【ComfyUI插件】Comfyroll节点 (五)
前言:
通过本教程的学习,我们将逐一探索每个节点的独特功能和应用场景,并掌握如何将它们应用于实际项目中。你将能够:批量处理图像,节省时间和精力;巧妙地合并和交错列表数据,创造新的序列;重复执行操作,以实现特定的数据处理模式;执行数学运算,特别是针对列表数据的乘积操作;将文本列表转换为整洁的字符串,便于展示和分析。
__Comfyroll插件(一): __https://articles.zsxq.com/comfyroll/1.html
__Comfyroll插件(二): __https://articles.zsxq.com/comfyroll/2.html
__Comfyroll插件(三): __https://articles.zsxq.com/comfyroll/3.html
__Comfyroll插件(四): __https://articles.zsxq.com/comfyroll/4.html
__Comfyroll插件(六): __https://articles.zsxq.com/comfyroll/6.html
__Comfyroll插件(七): __https://articles.zsxq.com/comfyroll/7.html
__Comfyroll插件最终篇+应用示例: __https://articles.zsxq.com/comfyroll/8.html
目录:
先行:安装方法
一、CR Image Pipe节点
二、CR Multi Upscale Stack/ CR Upscale Image/ CR Apply Multi Upscale节点
三、CR SDXL Prompt Mix Presets节点
四、CR SDXL Base Prompt Encoder节点
五、CR XY List节点
六、CR XY From Folder节点
