【ComfyUI插件】ComfyUI Easy Use插件(八)
前言:
该插件由B站大佬乱乱呀AI进行开发出来的,此插件主要在使用管道、简化工作流、提供简便工具和集成化等方面起到了明显作用。
目录
先行:安装方法
一、Portrait Master节点
二、PreSampling (DynamicCFG)节点
三、InjectNoiseToLatent节点
四、Pipe Edit Prompt节点
五、Math String节点
六、Image Detail Transfer节点
七、Easy Apply ICLight节点
八、Math Float/Convert Any节点
九、LatentCompositeMaskedWithCond节点
十、If else节点
__ComfyUI Easy Use插件(一): __https://articles.zsxq.com/easyuse/1.html
__ComfyUI Easy Use插件(二): __https://articles.zsxq.com/easyuse/2.html
__ComfyUI Easy Use插件(三): __https://articles.zsxq.com/easyuse/3.html
__ComfyUI Easy Use插件(四): __https://articles.zsxq.com/easyuse/4.html
__ComfyUI Easy Use插件(五): __https://articles.zsxq.com/easyuse/5.html
__ComfyUI Easy Use插件(六): __https://articles.zsxq.com/easyuse/6.html
__ComfyUI Easy Use插件(七): __https://articles.zsxq.com/easyuse/7.html
本期使用的示例工作流在网盘:小黄瓜知识星球资料分享/插件节点讲解视频/ComfyUI_EasyUse/第八期文件夹中
安装方法
安装方法,一共有2种
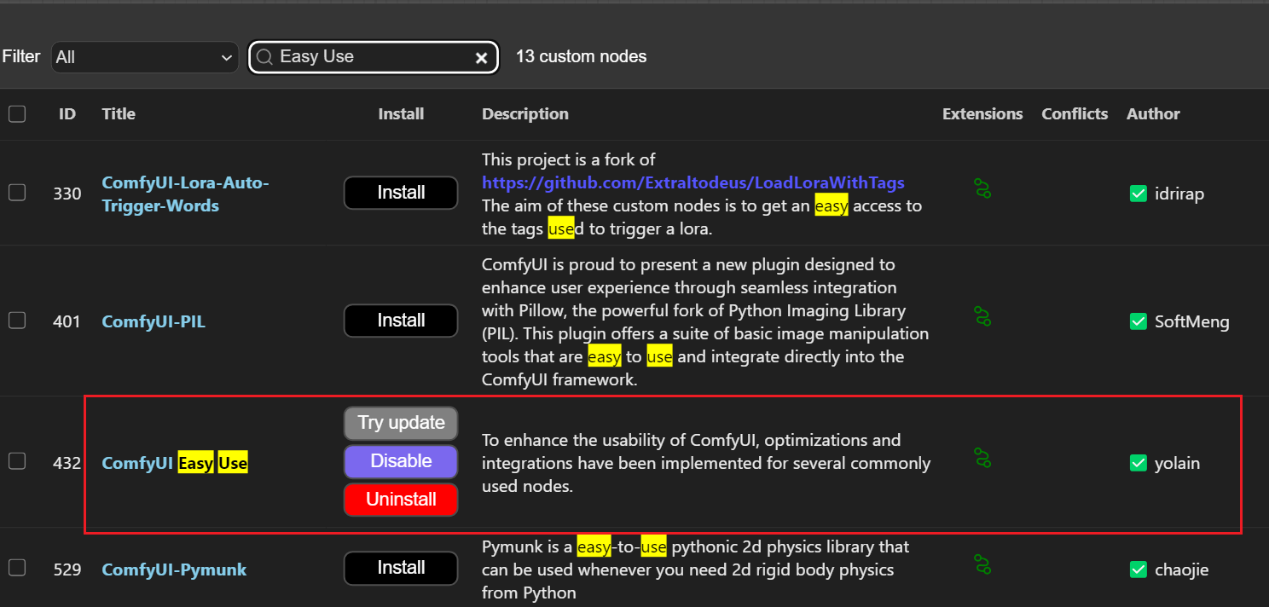
1、在manager里搜索Easy Use,然后点击安装第3个即可
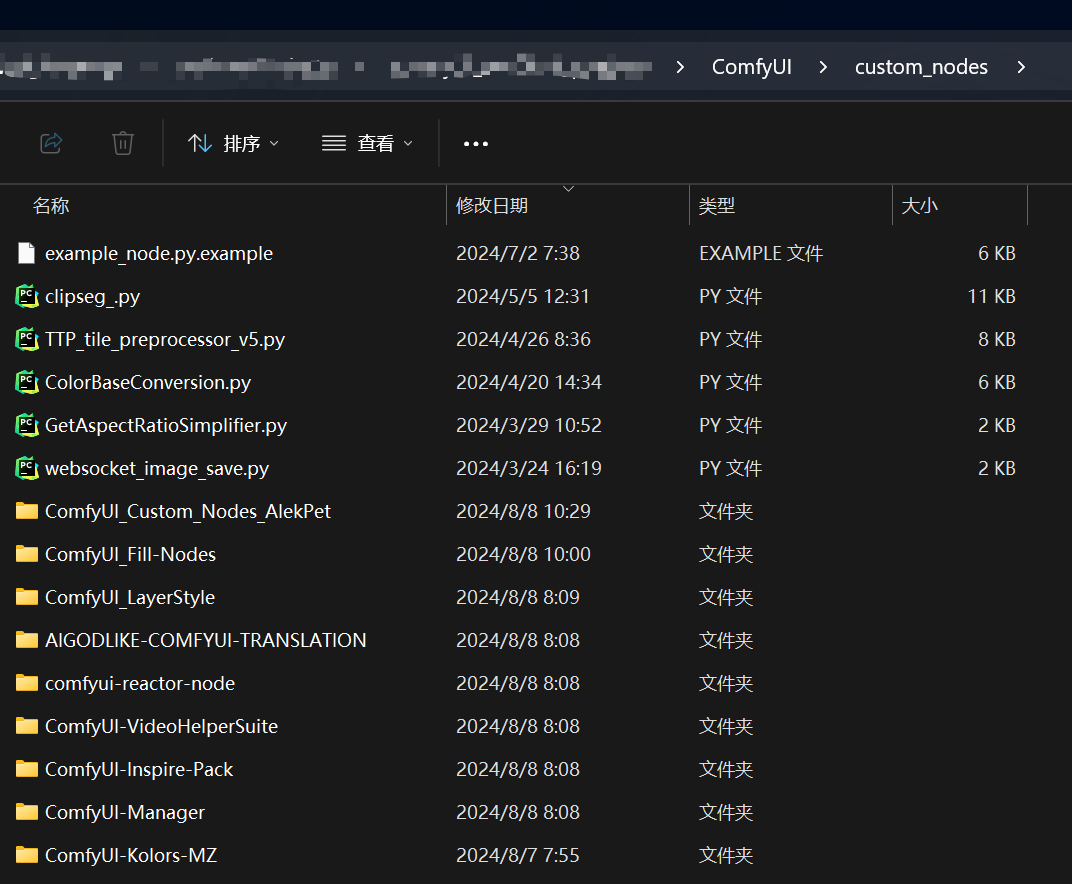
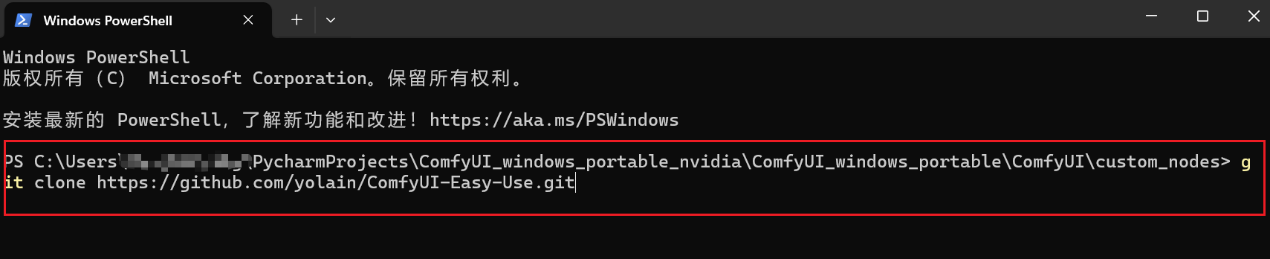
