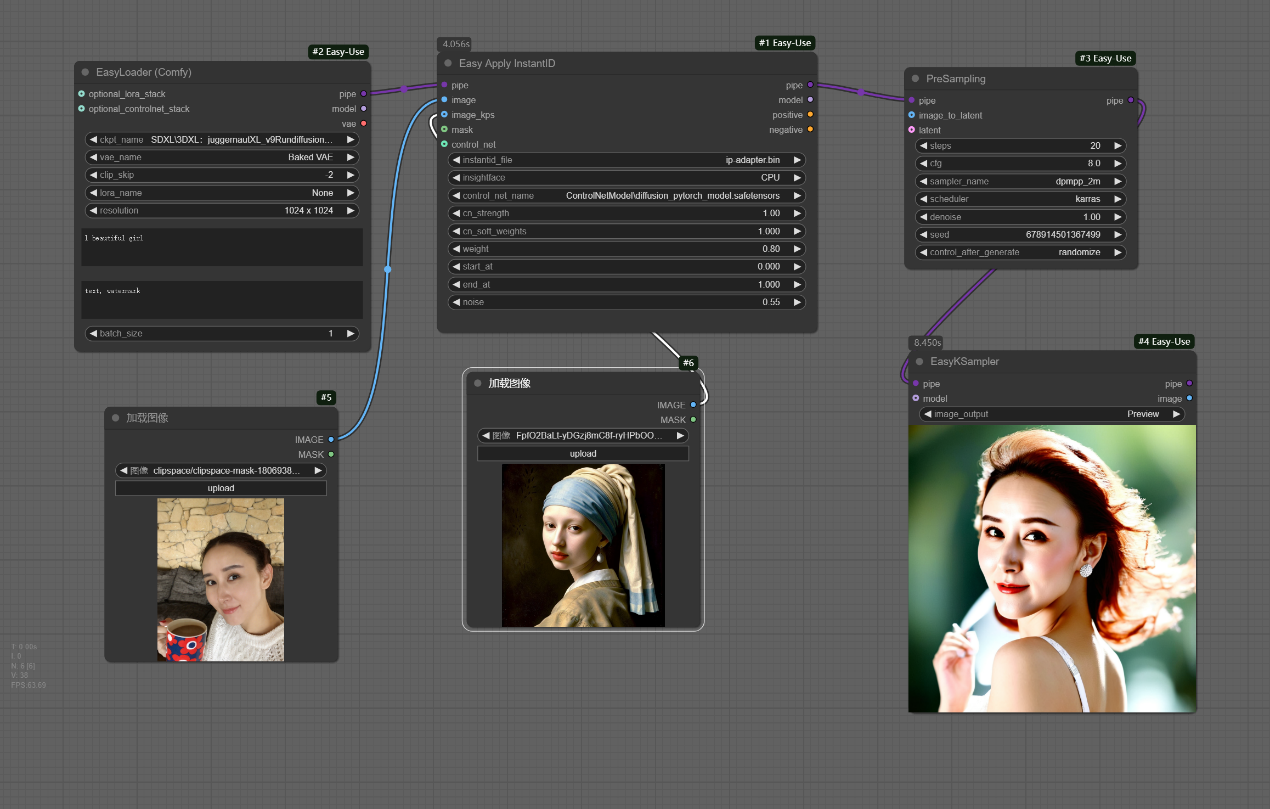
五、Easy Apply PuLID节点
节点功能:该节点主要用于通过加载和应用 PulID(预训练身份模型)对输入图像进行风格调整、身份保真度优化或风格中立化操作。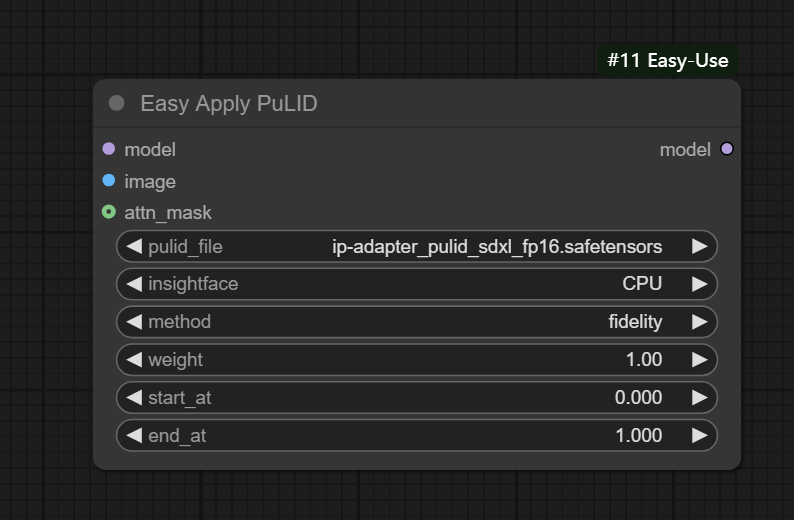
输入:
model -> 输入的模型
image -> 输入的参考图片
attn_mask -> 输入的参考图片的注意力蒙版
参数:
pulid_file -> 设置输入的pulid模型
insightface -> 设置使用的insightface模型加载方式,分为CPU、CUDA和ROCM,一般选择CPU即可
method -> 设置模型的三种使用方式,分为fidelity(保真)、style(风格)、neutral(中性),按需选择即可
weight -> 设置使用的模型权重