七、CR XY Save Grid Image节点
"XY测试"示例工作流
安装方法:
在ComfyUI主目录里面输入CMD回车。
在弹出的CMD命令行输入git clone xxx,即可开始下载。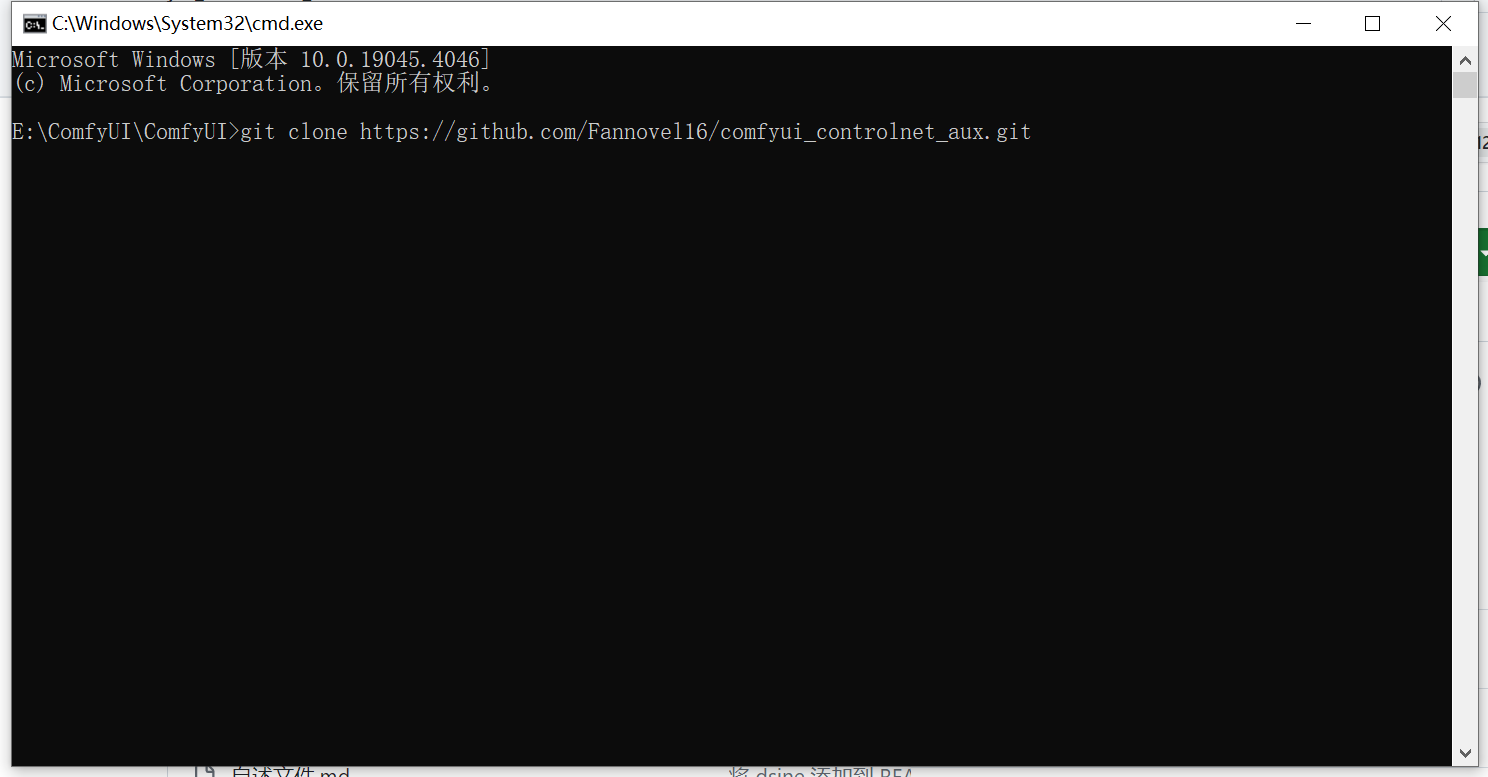
github项目地址:https://github.com/Suzie1/ComfyUI_Comfyroll_CustomNodes.git
一、CR Image Pipe节点
节点索引:CR Image Pipe In/ CR Image Pipe Edit/ CR Image Pipe Out
节点功能:这些节点可以将图像信息混合进去pipe传输,并且允许在输出图中更改pipe中的值。
输入:
image -> 需要混合进入pipe的管道信息
pipe -> 混合所有信息后的pipe管道
width -> 传入要更改的宽度值 **该值并不会改变图像大小**
height -> 传入要更改的高度值 **该值并不会改变图像大小**
upscale_factor -> 传入要更改的放大倍数 **该值并不会改变图像大小**
参数:
width -> 传入原始设置的宽度值 **该值并不会改变图像大小**
height -> 传入原始设置的高度值 **该值并不会改变图像大小**
upscale_factor -> 原始放大倍数 **该值并不会改变图像大小**
输出:
image -> 输出图像信息
pipe -> 输出混合后pipe的管道信息
width -> 输出宽度值 **该值并不会改变图像大小**
height -> 输出高度值 **该值并不会改变图像大小**
upscale_factor -> 输出放大倍数 **该值并不会改变图像大小**
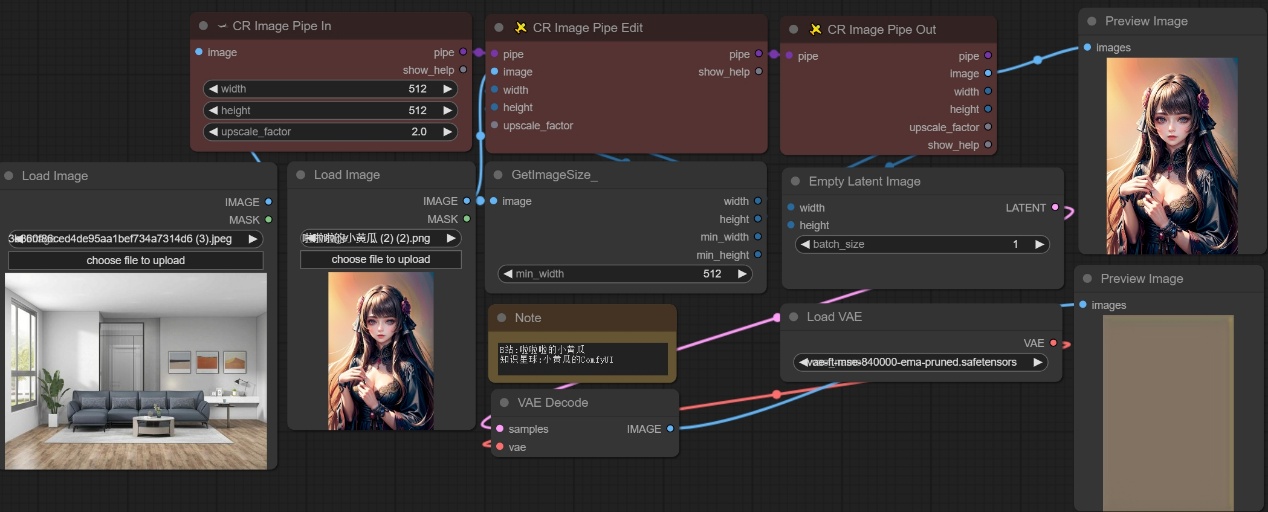