__2、在custom_nodes目录下调用cmd,然后输入git clone __https://github.com/yolain/ComfyUI-Easy-Use.git
项目地址:https://github.com/yolain/ComfyUI-Easy-Use.git
一、Portrait Master节点
节点功能:提供各种肖像参数来输出关于人物肖像的正向和负向提示词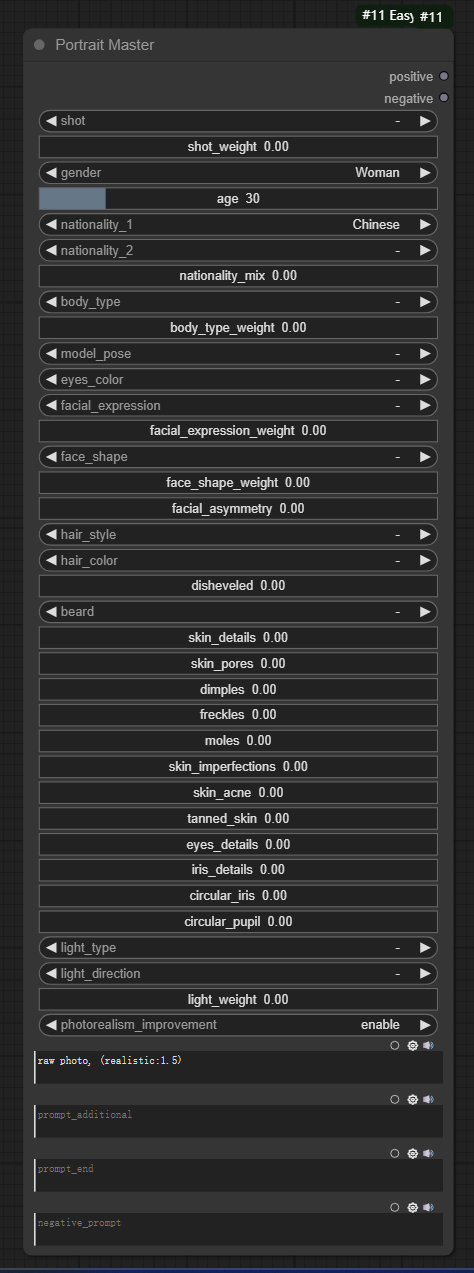
参数:
shot:设置镜头,分为-(空)、Head portrait(头像)、Head and shoulders portrait(头肩肖像)、Half-length portrait(半身像)、Full-length portrait(全身像)、Face(脸部)、Portrait(肖像)、Full body(全身)、Close-up(特写)
shot_weight:设置镜头提示词权重
gender:设置性别,分为-(空)、Man(男人)、Woman(女人)
age:设置年龄
nationality_1:设置国籍1,按需选择即可
nationality_2:设置国籍2,按需选择即可
nationality_mix:设置两个国籍的混合比例
body_type:设置人的体态
body_type_weight:设置人的体态的权重
model_pose:设置模特姿势,
eyes_color:设置眼睛颜色,
facial_expression_weight:设置脸部表情权重
face_shape:设置脸型
face_shape_weight:设置脸型权重
facial_asymmetry:设置面部不对称权重
hair_style:设置发型,按需选择即可
hair_color:设置头发颜色
disheveled:设置头发蓬松权重
beard:设置胡须,按需选择即可
skin_details:设置皮肤细节权重
skin_pores:设置皮肤毛孔权重
dimples:设置酒窝权重
freckles:设置雀斑权重
moles:设置痣权重
skin_imperfections:设置皮肤瑕疵权重
skin_acne:设置皮肤痤疮权重
tanned_skin:设置晒黑皮肤权重
eyes_details:设置眼部细节权重
iris_details:设置虹膜细节权重
circular_iris:设置圆形虹膜权重