start_at -> 设置模型起始作用时间
end_at -> 设置模型终止作用时间
如下图,根据__method__选定的模式生成三种风格不同的图片。
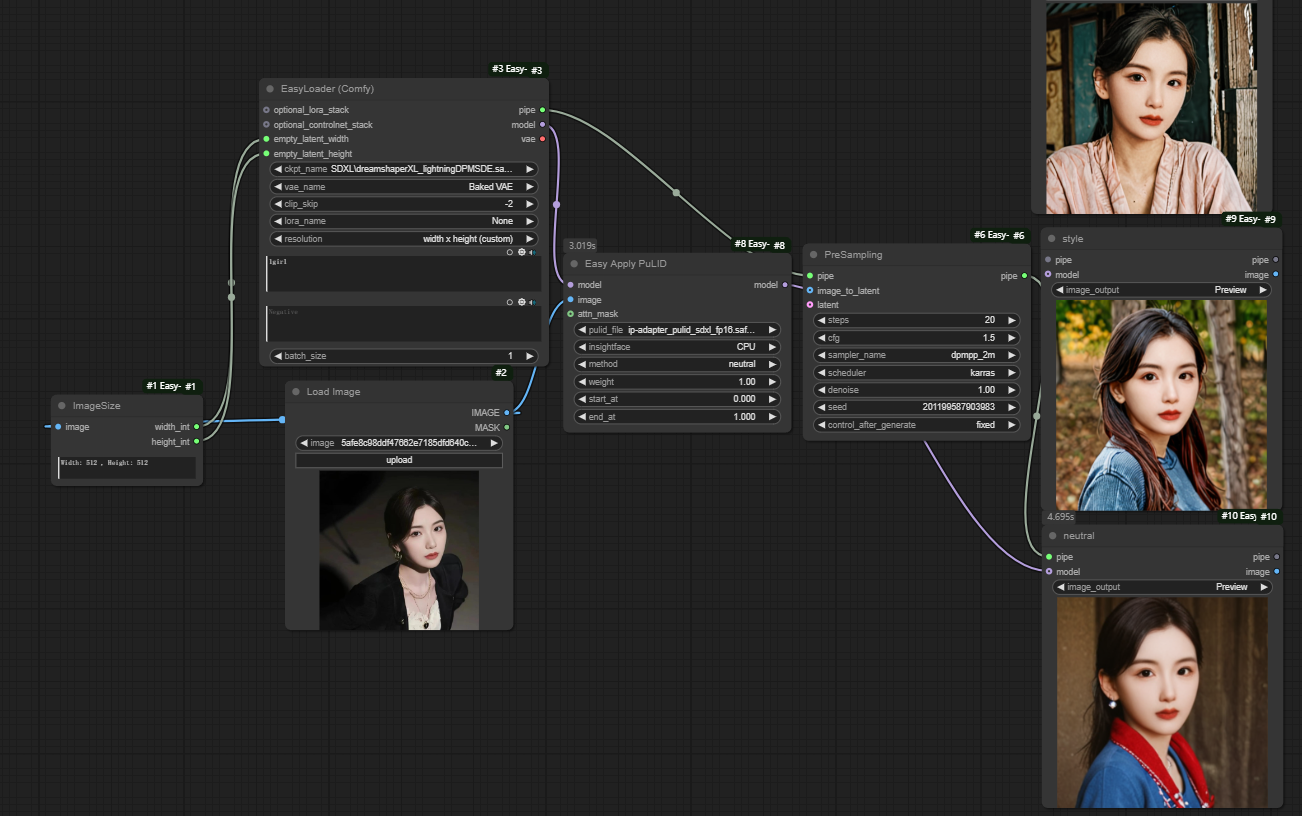
六、Easy Apply PuLID (Advanced)节点
节点功能:使用PuLID模型的高级节点,提供更多的控制参数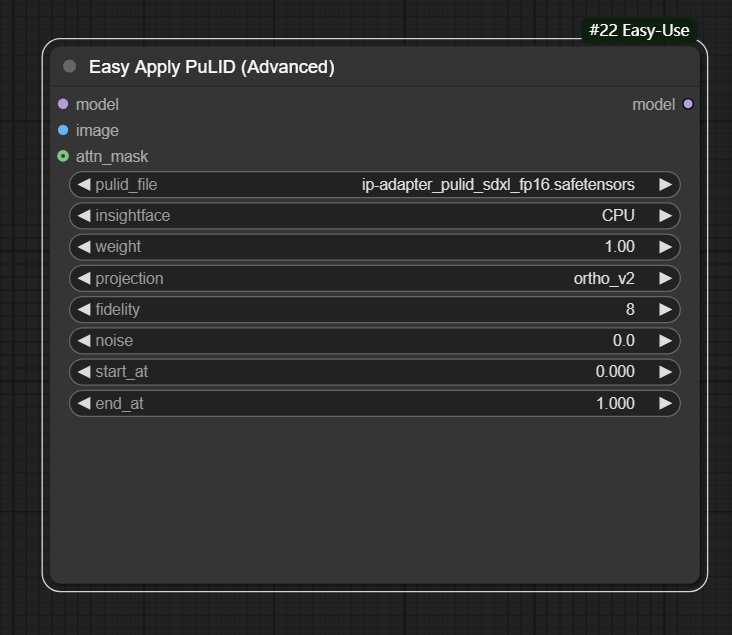 输入:
输入:
model -> 输入的模型
image -> 输入的参考图片
attn_mask -> 输入的参考图片的注意力蒙版
参数:
pulid_file -> 设置输入的pulid模型
insightface -> 设置使用的insightface模型加载方式,分为CPU、CUDA和ROCM,一般选择CPU即可
weight -> 设置使用的模型权重