注意:如下图所示效果,我们在原始图像中传入一张室内图像,然后混合CR Image Pipe In结点输入的width和height与upscale_factor信息进入pipe管道运输,在传入CR Image Pipe Edit节点之后,我们对image,width和height信息进行更改,将更改后的pipe信息传入CR Image Pipe Out节点,最终输出的信息为更改后的后信息。
二、CR Multi Upscale Stack/ CR Upscale Image/ CR Apply Multi Upscale节点
节点功能:这些节点用来加载放大模型,可同时加载多个放大模型,并且可以设置模型放大倍数等。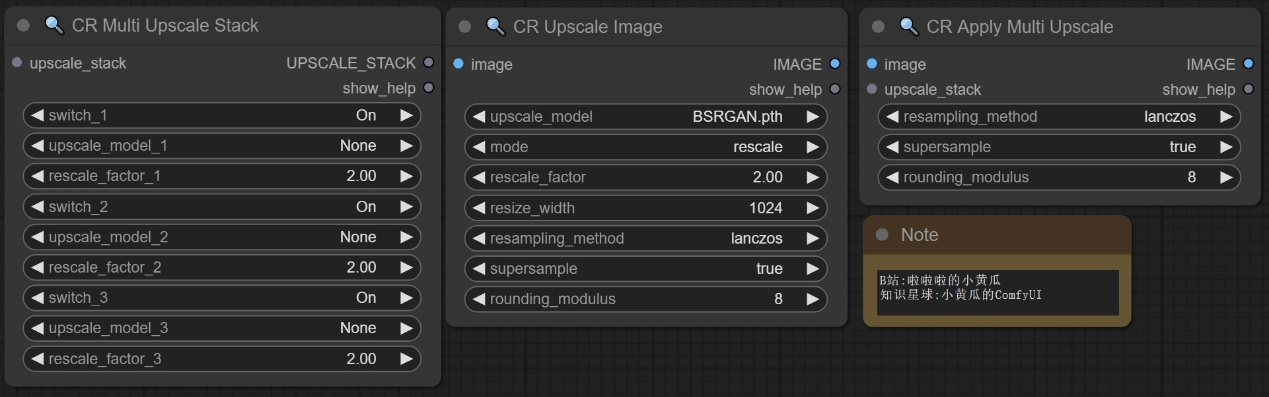
输入:
image -> 表示输入的待放大的图像
upscale_stack -> 传入放大模型栈信息 **多个节点可以进行串联增加数量**
参数:
switch_x -> 是否使该模型起作用
upscale_model_x -> 选择放大模型
rescale_factor_x -> 放大系数
mode -> 放大模式 ** “rescale表示重新缩放通常会保持图像的宽高比不变” 或 “resize调整大小是指根据指定的目标尺寸,将图像的宽度和高度调整到新的尺寸”**
resize_width -> 如果选择 “resize” 模式,指定的目标宽度
resampling_method -> 图像重采样方法
supersample -> 是否使用超采样 **超采样时对每个像素进行多次采样,以产生更加平滑和真实的图像效果**
rounding_modulus -> 调整像素值时使用的取模数 **这个参数通常用于限制像素值的范围或调整像素值的精度**
***工作流较大,分成两部分截图***
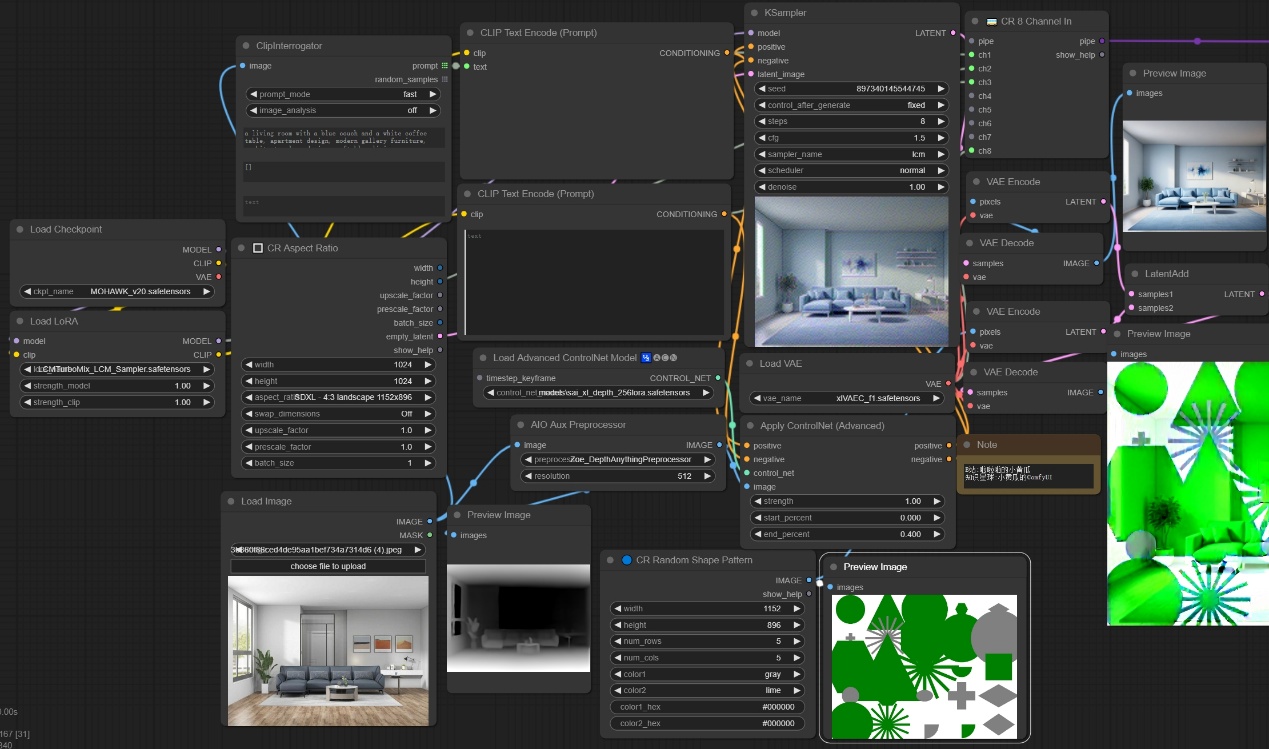