circular_pupil:设置圆形瞳孔权重
light_type:设置灯光类型,按需选择即可
light_direction:设置灯光方向
light_weight:设置灯光权重参数
photorealism_improvement:设置照片现实感是否增强
prompt_start:设置开始处的正向提示词
prompt_additional:设置额外的正向提示词
prompt_end:设置结束处的正向提示词
negative_prompt:设置负向提示词
输出:
positive:输出正向提示词
negative:输出负向提示词
这个工作流主要就是根据适当的选项,解决用户在编写肖像提示词的细节难点。该节点其实还是作为填充提示词的节点。
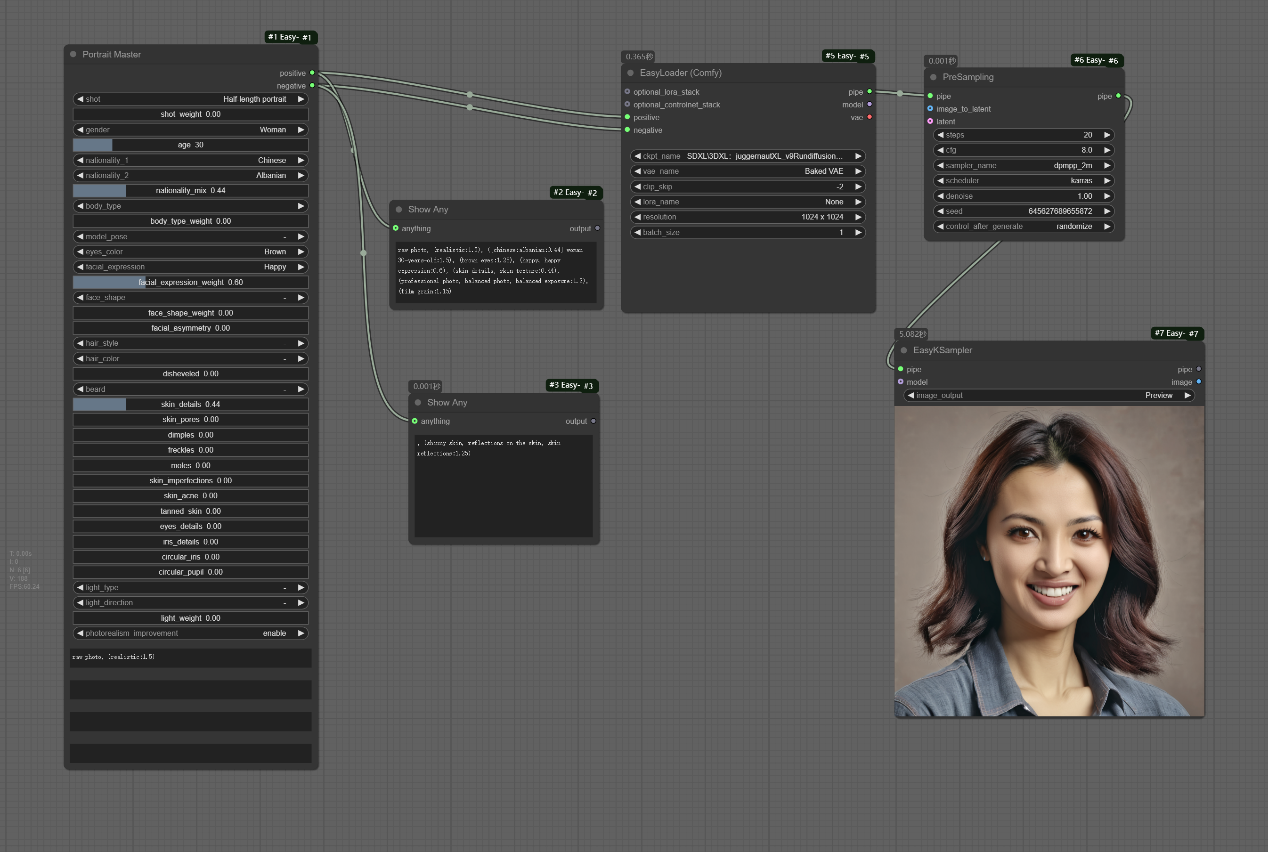
二、PreSampling (DynamicCFG)节点
__节点功能:提供动态调节提示词引导系数的预采样器 __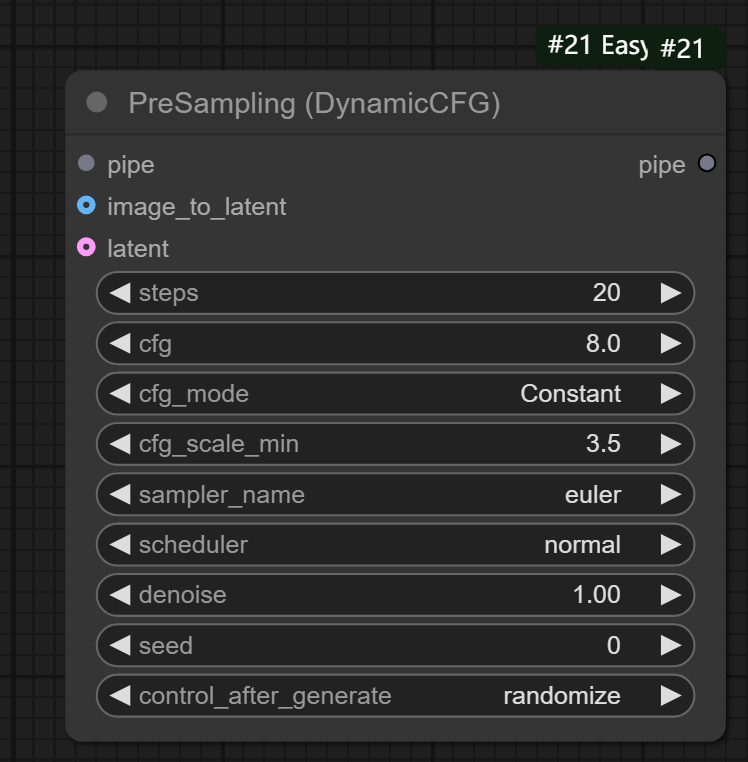 输入:
输入:
pipe:输入的管道
image_to_latent:输入的图片,用来编码成潜空间图片
latent:输入的潜空间图片
参数:
steps:设置采样步数
cfg:设置提示词引导系数
cfg_mode:设置提示词引导系数变化的模式,分为Constant(恒定)、Linear Down(线性下降)、Consine Down(余弦下降)、Half Consine Down(半余弦下降)、Linear Up(线性上升)、Cosine Up(余弦上升)、Half Cosine Up(半余弦上升)、Power Up(升高)、Power Down(下降)、Linear
Repeating(线性重复)、Cosine Reapeating(余弦重复)、Sawtooth(锯齿波形)
cfg_scale_min:设置提示词引导系数的最小值
sampler_name:设置的采样器名字
scheduler:设置的调度器名字
denoise:设置的降噪强度
seed:设置的种子数
control_after_generate:设置的种子数生成模式,分为randomize(随机)、fixed(固定)、decrement(减少)和increment(增加)
输出:
pipe:输出设置完参数后的管道