projection -> 设置使用的投影算法,分为ortho、ortho_v2和none,按需选择即可
fidelity -> 设置保真度,最小值0,最大值32,按需设置即可
noise -> 输入的额外噪声,用来防止图片被烧毁
start_at -> 设置模型起始作用时间
end_at -> 设置模型终止作用时间
三种投影方式ortho_v2,ortho,none,使用投影方式的人物真实度较高。
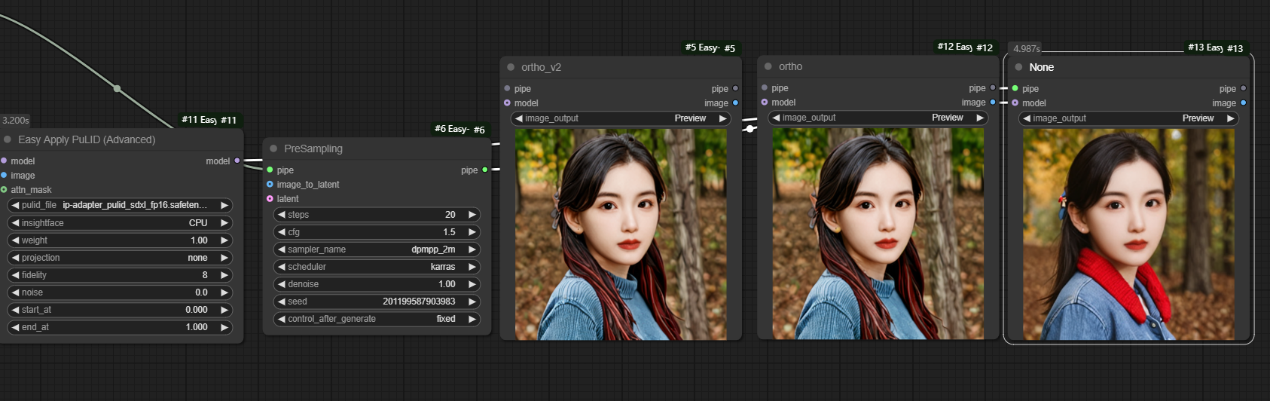
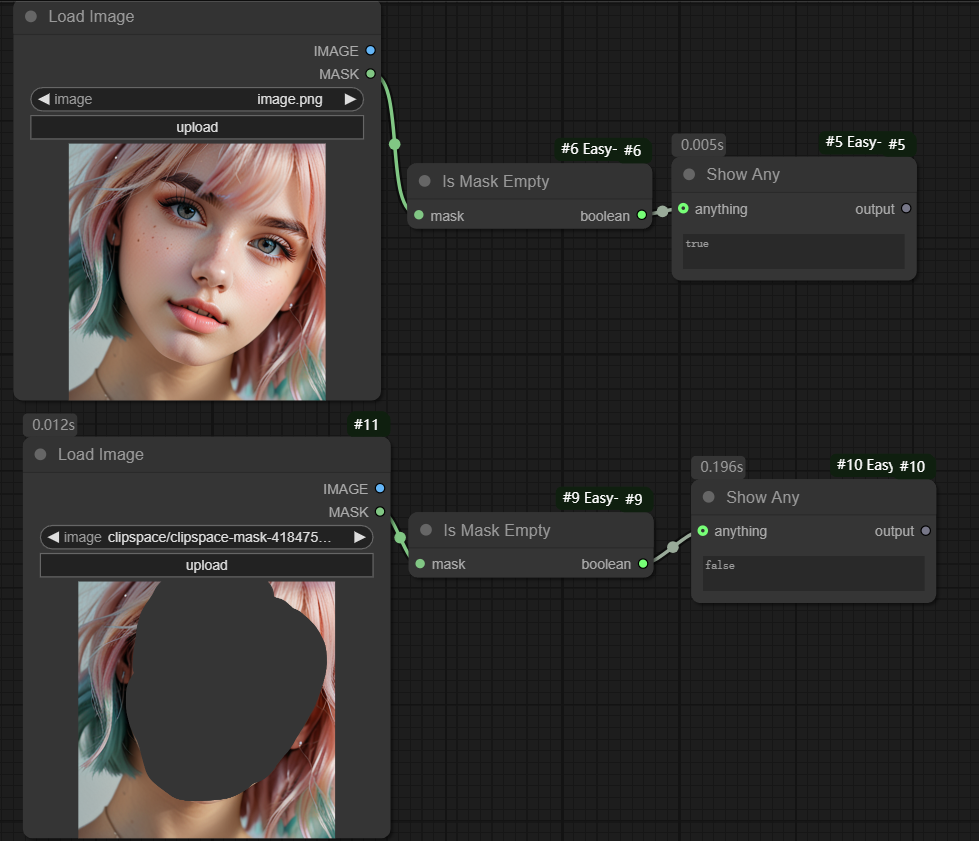
七、Is Mask Empty节点
节点功能:判断图片蒙版是否为空,在很多大型工作流中蒙版判断很有用
参数:
mask -> 输入图片蒙版
输出:
boolean -> 输出判断蒙版是否为空的布尔值(true或者false)