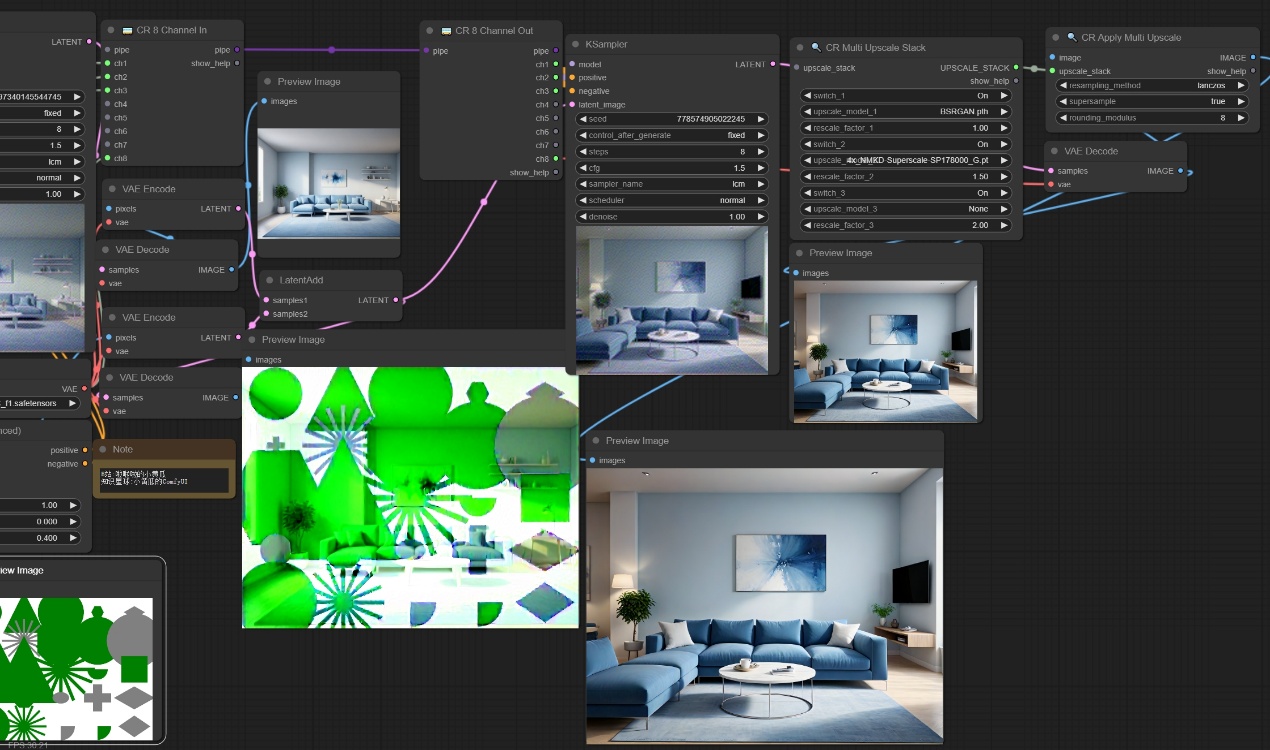
注意:如上图所示我们通过原始图像获得该图的室内深度信息,然后使用SDXL大模型去生成指定分辨率和满足深度信息的图像,后续我们通过CR库生成随机的图案信息,将生成的图像和随机的图案信息在潜空间进行噪声叠加后,通过第二个采样器进行二次降噪,然后通过放大节点对原始图像进行高清放大,使用两个放大模型,最终生成的图像即丰富了细节又保留了清晰度。
输出:
IMAGE -> 输出放大后的图像
三、CR SDXL Prompt Mix Presets节点
节点功能:这个节点为了方便混合不同的文本提示和样式,以生成最终的混合输出。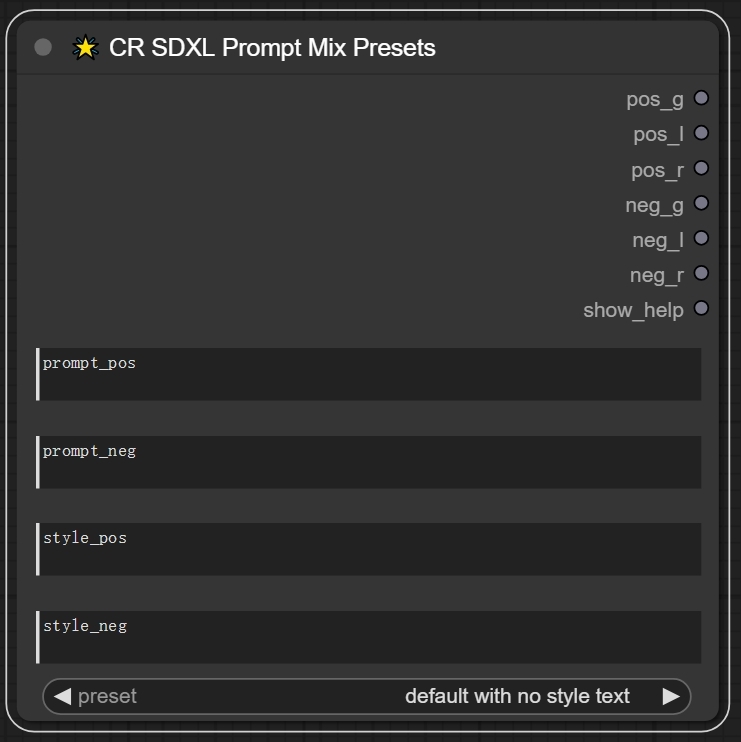
输入:
prompt_pos -> 正向文本提示词
prompt_neg -> 反向文本提示词
style_pos -> 正向风格提示词
style_neg -> 反向风格提示词
preset -> 预设的提示词混合方式
***这个节点真的很难理解,我给出的信息不一定正确,大家批判性的吸收***
***这个节点讲配合CR SDXL Base Prompt Encoder(下一个节点)一起使用,给出工作流讲解***
输出:
pos_g -> 正面全局信息
pos_l -> 正面局部信息
pos_r -> 正面内容信息
neg_g -> 负面全局信息
neg_l -> 负面局部信息
neg_r -> 负面内容信息
四、CR SDXL Base Prompt Encoder节点
节点功能:这个节点通过预设preset的混合条件,来生成编码后的条件信息。
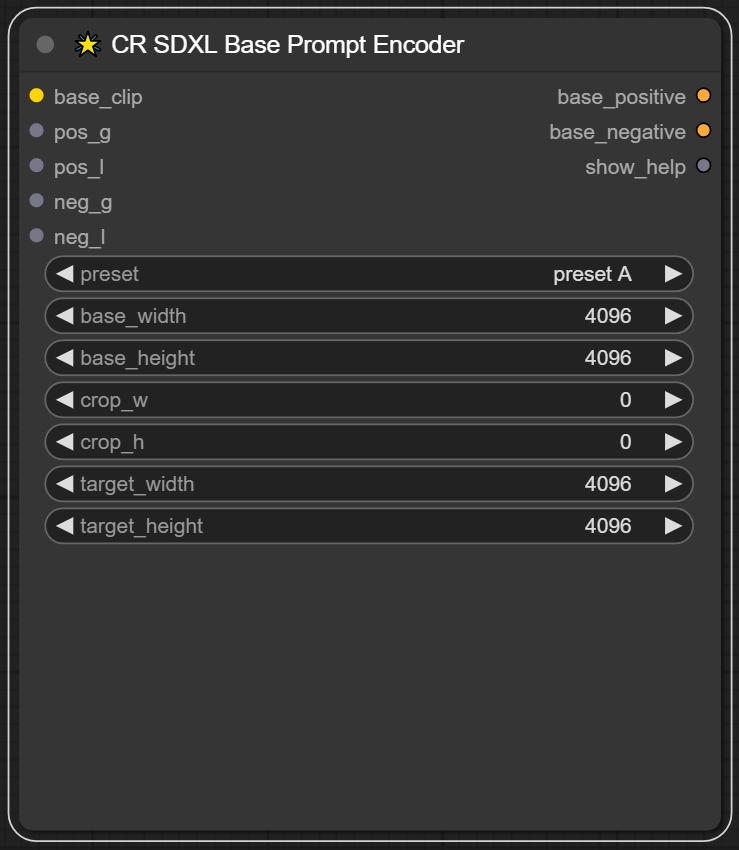
输入:
base_clip -> CLIP模型,用于将文本提示编码为条件信息
pos_g -> 正面全局的文本提示
pos_l -> 正面局部的文本提示