该工作流主要对于不同cfg模式下产生的效果进行对比,可以根据实际需求进行选择,一般来说选择__Half Cosine Up__(半余弦上升)比较常见
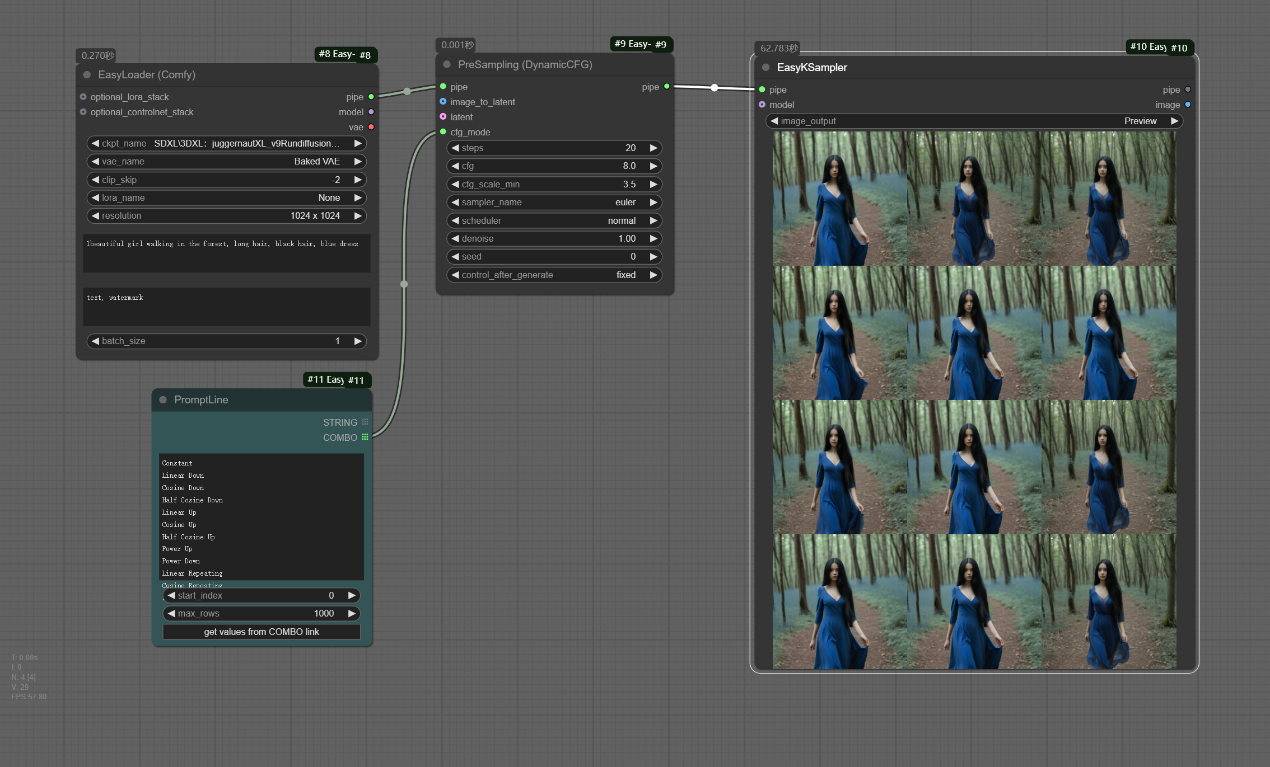
三、InjectNoiseToLatent节点
__节点功能:注入噪声到潜空间 __
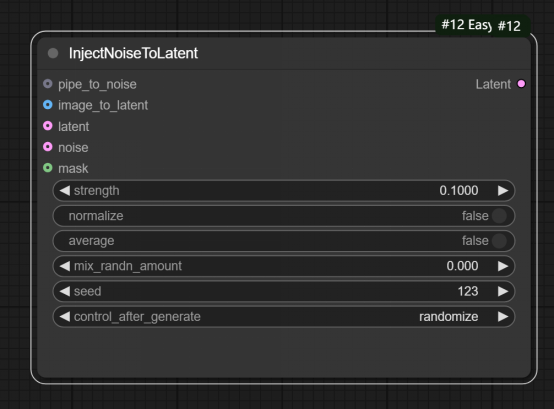
输入:
pipe_to_noise:输入的管道,用来提供噪声
image_to_latent:输入的图片,用来编码成潜空间图片
latent:输入的潜空间图片、
noise:输入噪声
mask:输入的蒙版
参数:
strength:设置注入的噪声的强度
normalize:设置注入的噪声是否归一化处理,影响结果潜空间噪声的分布
average:设置原始噪声和注入噪声是否进行平均处理,可能获得更平滑的结果
mix_randn_amout:设置混合到潜空间噪声中随机噪声量,引入额外变量
seed:设置种子数
control_after_generate:设置的种子数生成模式,分为randomize(随机)、fixed(固定)、decrement(减少)和increment(增加)
输出:
latent:输出注入完噪声后形成的潜空间图片
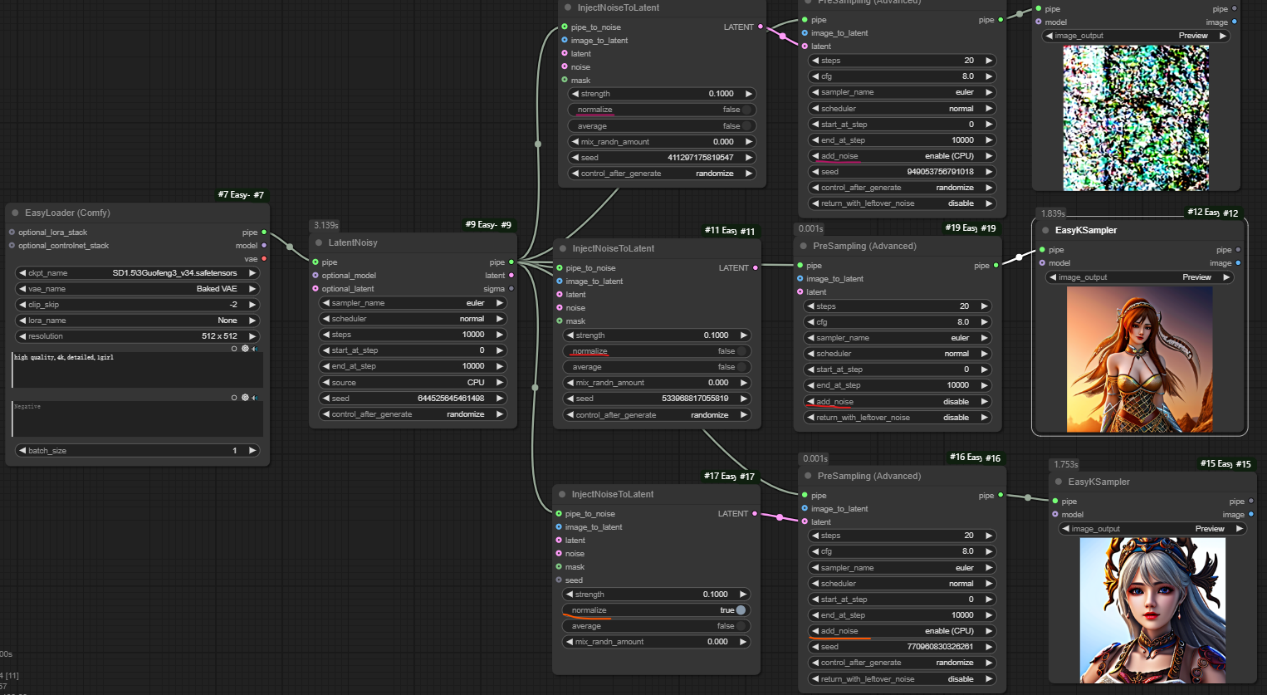
通过如下工作流,可以看出如果__normalize__选择为否,则需要在预采样器里选择__add_noise__为disable,且采样步数适当增大,否则会出现噪声过大无法去除干净的情况;如果__normalize__选择为是,则需要在预采样器里选择__add_noise__为enable,才能生成不错的图片。
四、Pipe Edit Prompt节点
节点功能:提供修改提示词的管道节点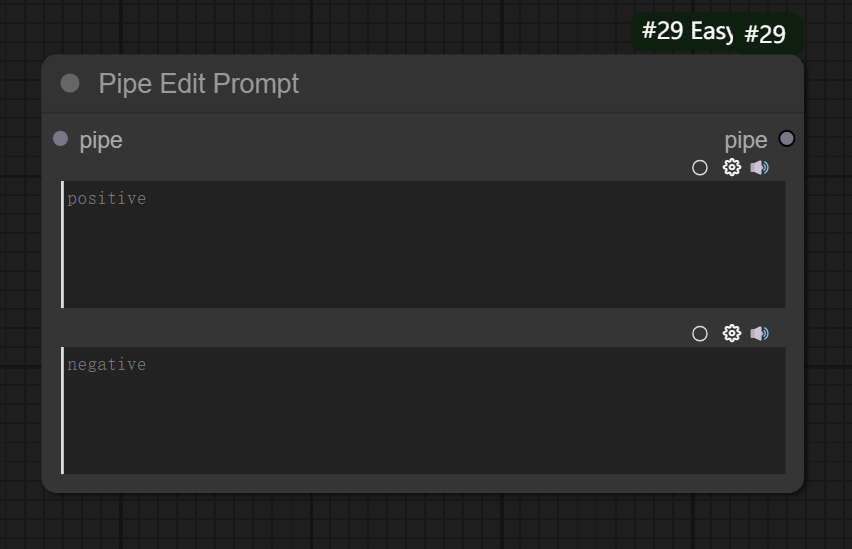 输入:
输入:
pipe:输入的管道
参数:
positive:设置的正向提示词
negative:输入的负向提示词
输出:
pipe:输出修改完提示词后的管道
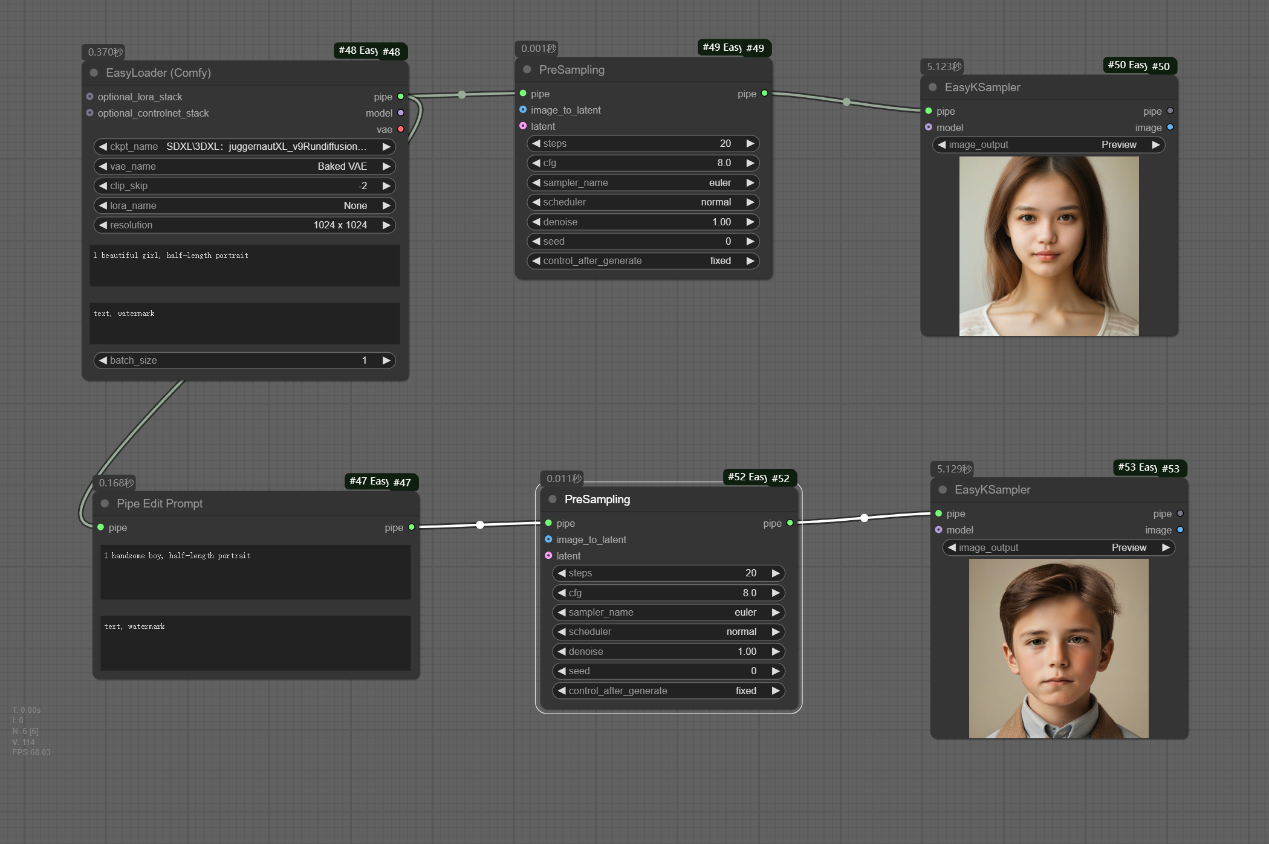
该工作流主要使用Pipe Edit Prompt节点去修改中间提示词,以此来实现同一模型加载器下不同提示词效果的呈现
五、Math String节点