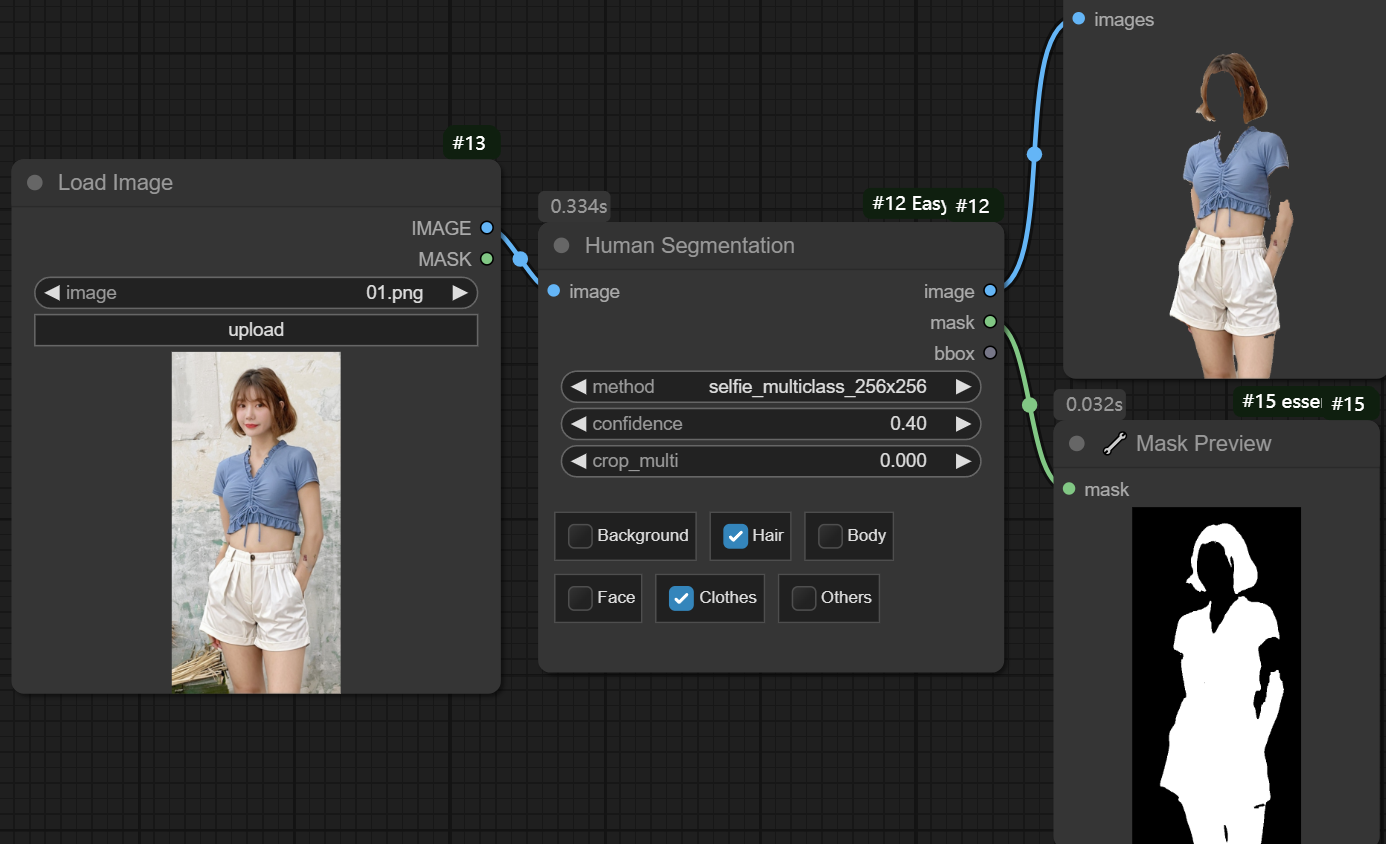
八、Human Segmentation节点
节点功能:该节点用于对输入图像中的人体进行分割和解析,生成对应的分割掩码(mask)和边界框(bbox)。 输入:
输入:
image -> 输入的图片
参数:
method -> 一共3种分割方法,分为selfie_multiclass_256x256、human_parsing_lip、human_parts (deeplabv3p),按需选择即可
confidence -> 设置图片分割识别的阈值,默认为0.4
crop_multi -> 设置分割的蒙版占整个图片的比例,默认0则是按照原有图片比例分割
分割部分 -> 通过勾选设置要识别分割的部分
输出:
image -> 输出分割后的图片
mask -> 输出分割蒙版
bbox -> 输出分割参数