neg_g -> 反面全局的文本提示
neg_l -> 反面局部的文本提示
参数:
preset -> 指定模型处理文本提示时的一组特定设置或配置
base_width -> ***可能是值得提示词作用范围???***
base_height ->
crop_w ->
crop_h ->
target_width ->
target_height ->
***这几个参数我真不知道啥意思,看代码也没看明白***
注意:我们这次测试的内容是CR SDXL Prompt Mix Presets节点的预设内容,也就是preset的设置内容,我们对四个选项分别做了测试。
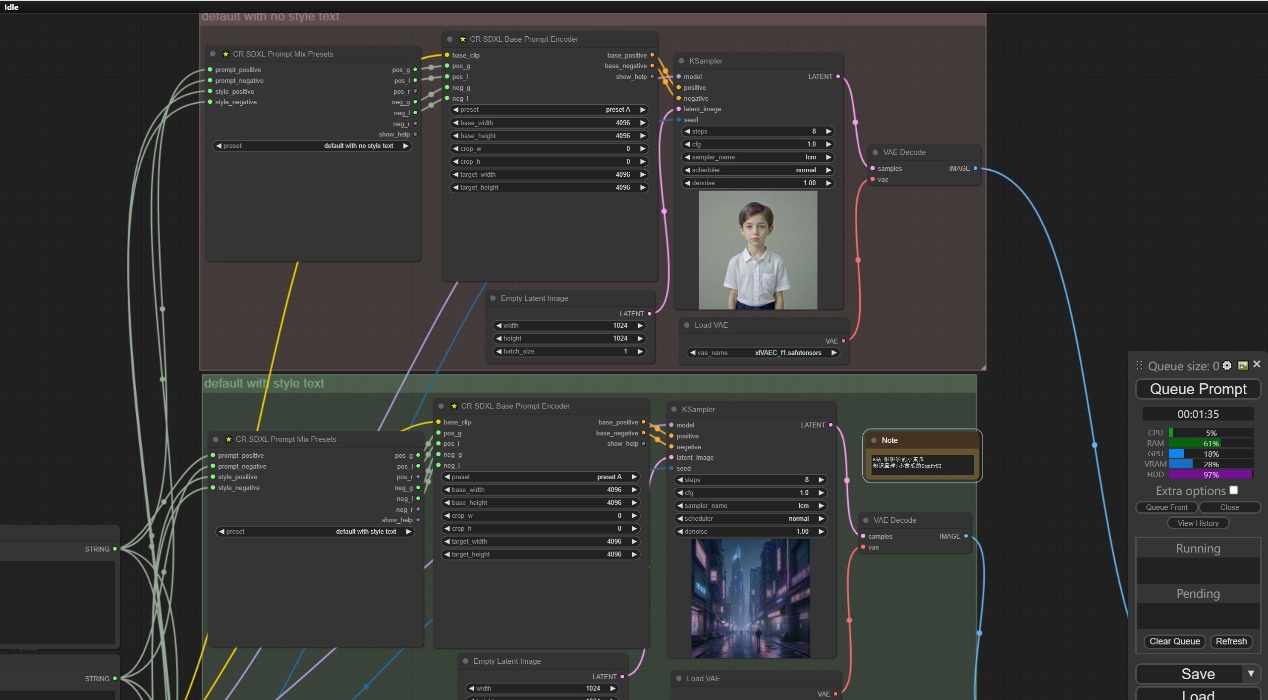
注意:对四种preset格式应用相同的随机数种子,相同的参数,以及相同的提示词和大模型,区别只有文本的混合方式。
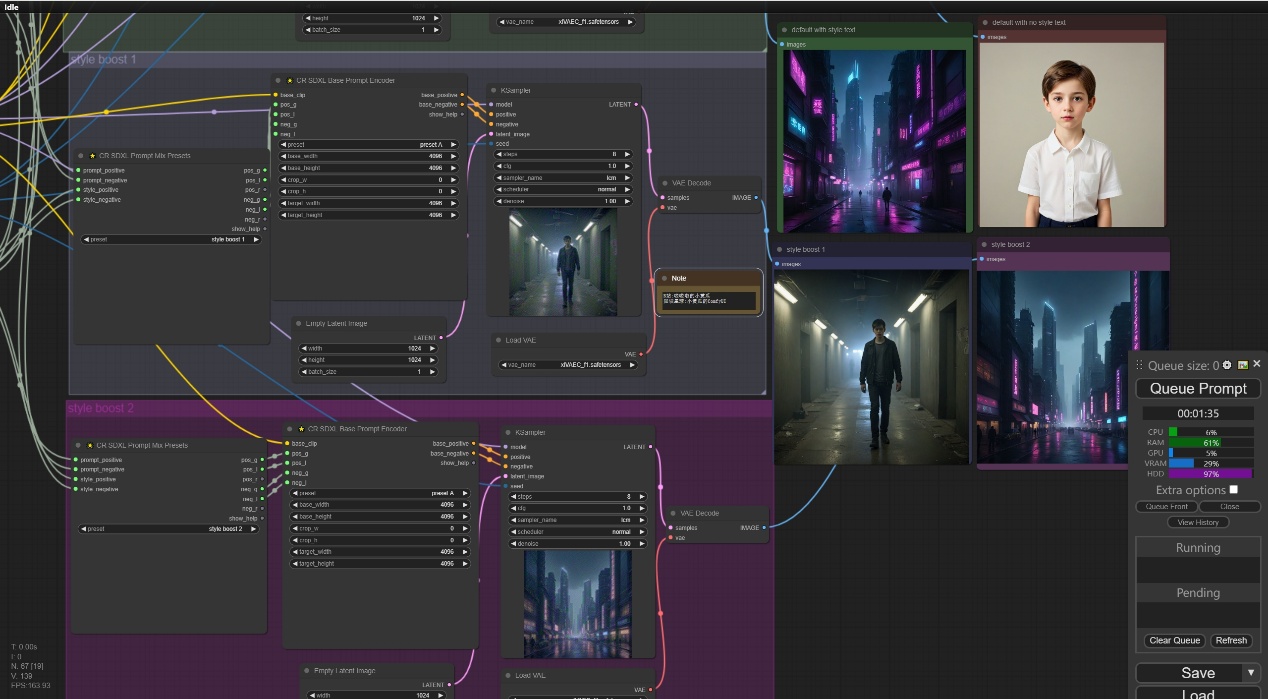
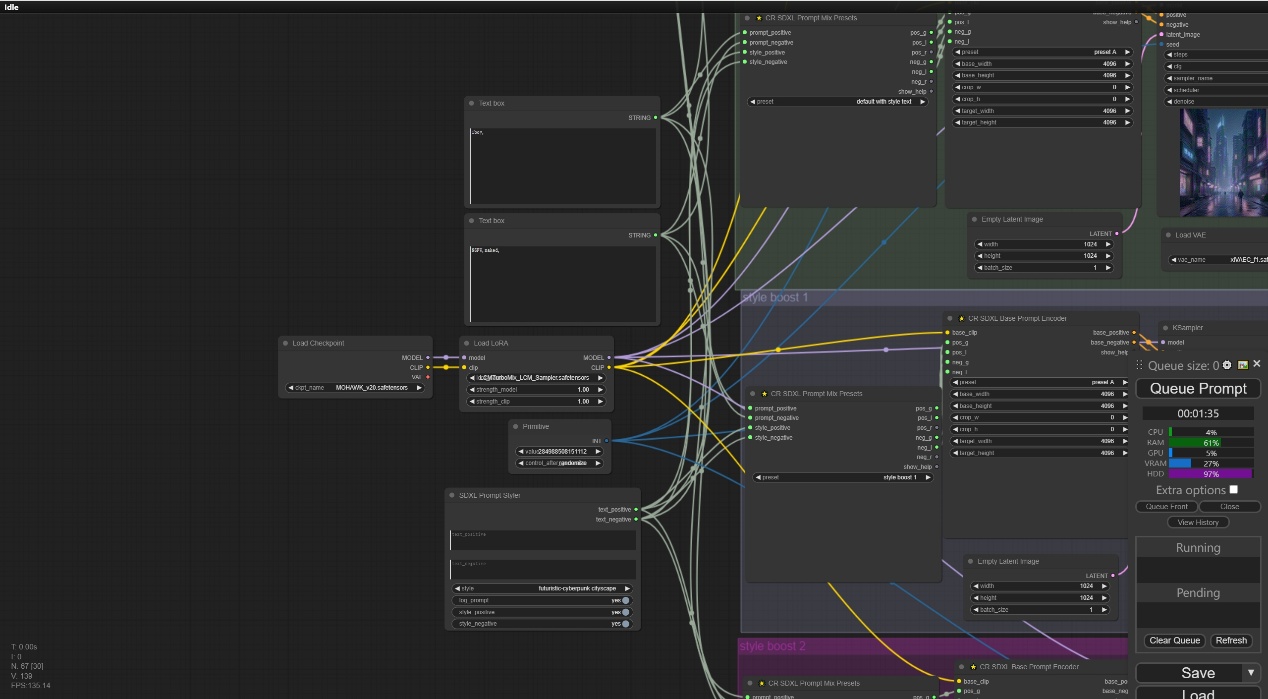
注意:这里是我们使用到的大模型和一个LCM的Lora用来加速图像的生成速度,在SDXL prompt Style中我们选择赛博朋克风格的风格提示词,在正向提示词中我们输入1boy,反向提示词中我们输入NSFW,naked,防止出现不好的图片。
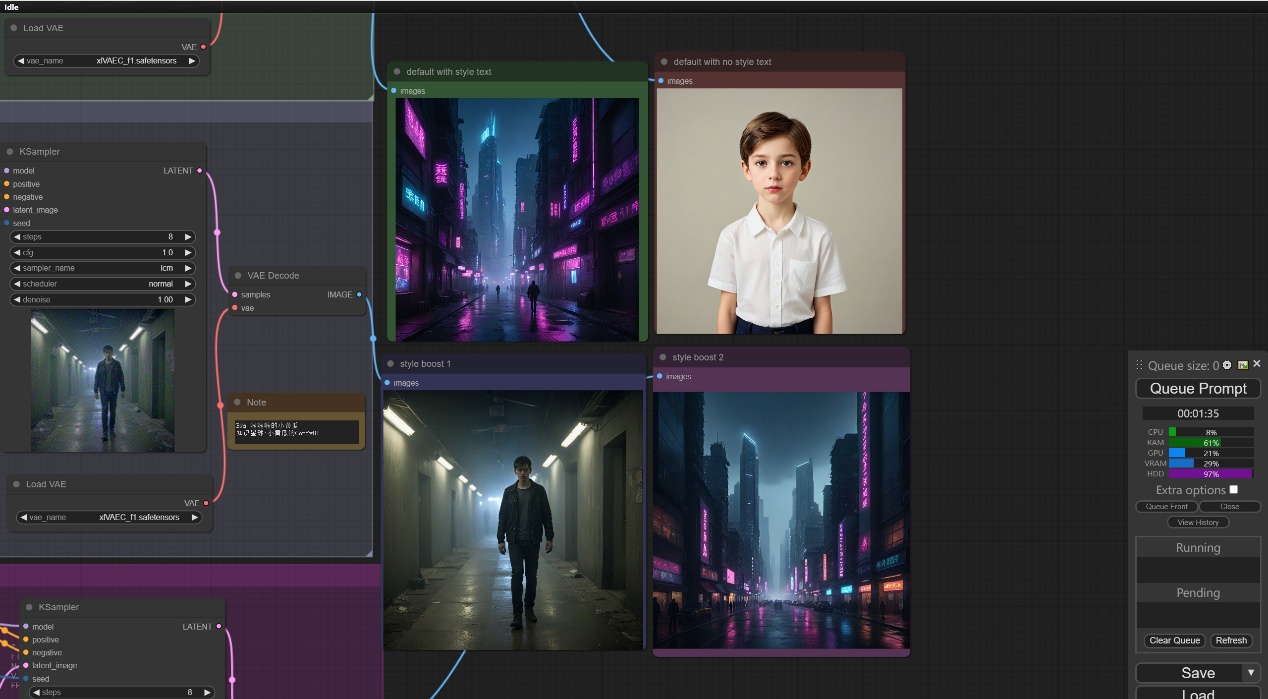
注意:结果如下图所示,我们可以看出在default with no style text和style boost 1两种提示词混合选项中并不会出现风格提示词相关的内容,在default with style text中出现了boy和赛博朋克的内容,而style boost 2中却并没有boy的信息。
输出:
base_positive -> 输出整理后的正向条件信息
base_negative -> 输出整理后的反向条件信息