__节点功能:提供了字符串的数学操作 __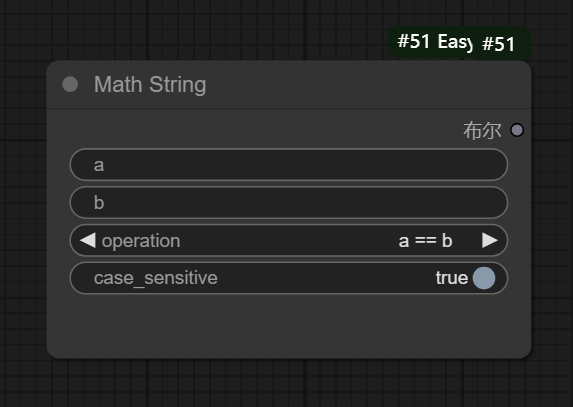
参数:
a:输入的字符串a
b:输入的字符串b
operation:使用的判断两个字符串的操作,分为a==b(两个字符串完全相同)、a!=b(字符串a和字符串b不一样)、a IN b(字符串a是字符串b的一部分)、a MATCH REGEX(b)(字符串a是否匹配字符串b的模式)、a BEGINSWITH b(字符串a是否以字符串b为开头)、a ENDSWITH b(字符串a是否以字符串b为结尾)
case_sensitive:字符串a和b匹配是否严格区分大小写,true代表区分大小写,false代表不区分大小写
输出:
boolean:输出判断后的结果,分为true或false
该工作流展示了Math String的在不同判断条件下的结果
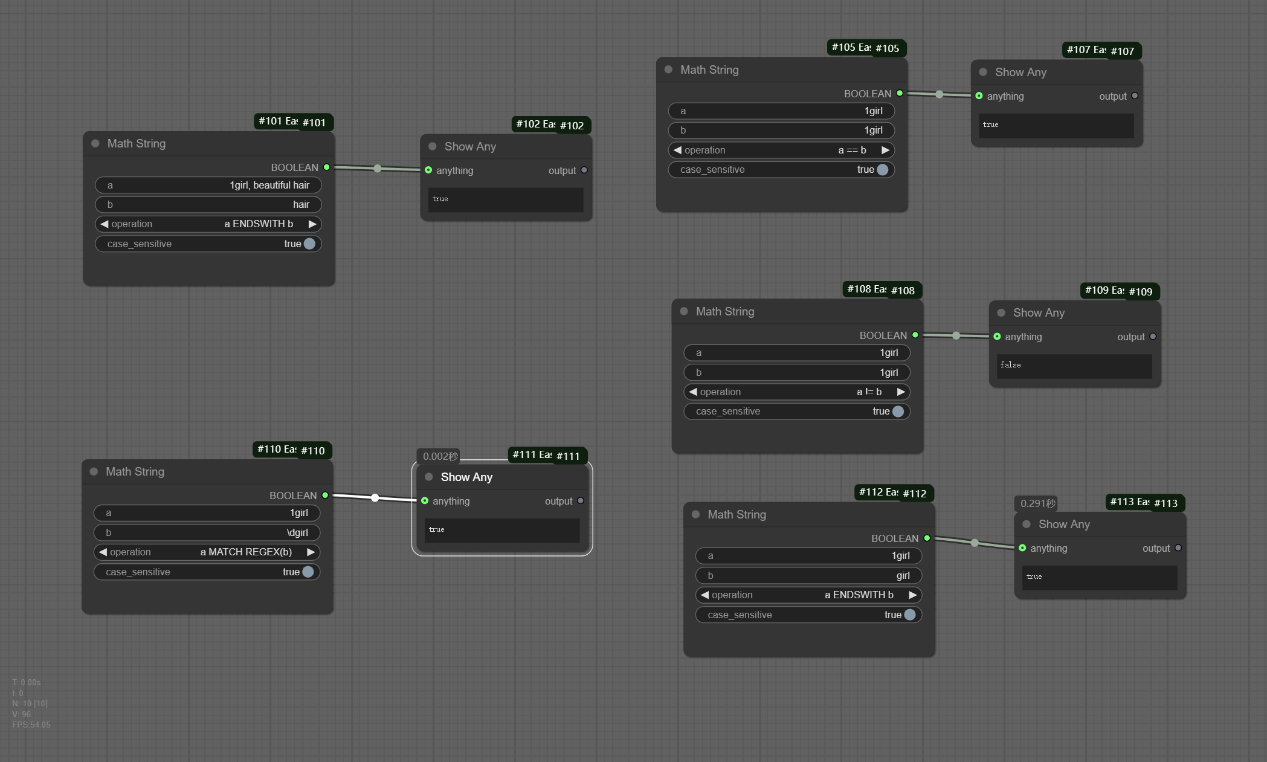
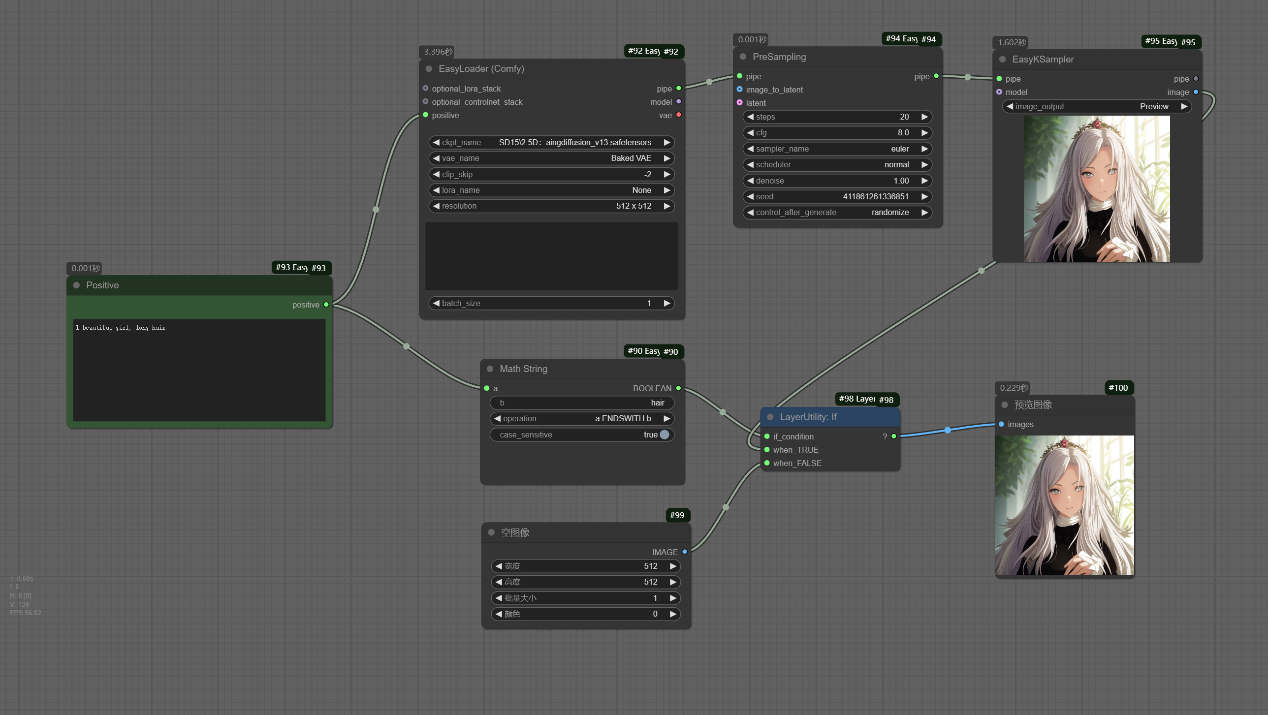
该工作流以提示词中是否以hair结尾进行判断,如果是true则生成对应图片,false则生成512x512的空白图片
六、Image Detail Transfer节点
节点功能:将源图片的细节迁移到目标图片上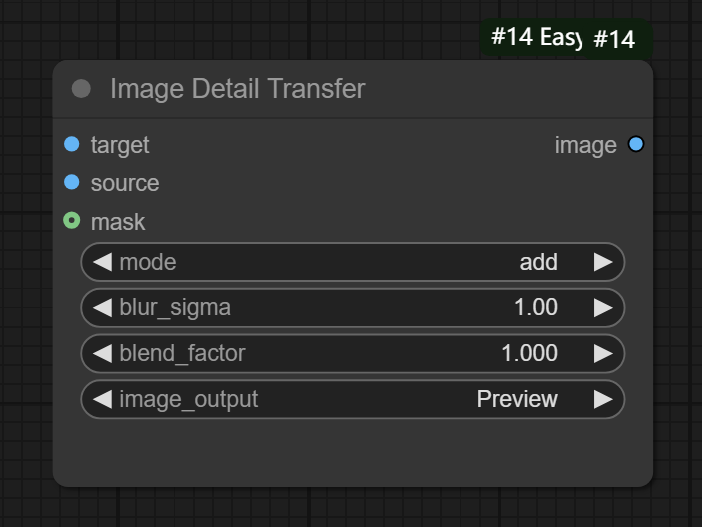 __
__
输入:__
target:输入的目标图片
source:输入的源图片
mask:输入的提取源图片细节的蒙版部分
参数:
mode:设置2张图片细节迁移的方式,
- add(将源图像的高频细节添加到目标图像上)
- multiply(将源图像与目标图像的模糊版本相乘)
- screen(multiply的反向操作)
- overlay(结合multiply和screen)
- soft_light(类似overlay,但效果更柔和)
- hard_light(类似overlay,效果由源图片亮度决定)
- color_dodge(减少目标图像的亮度)
- difference(比较2者差异)
- exclusion(类似于difference,但对比度较低)
- divide(2者相除来调节目标图片)具体差别可以看工作流
blend_factor:设置混合参数,0代表与源图片无混合,一般设置在0.75及以上1.5以下
image_output:设置图片输出
输出:
image:输出细节迁移后的图片
该工作流显示__blend_factor__在0、0.75、2、10下的效果对比,通过对比可以看出blend factor一般设置在0.75到1.5期间效果较好
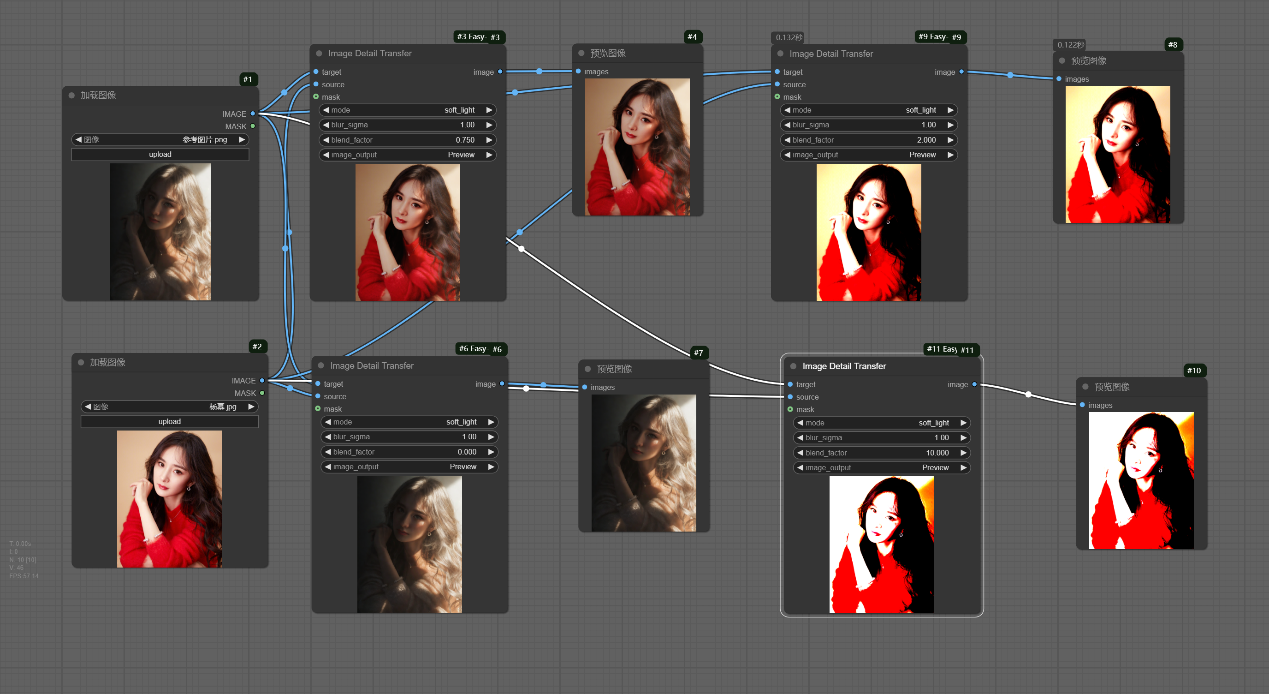
__
该工作流实现了对打光后的图片实施细节迁移的全体效果展示,其中可以看出__overlay、soft_light、__hard_light__模式下迁移效果较好。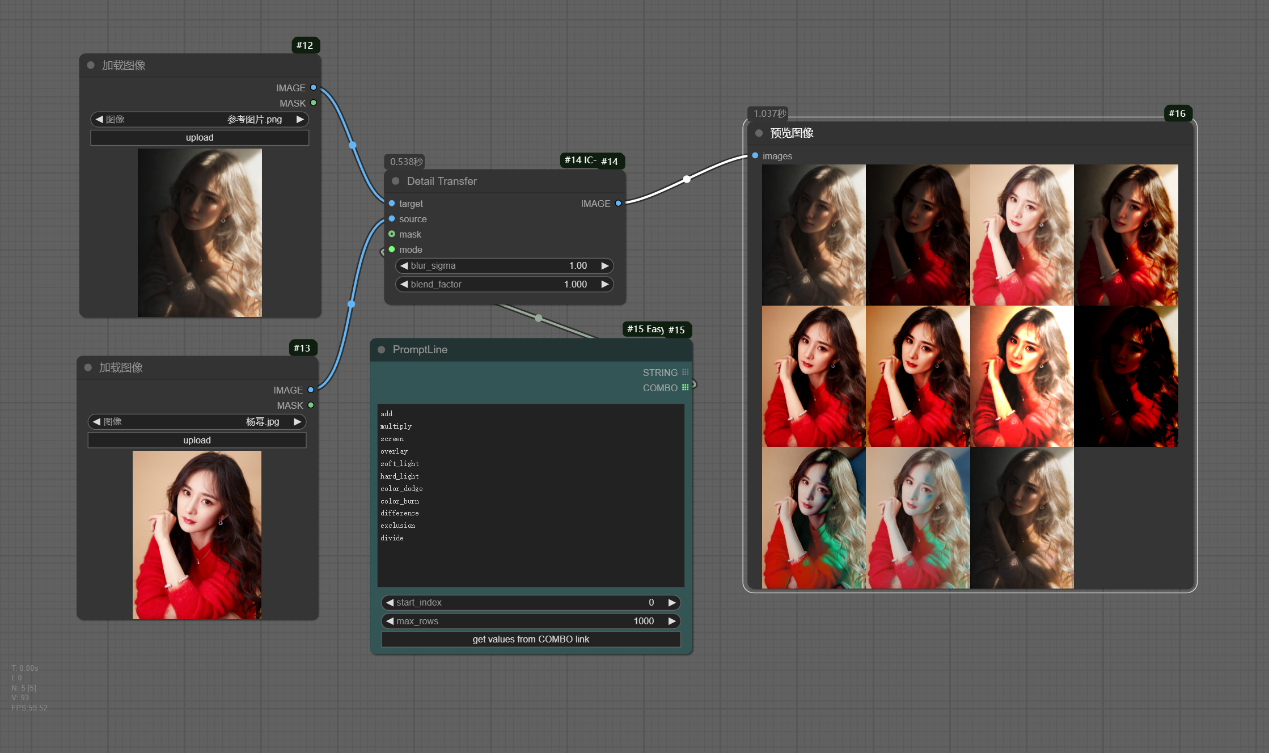
七、Easy Apply ICLight节点
节点功能:提供光线调节的Iclight节点,只适用SD1.5模型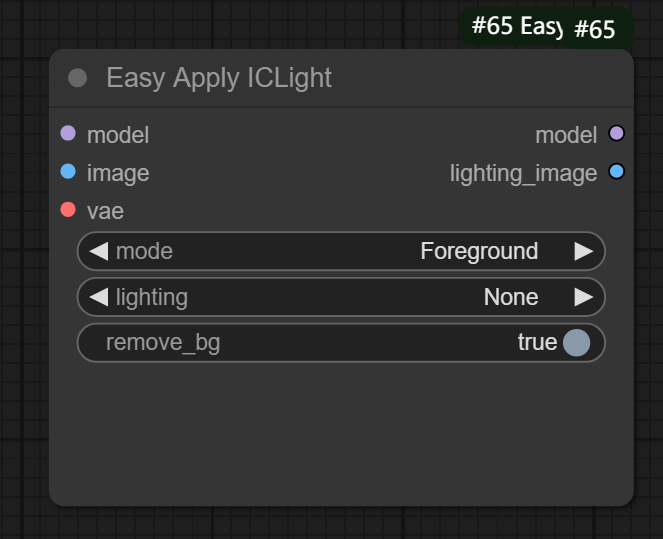
输入:
model:输入的SD1.5模型
image:输入的图片
vae:输入的vae模型
参数:
mode:使用的模式,分为Foreground(前景,根据设置灯光调节)和Foreground&Background(前景和背景,根据输入背景图片的光源作为参考灯光)
lighting:设置灯光打到的位置,分为None(无)、Left Light(左边)、Right Light(右边)、Top Light(上面)、Bottom Light(下面)、Circle Light(圆形灯光)
remove_bg:是否移除背景
输出:
model:输出调节后的模型
lighting_image:输出打光图片
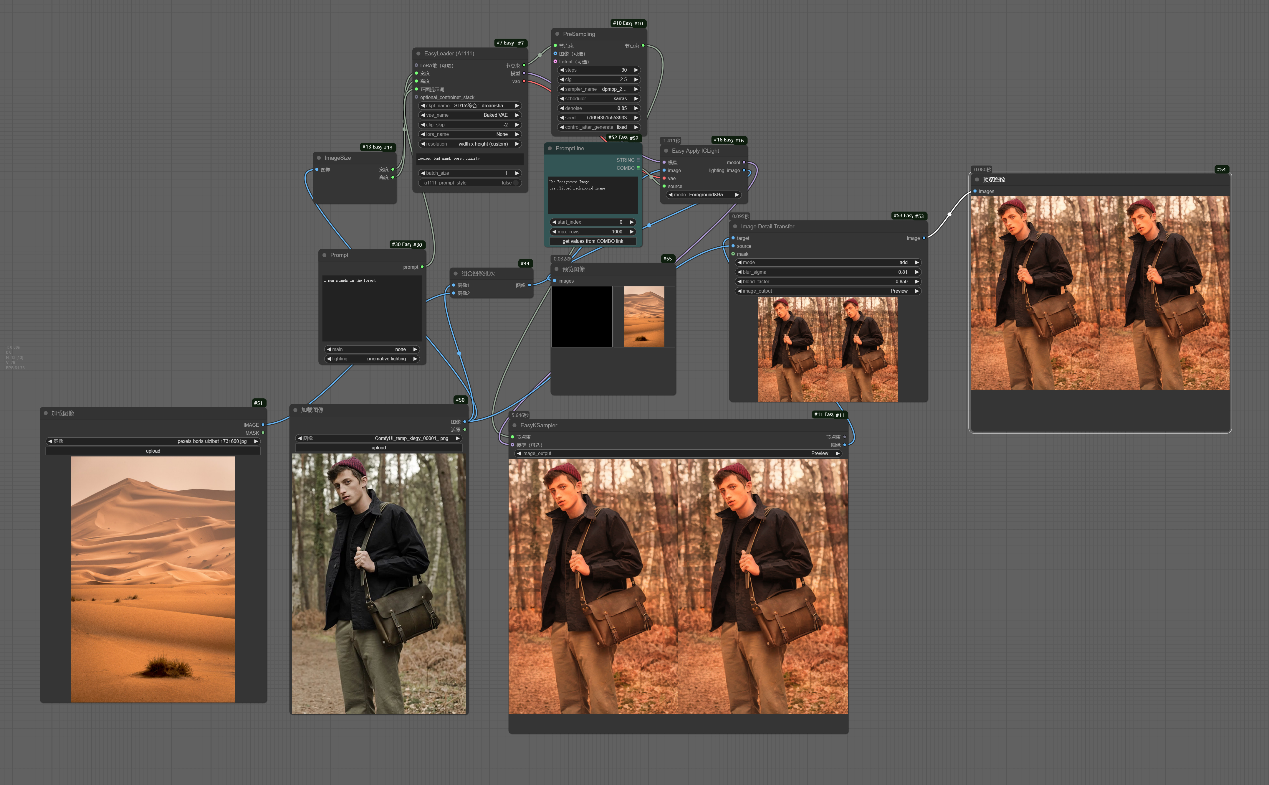
__前景工作流图片版:__该工作流主要使用了不同的打光场景对原有图片进行新的打光处理,使新生成的图片的光源效果与对应使用的打光图片一致。随后由于新生成的图片改变了原有图片的细节和色调,所以通过__Image Detail Transfer节点__把原有图片的细节迁移到打光后的图片,使新生成的图片细节高度和原有图片一致。
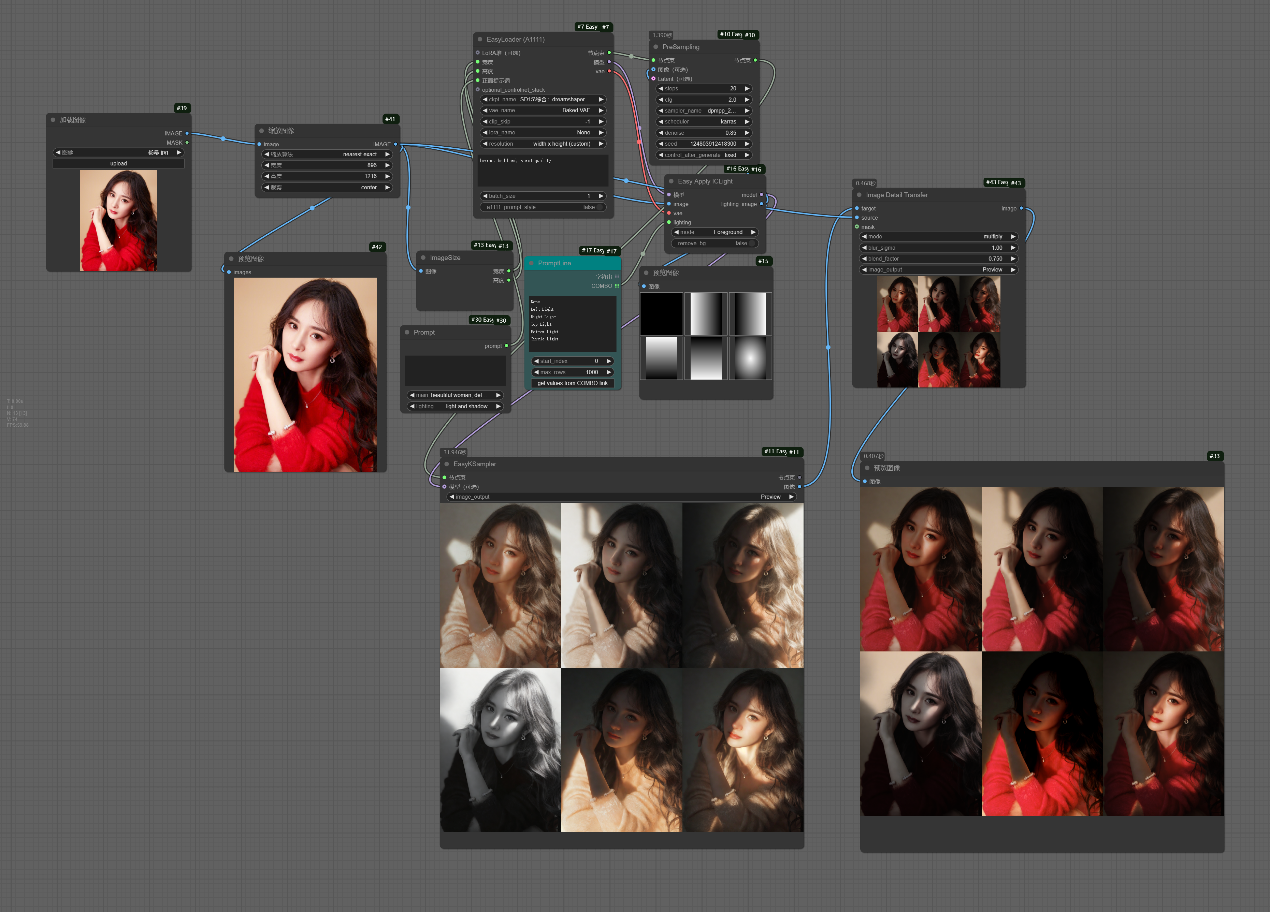
__前景与背景工作流图片版:__该工作流主要与前面不同的点在于使用了自己提供的图片作为打光参考图片,生成了自提供图片的原始状态与翻转状态(左右翻转)两种情况作为打光参考图片的结果
八、Math Float/Convert Any节点
节点功能:提供了浮点数的数学操作/转换所有类型