三种分割方法,里面的功能有所不同,可根据自己要分割的部分选择。
九、Image Chooser节点
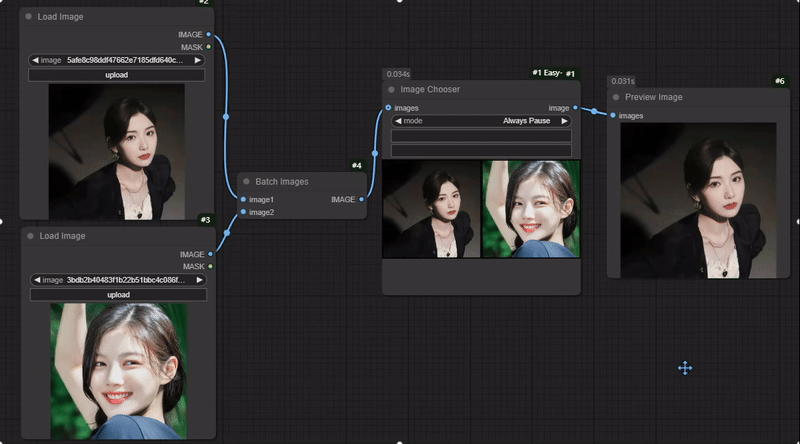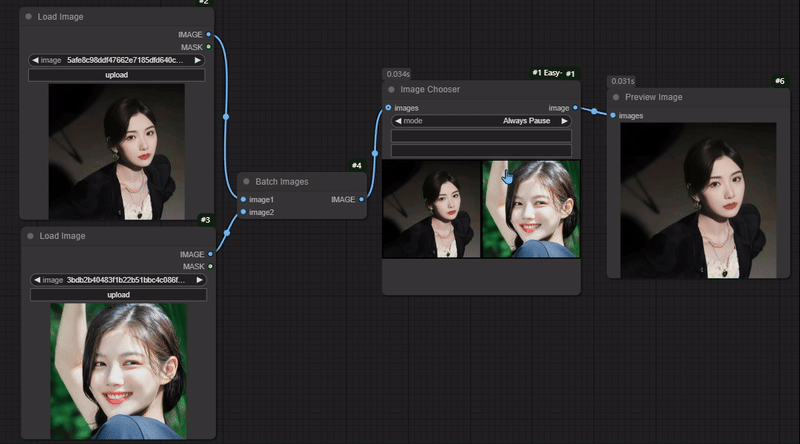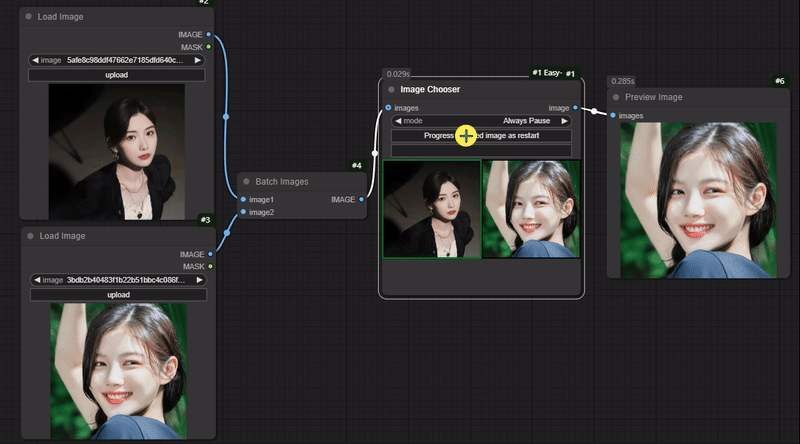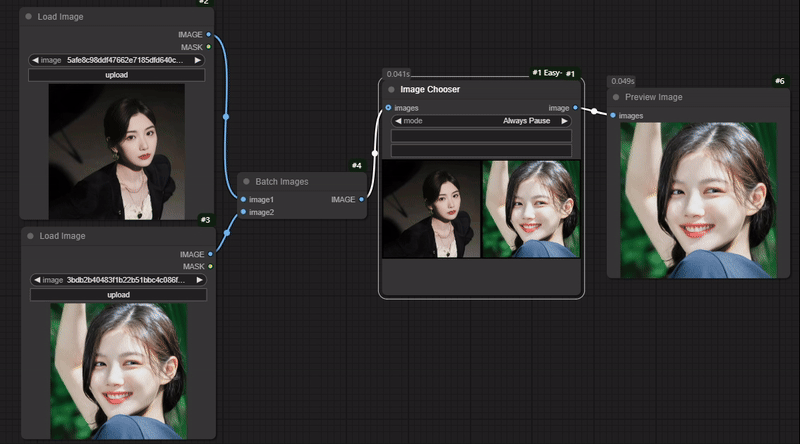
节点功能:选择输入的多个图片中的一张进行下一步传输 输入:
输入:
images -> 输入的多张图片
参数:
mode -> 选择模式,分为Always Pause(总是暂停)和(Keep Last Selection(保持上一个选择)
Progress selected image -> 在选择下面的多张图片中的一张后,点击此按键来完成选择图片
Cancel current run -> 取消当前运行