五、CR XY List节点
节点功能:这个节点用来设置坐标系的基本信息以及一些关于坐标系的参数设置。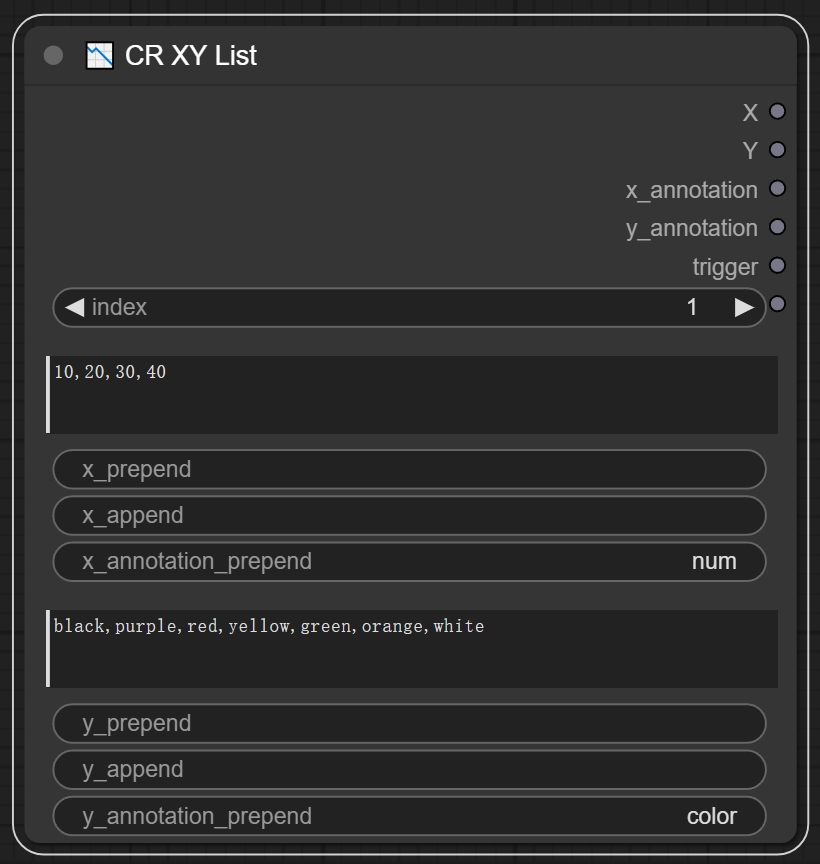
参数:
index -> 指定从生成的二维网格中选择的单元格索引
x轴输入框 -> 作为x轴上的值 **比如可以作为int输入,设置x轴的个数**
x_prepend -> 添加到x值之前的字符串
x append -> 添加到x值之后的字符串
x annotation prepend -> 添加到x注释之前的字符串
y轴输入框 -> 作为y轴上的值 **比如可以作为int输入,设置y轴的个数**
y_prepend -> 添加到y值之前的字符串
y_append -> 添加到y值之后的字符串
y_annotation_prepend -> 添加到y注释之前的字符串
注意:如下图所示,我们设置X的输入为10,20,30,40然后设置y的输入为颜色值,则将x转为整数型传入下一个节点去控制点的频率,将颜色值以字符串传入去控制背景信息,最终我们保存到自己指定的位置,然后将进行下一步操作,去生成xy列表图像信息。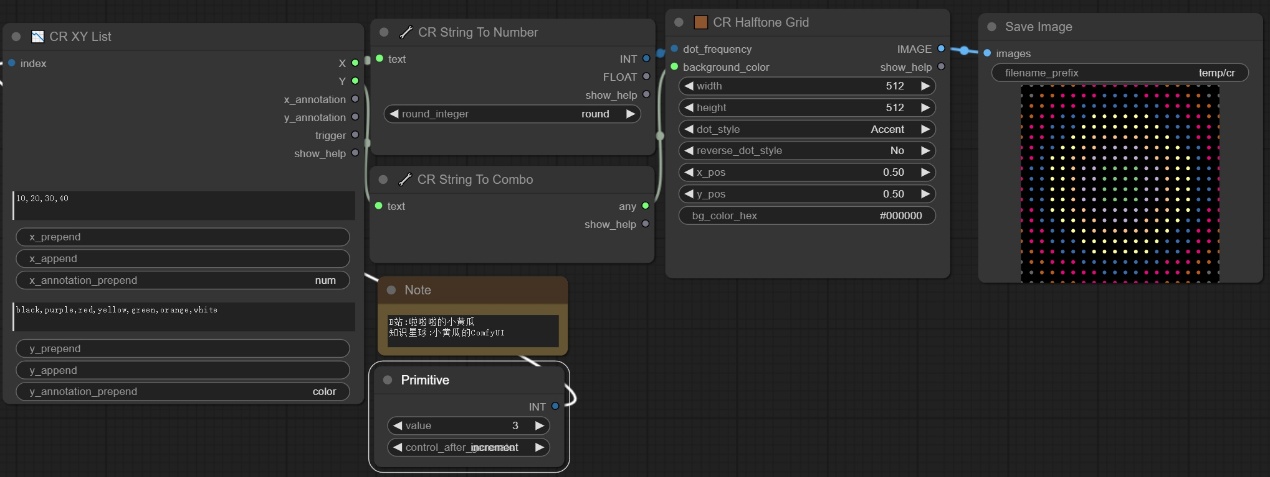
输出:
X -> 输出选定的x的值
Y -> 输出选定的y的值
x_annotation -> 输出x_annotation设置的值
y_annotation -> 输出y_annotation设置的值
trigger -> 输出布尔值,判断是否到尾部
六、CR XY From Folder节点
节点功能:这个节点从指定的文件夹载入图像,将他们按照我们指定的列数进行排列,我们可以指定横纵坐标轴的信息,可以给出图例。