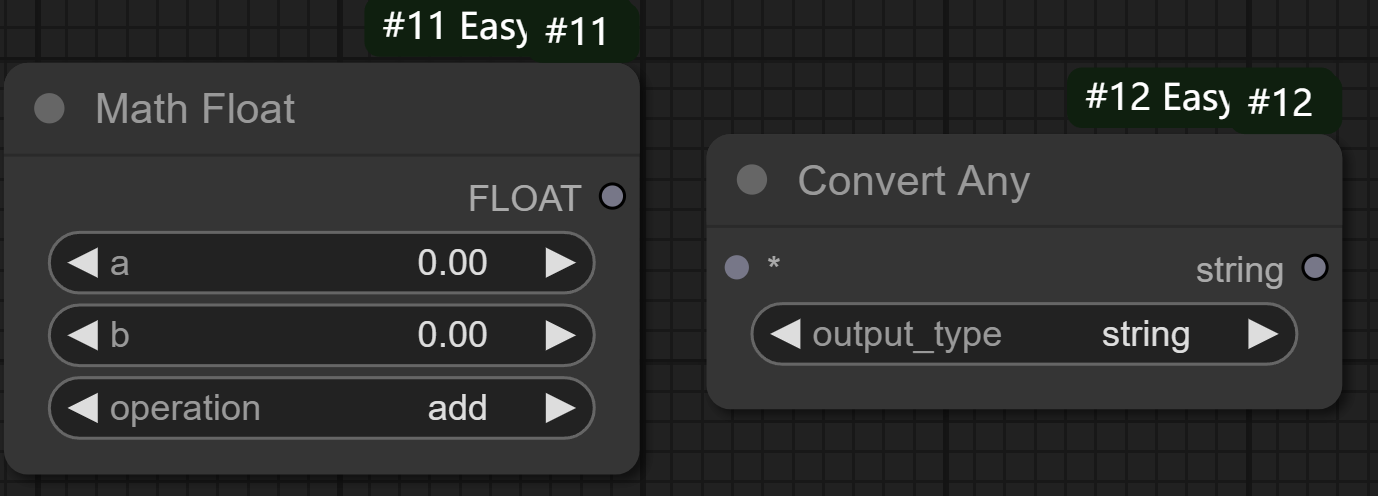
节点1参数:
a:输入的浮点数a
b:输入的浮点数b
operation:设置使用的浮点数a和b的计算,分为add(加法)、subtract(相减)、multiply(相乘)、divide(相除)、modulo(取模,也就是取余数)、power(幂运算)
节点1输出:
FLOAT:输出计算完后的结果
节点2输入:
any:输入的要转换的数据
节点2参数:
output_type:设置转换后的数据类型,分为string、int、float和boolean
节点2输出:
any:输出转换为类型的数据
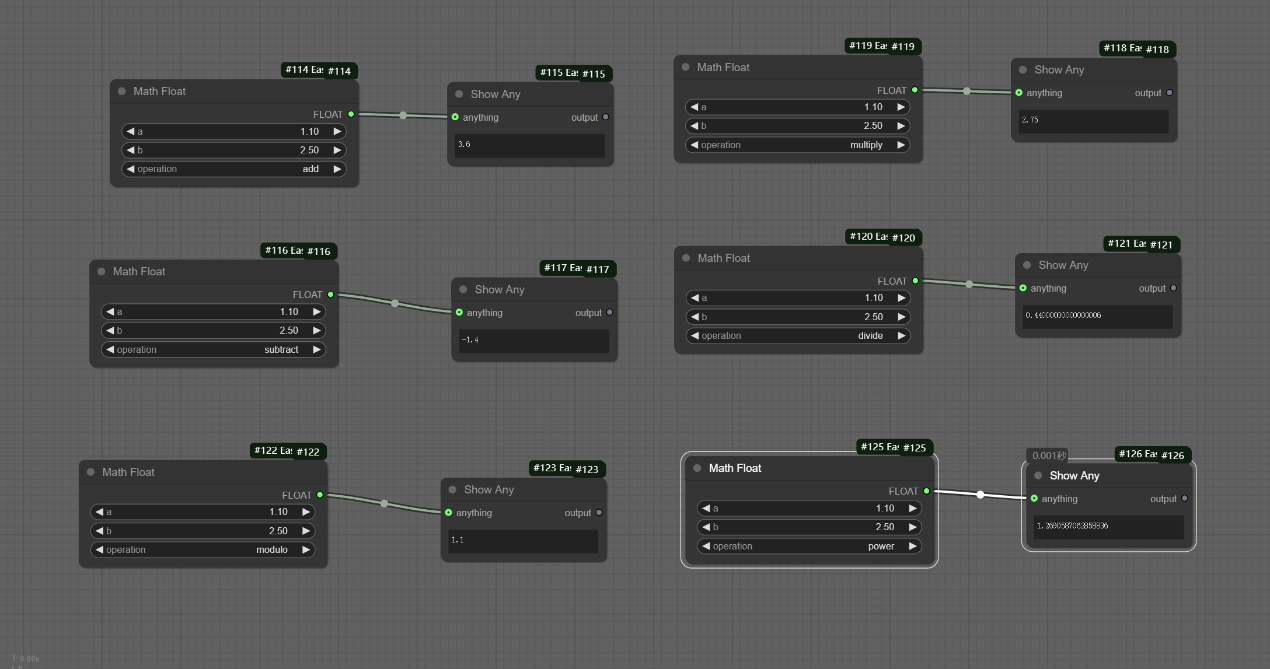
该工作流展示了Math Float的基础运算
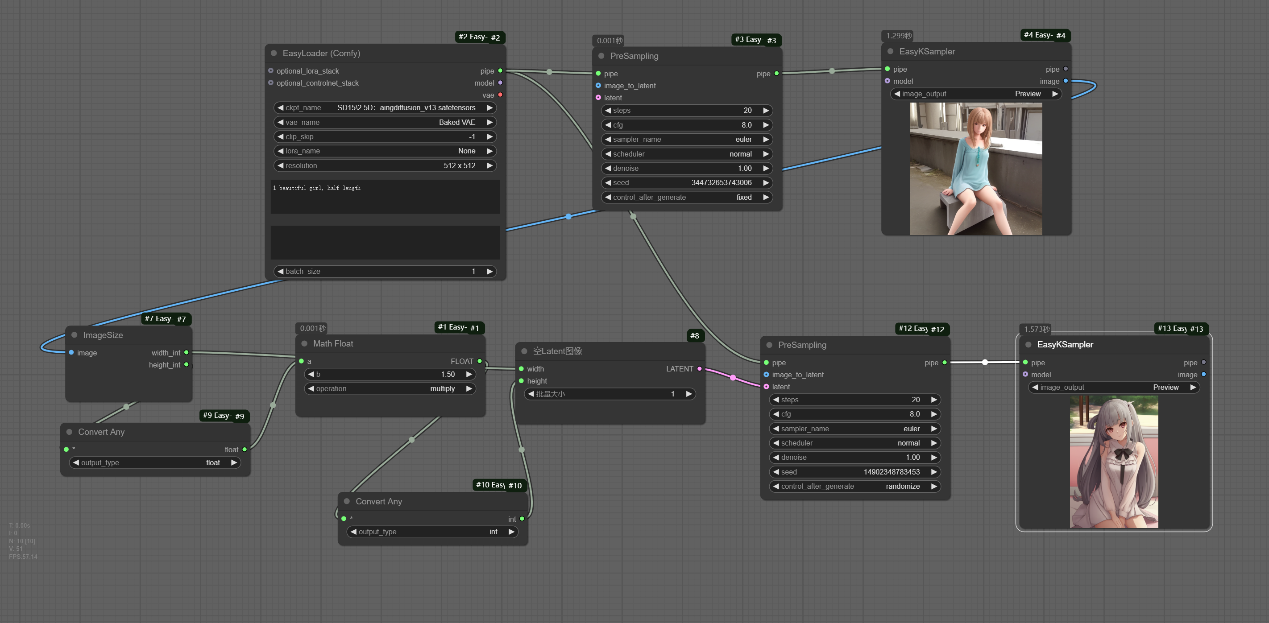
该工作流实现了在相同提示词条件下,将第一次图片的高的1.5倍作为第二次图片的高来生成第二次的图片的效果
九、LatentCompositeMaskedWithCond节点
__节点功能:提供不同文本组合与蒙版结合进行输出 __
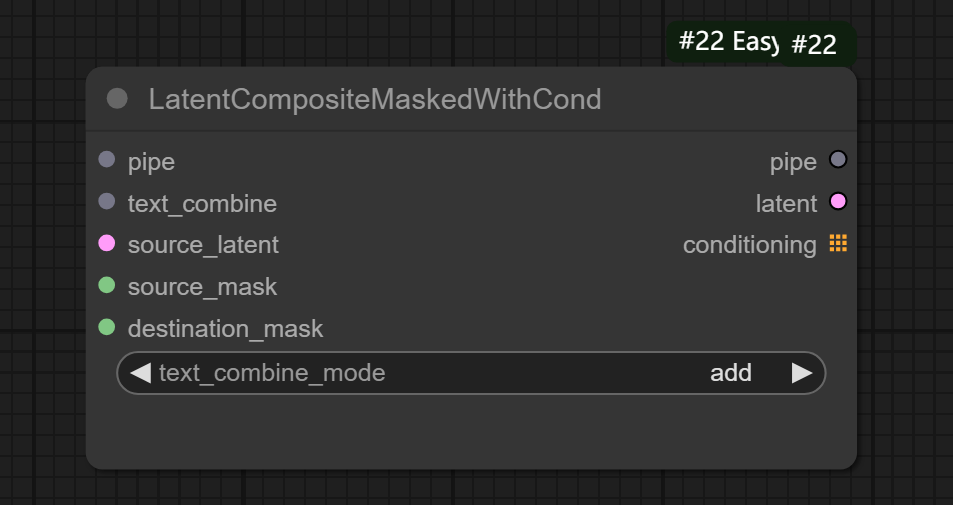
输入:
pipe:输入的管道
text_combine:设置的文本列表,一般与PromptList节点连用来实现不同文本组合条件的输出
source_latent:原始潜空间图片
source_mask:设置初始的提示词条件作用在原始潜空间图片上的蒙版
这里可以提供加载图片的整张图片全涂抹后的白色或黑色蒙版作为蒙版
destination_mask:设置初始的提示词与文本列表中的提示词组合后
作用在原始潜空间图片上的蒙版
参数:
text_combine_mode:设置的文本组合方式,分为add(相加)、replace(替换)、cover(覆盖)三种
输出:
pipe:输出的管道
latent:输出的潜空间图片,这里目前输出的是原始潜空间图片
conditioning:输出的文本结合后的正向条件
add__主要是根据不同文本与原始提示词组合然后作用到目标蒙版区域的效果,其中原始提示词作用到__source_mask,组合后的提示词作用到__destination mask__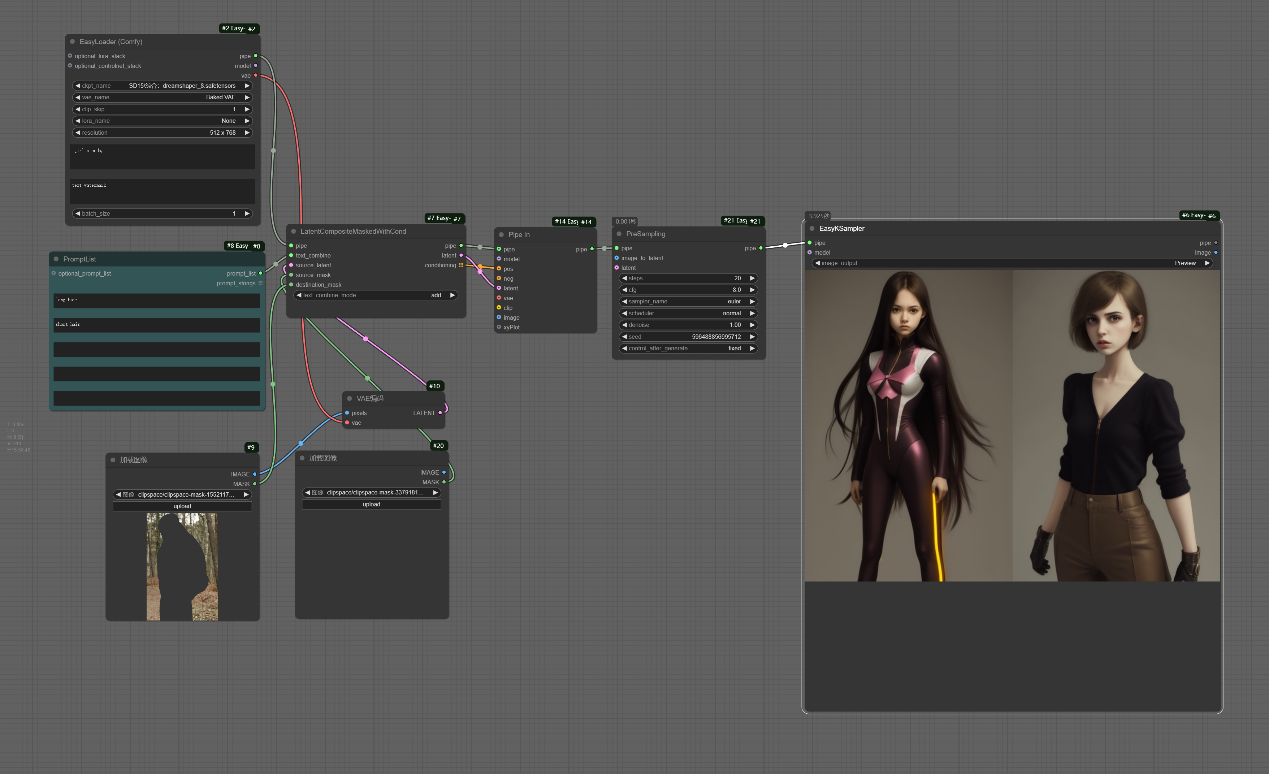