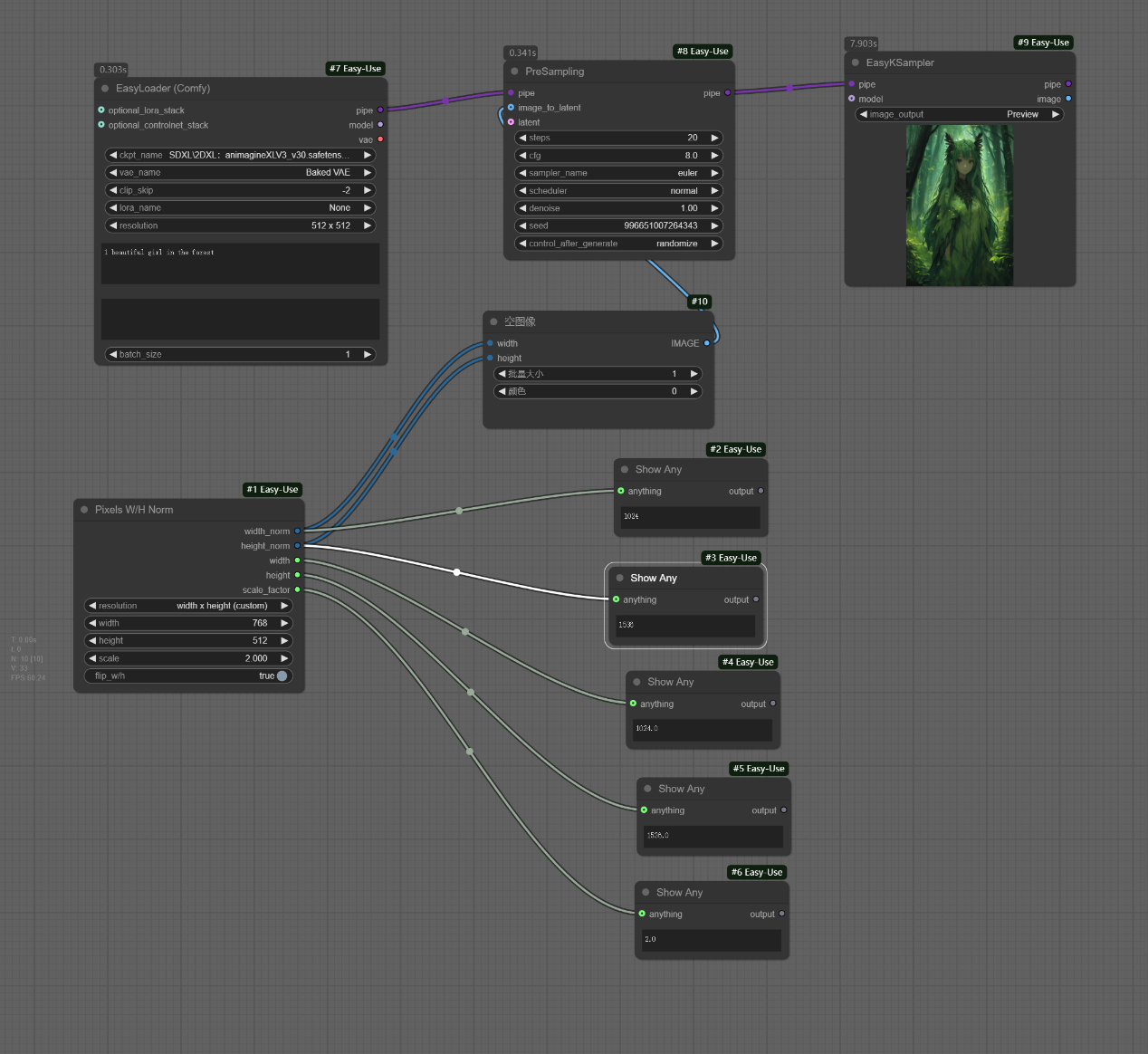
十、Pixels W/H Norm节点
节点功能:提供预设图片的宽高和比例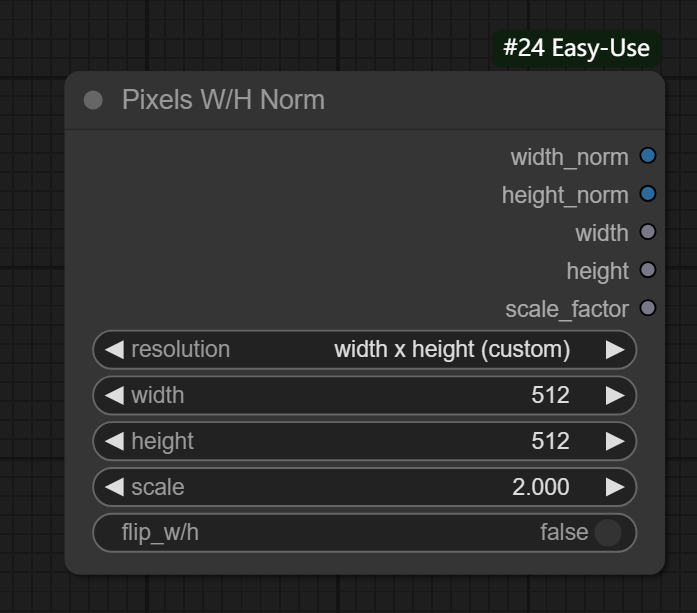
参数:
resolution -> 可选择的图片分辨率,可自己设置,也可以选择提供中的
width -> 设置在自设置情况下的图片的宽
height -> 设置在自设置情况下的图片的高
scale -> 设置图片将要放大的比例
flip_w/h -> 是否翻转现有的宽高
输出:
width_norm -> 输出图片的宽的整数值
height_norm -> 输出图片的高的整数值
width -> 输出图片的宽的小数值
height -> 输出图片的高的小数值
scale_factor -> 输出图片宽高的比例值