***重点!!!这个image_folder不能自行指定,需要将要合并的文件夹放入custom_nodes\ComfyUI_Comfyroll_CustomNodes\workflows\XY Grid目录下面。***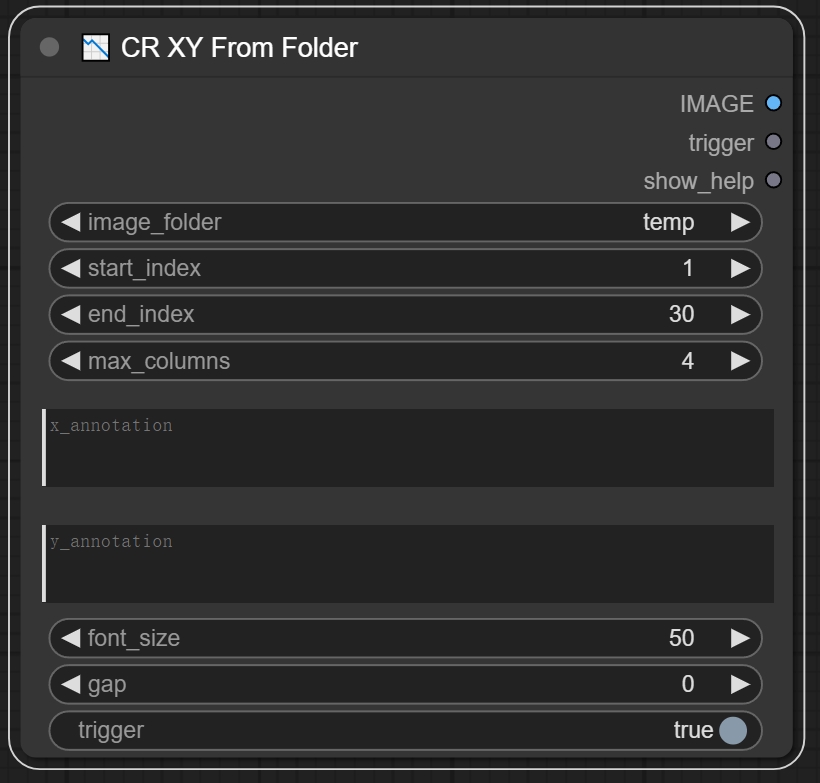
输入:
image_folder -> 文件夹名称
start_index -> 开始的索引值
end_index -> 结束的索引值
max_columns -> 最大列的数量
x输入框 -> 用来设置x轴的标注信息
y输入框 -> 用来设置y轴的标注信息
font_size -> 字体的大小
gap -> 图像之间的间隔
trigger -> 用于触发节点执行加载图像的操作 ***要打开***
输出:
IMAGE -> 输出合并后的图像信息
trigger -> 一个布尔值,判断文件末尾
注意:这里我们输入x和y的坐标轴信息的时候,我们要使用;隔开,如下图所示,设置temp文件夹从1开始索引一共读取28张图像,最大列数量为4,这样我们就是生成4*7的一个图像矩阵,然后按照我们给出的x轴y轴标注进行出图。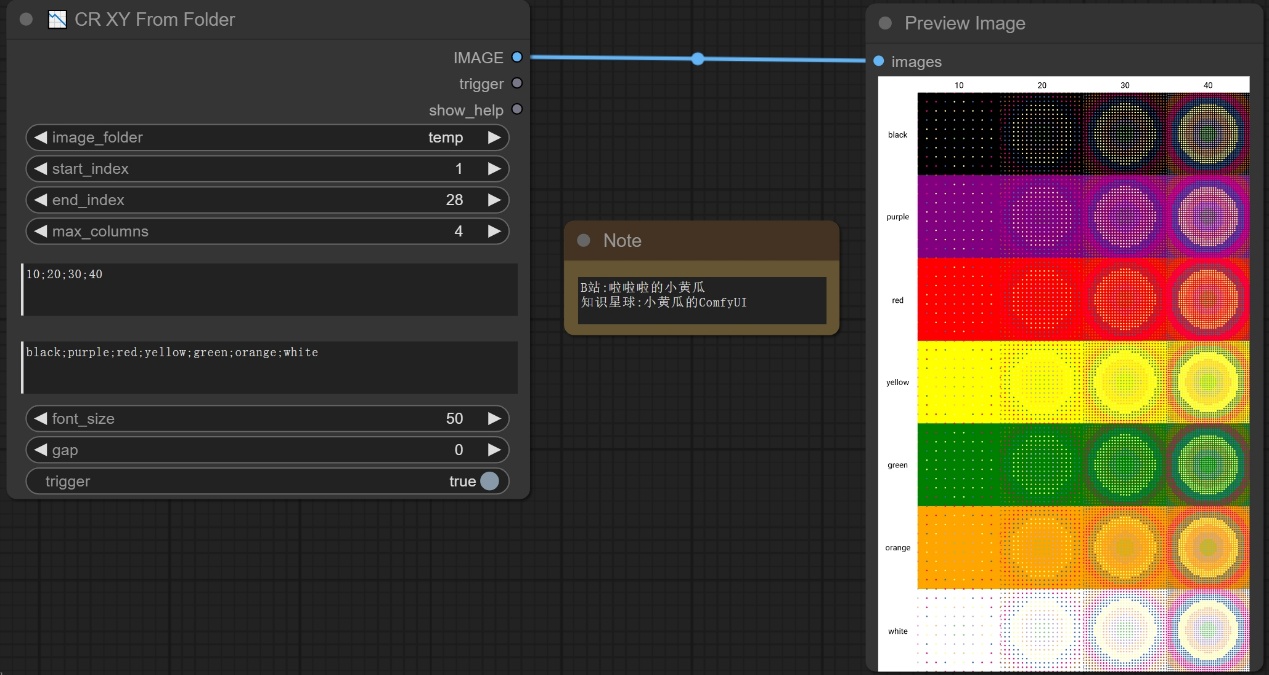
注意:我们可以建立如下图所示的工作流来进行不同的大模型和lora的测试,通过名称来进行模型和lora的索引,然后设置自动运行队列为模型数量 * lora模型数量,然后去全自动生成图像保存到指定位置,图像生成完毕,我们通过CR XY From Folder节点去进行阵列显示。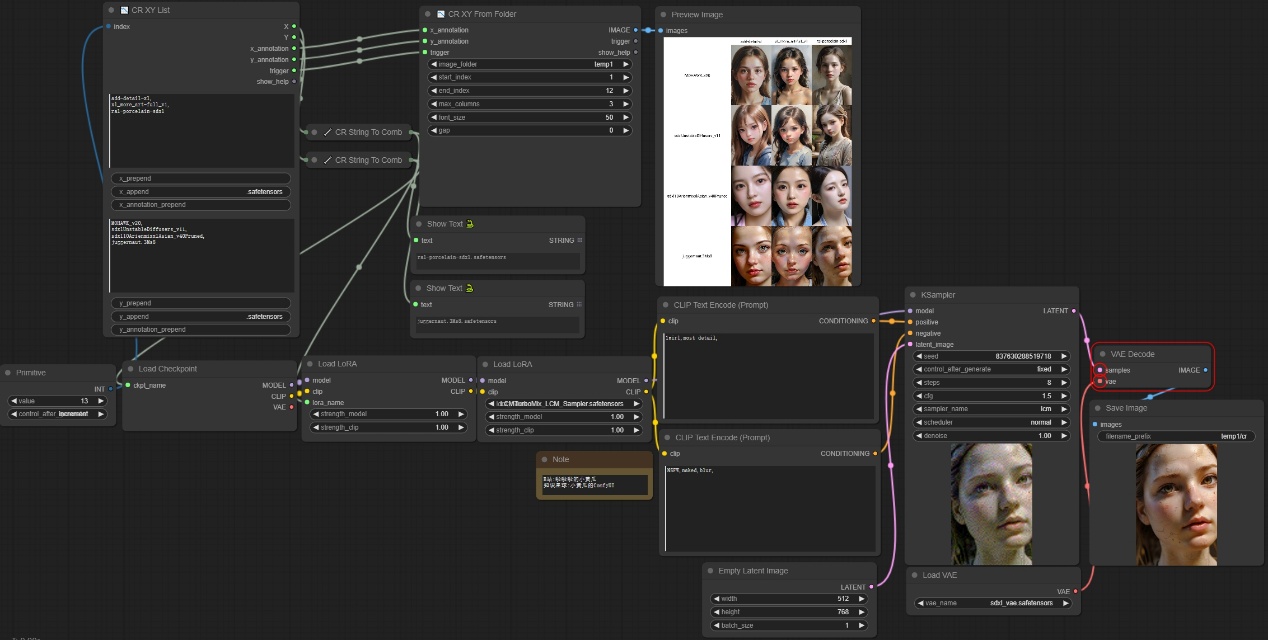
七、CR XY Save Grid Image节点
节点功能:这个节点用来保存合并后的图像,可以设置保存路径等。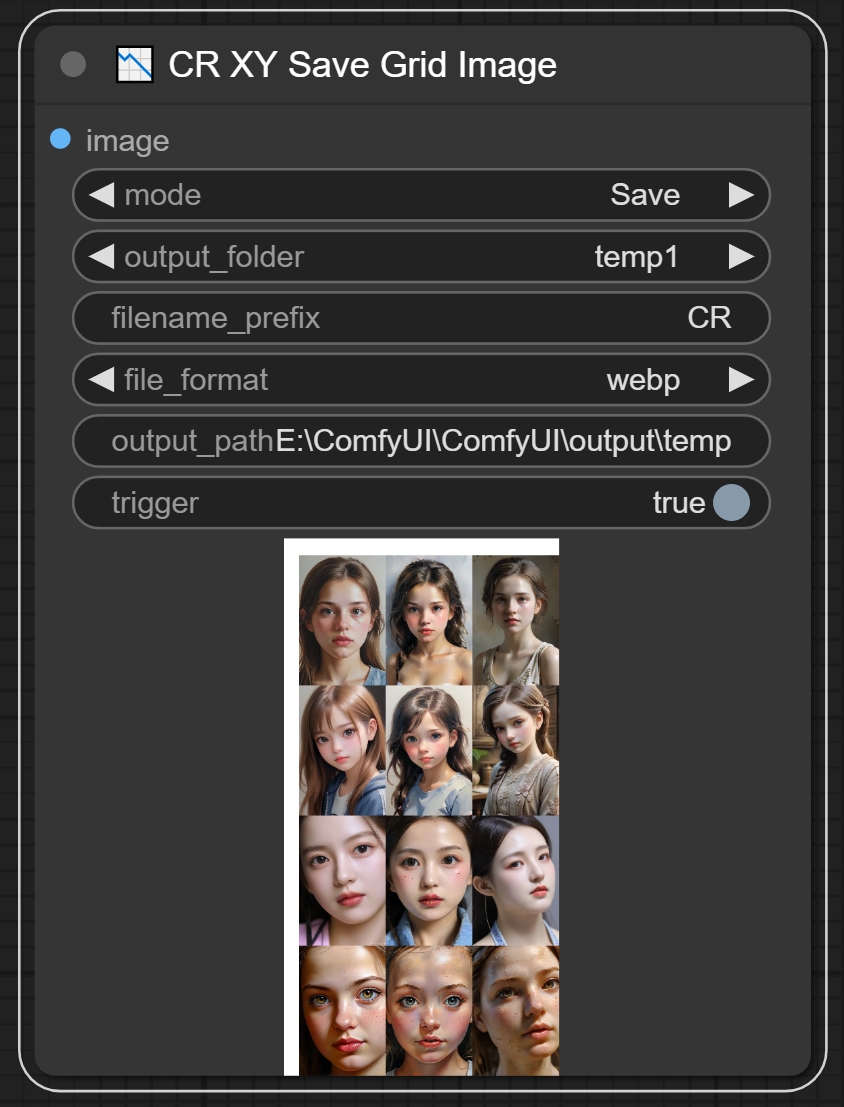
输入:
image -> 图像信息
参数:
mode -> 模式,可选择预览和保存
output_folder -> 保存的文件夹