在使用__replace__模式时,其中输入的__replace_text__会以__PromptList__中的提示词替换掉__Loader__中相同的词,如下图,其中的__a__就分别替换成了__stone__和__grass__。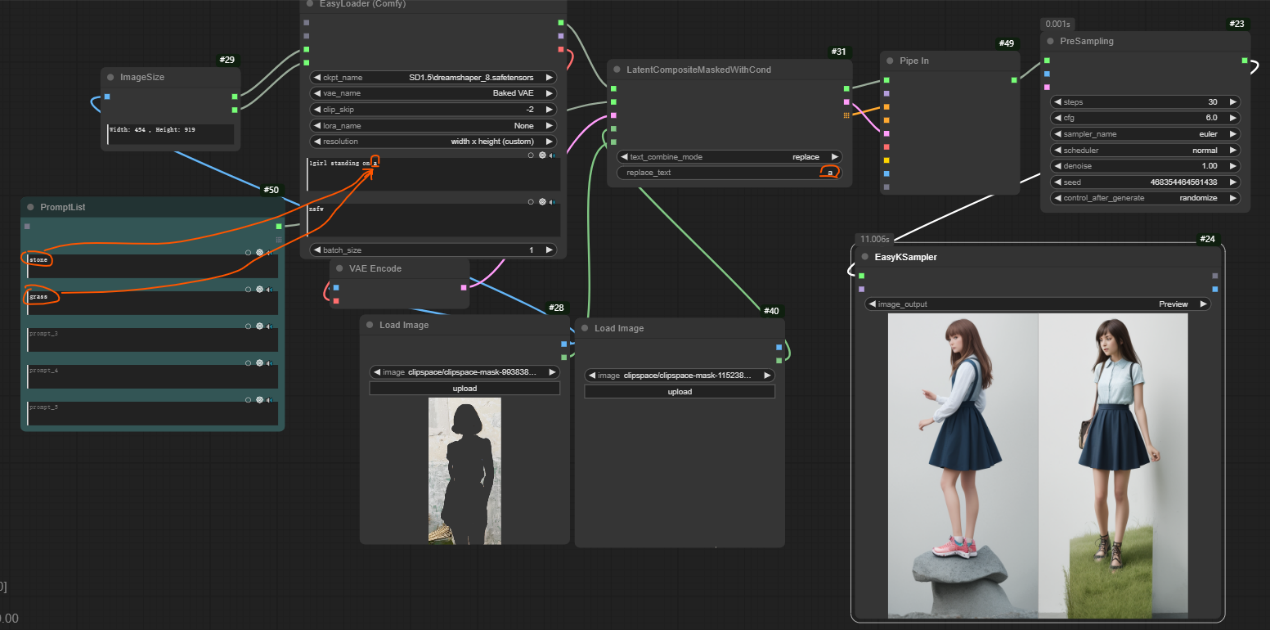
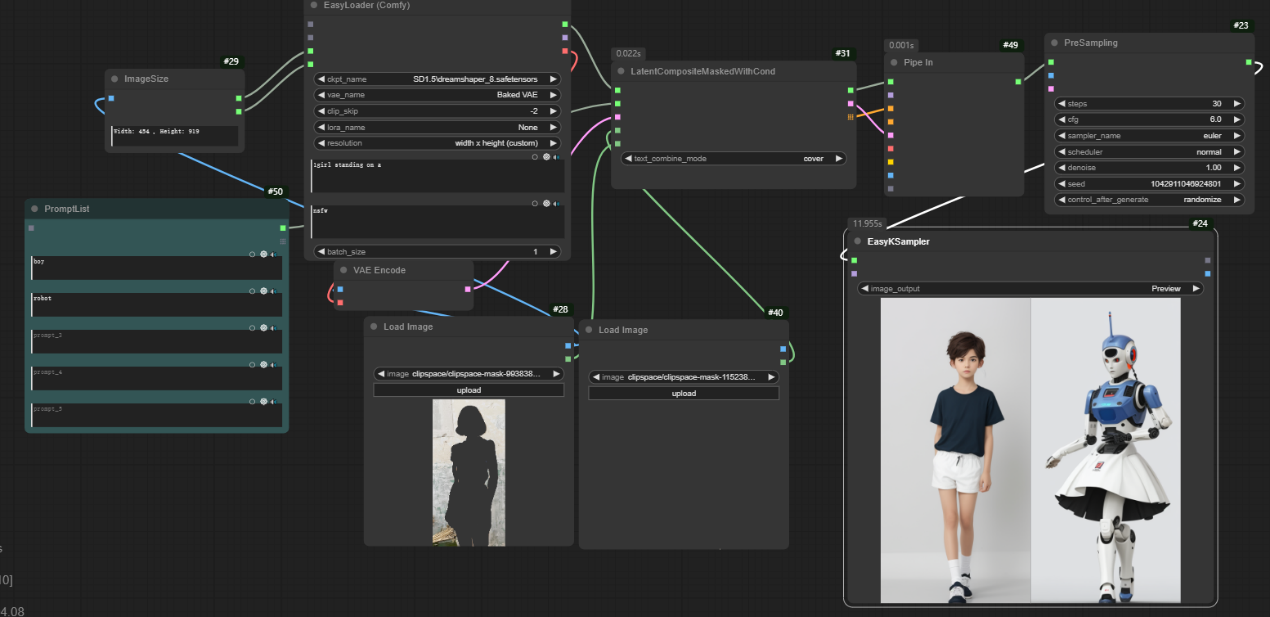
cover模式则是使用__PromptList__中的提示词完全替代__Loader__中的提示词
十、If else节点
节点功能:提供if-else判断输出true或false的选项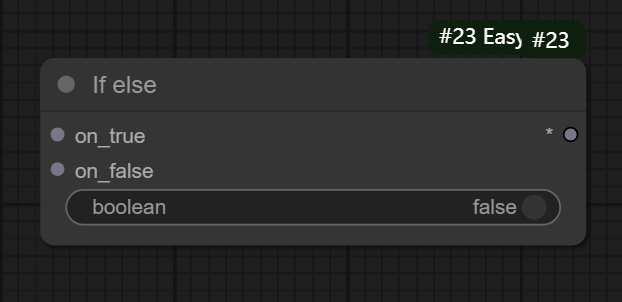
输入:
on_true:接入当boolean为true时应该输出的结果
on_false:接入当boolean为false时应该输出的结果
参数:
boolean:设置判断为true或false,可转为输入项
输出:
any: 输出满足boolean判断条件的结果
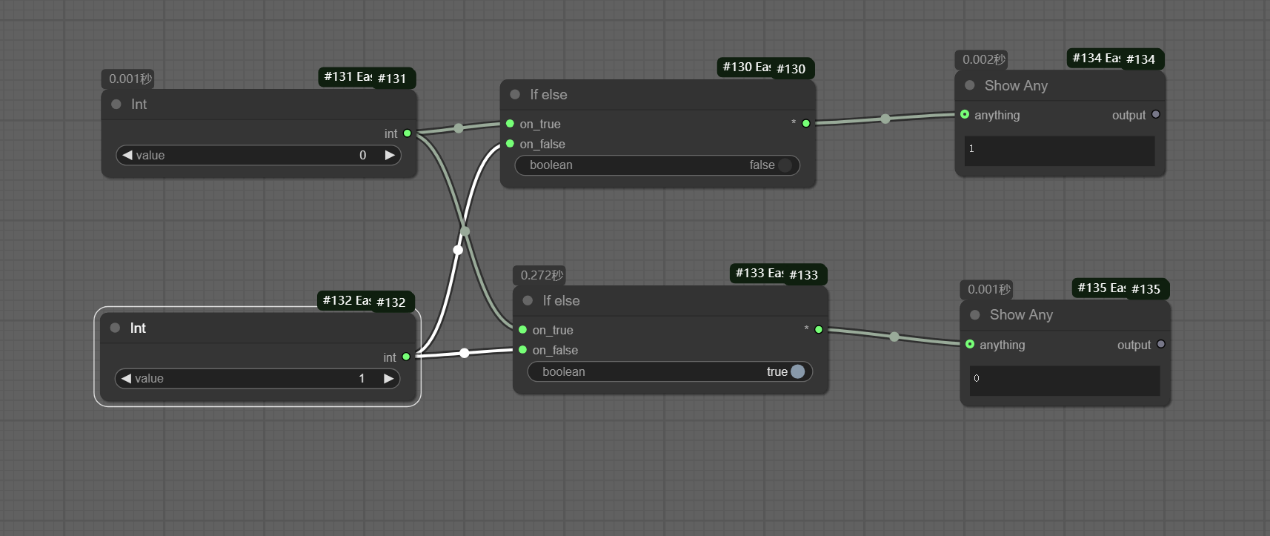
当是boolean是true的时候输出on_true选项,当boolean是false时输出on_false选项
__ComfyUI Easy Use插件(一): __https://articles.zsxq.com/easyuse/1.html
__ComfyUI Easy Use插件(二): __https://articles.zsxq.com/easyuse/2.html
__ComfyUI Easy Use插件(三): __https://articles.zsxq.com/easyuse/3.html
__ComfyUI Easy Use插件(四): __https://articles.zsxq.com/easyuse/4.html
__ComfyUI Easy Use插件(五): __https://articles.zsxq.com/easyuse/5.html
__ComfyUI Easy Use插件(六): __https://articles.zsxq.com/easyuse/6.html
__ComfyUI Easy Use插件(七): __https://articles.zsxq.com/easyuse/7.html