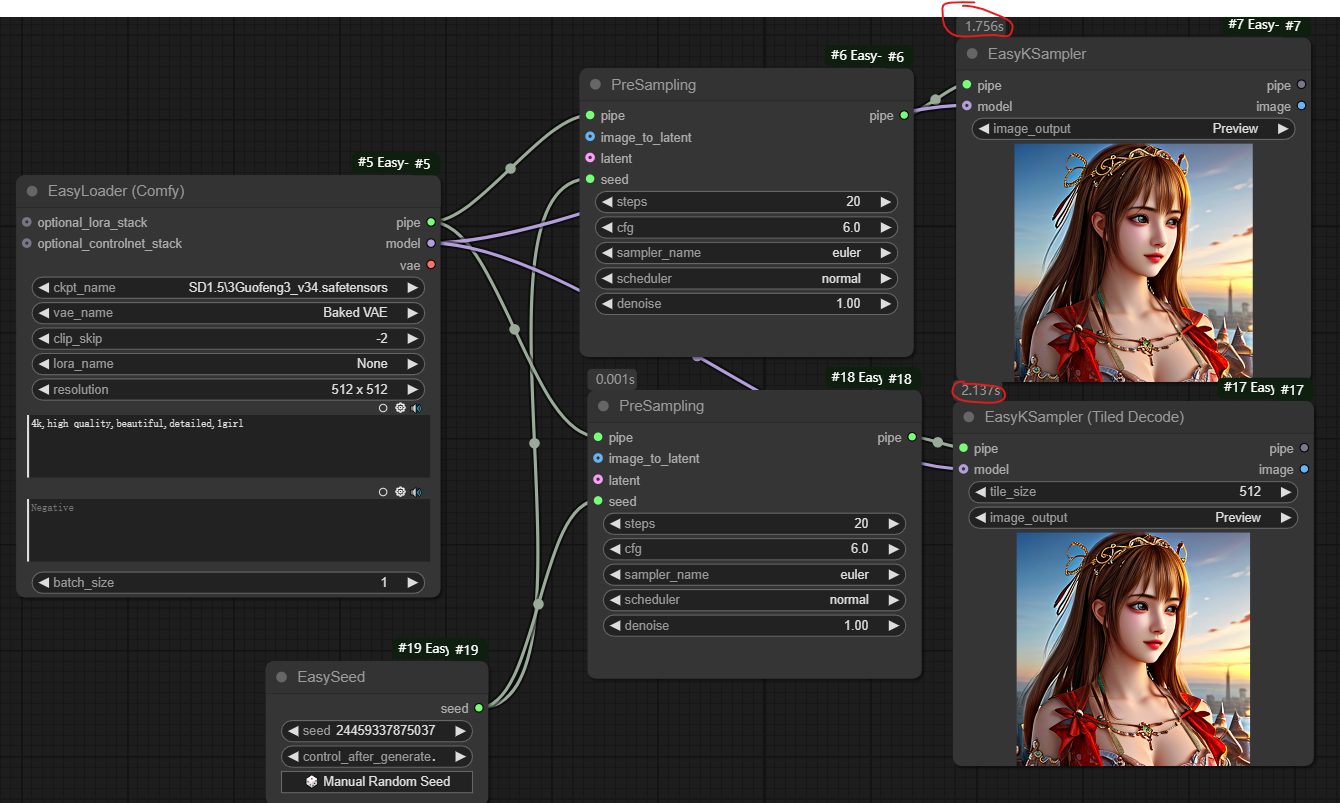
十一、EasyKSampler (Tiled Decode)节点
节点功能:提供分块解码的K采样器 ,适用在生成图片比较大的情况下用来减少显存的使用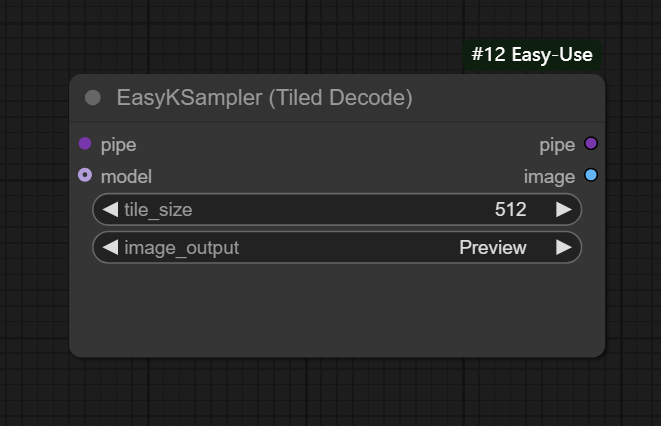 输入:
输入:
pipe -> 输入的管道
model -> 输入的模型
参数:
tile_size -> 设置分块解码的每块大小
image_output -> 设置图片输出的方式,一般选择Preview或Save
输出:
pipe -> 输出调节参数后的管道
image -> 输出解码后的图片
从下图可以看到使用分块解码占用内存会更少,但运行时间变慢。
__ComfyUI Easy Use插件(一): __https://articles.zsxq.com/easyuse/1.html
__ComfyUI Easy Use插件(二): __https://articles.zsxq.com/easyuse/2.html
__ComfyUI Easy Use插件(三): __https://articles.zsxq.com/easyuse/3.html
__ComfyUI Easy Use插件(四): __https://articles.zsxq.com/easyuse/4.html
__ComfyUI Easy Use插件(五): __https://articles.zsxq.com/easyuse/5.html
__ComfyUI Easy Use插件(七): __https://articles.zsxq.com/easyuse/7.html
__ComfyUI Easy Use插件(八): __https://articles.zsxq.com/easyuse/8.html