filename_prefix -> 保存图像的名称
file_format -> 保存图像的类型
output_path -> 输出的路径
trigger -> 一个布尔值,触发该节点工作
注意:如下图所示我们可以在测试的末尾进行图像的保存。
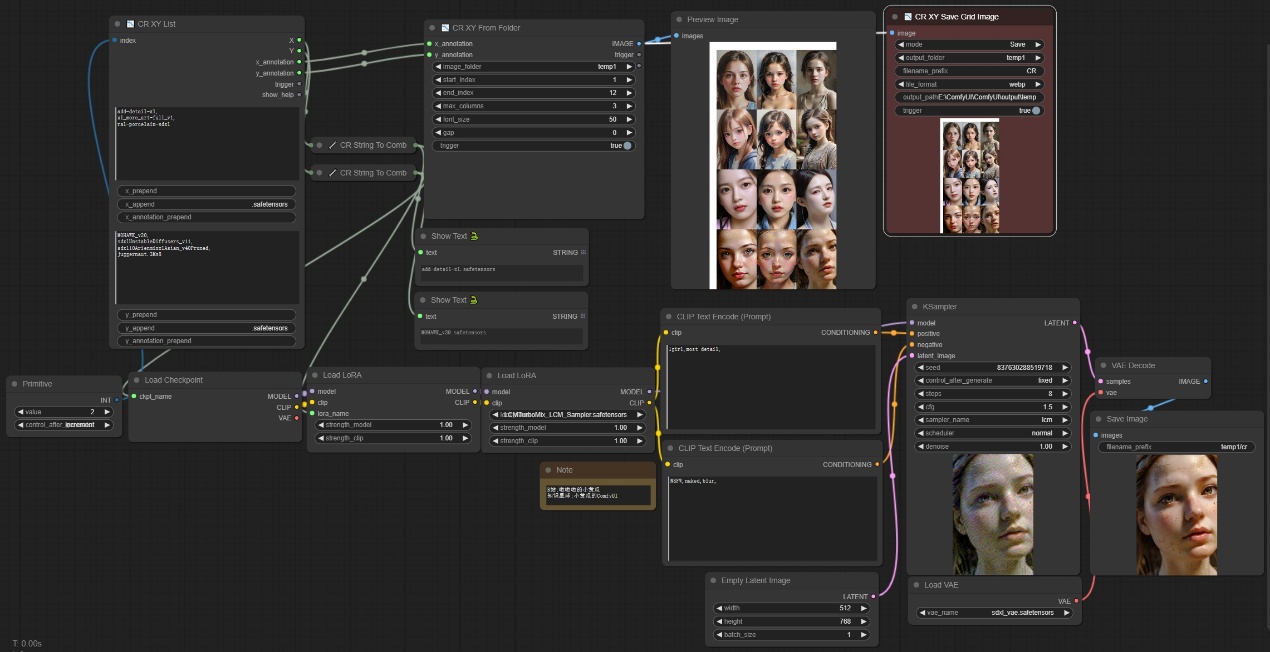
"XY测试"示例工作流:
学习完以上节点,您就可以搭建“XY测试”示例工作流了
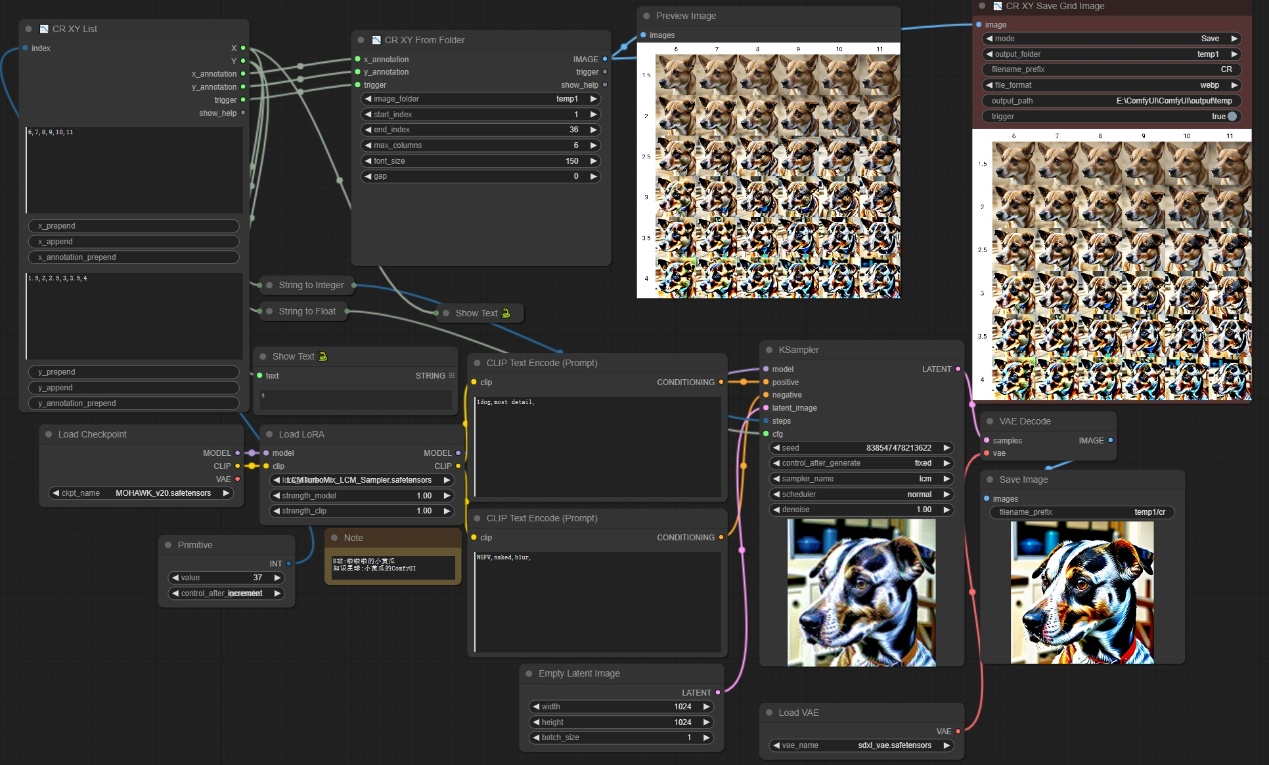
这里使用SDXL的大模型,加载LCM的Lora进行生成过程干预,分别对steps=6,7,8,9,10,11和CFG=1.5,2,2.5,3,3.5,4做了XY测试,最终输出6*6的一个列表,通过对比可以更加清晰地看出最佳参数组合,最终出图如下所示:
孜孜不倦,方能登峰造极。坚持不懈,乃是成功关键。
__Comfyroll插件(一): __https://articles.zsxq.com/comfyroll/1.html
__Comfyroll插件(二): __https://articles.zsxq.com/comfyroll/2.html
__Comfyroll插件(三): __https://articles.zsxq.com/comfyroll/3.html
__Comfyroll插件(四): __https://articles.zsxq.com/comfyroll/4.html
__Comfyroll插件(六): __https://articles.zsxq.com/comfyroll/6.html
__Comfyroll插件(七): __https://articles.zsxq.com/comfyroll/7.html
__Comfyroll插件最终篇+应用示例: __https://articles.zsxq.com/comfyroll/8.html
