【ComfyUI插件】ComfyUI_IPAdapter_plus(新版)插件
前言:
ComfyUI_IPAdapter_plus是常用且便捷有效的风格迁移模型,可以通过提供参考图像去进行图像的生成,比如风格迁移,风格融合,人物脸部模拟等各种工作,本文将对库中的节点进行详细的解释和示例教学,希望大家活学活用!
目录:
一、IPAdapter Advanced/ IPAdapter/ IPAdapter Batch (Adv.)节点
二、IPAdapter Unified Loader FaceID/ IPAdapter Unified Loader/ IPAdapter Unified Loader Community节点
三、IPAdapter FaceID/ IPAdapter FaceID Batch节点
四、IPAdapter Tiled/ IPAdapter Tiled Batch节点
五、IPAdapter Embeds/ IPAdapter Combine Embeds/ IPAdapter Encoder节点
六、IPAdapter Noise/ Prep Image For ClipVision节点
"参考人物换装更换"示例工作流
安装方法:※※看这里※※
一、IPAdapter Advanced/ IPAdapter/ IPAdapter Batch (Adv.)节点
节点功能:这三个节点用来将IPAdapter模型的效果注入到大模型中去引导扩散。
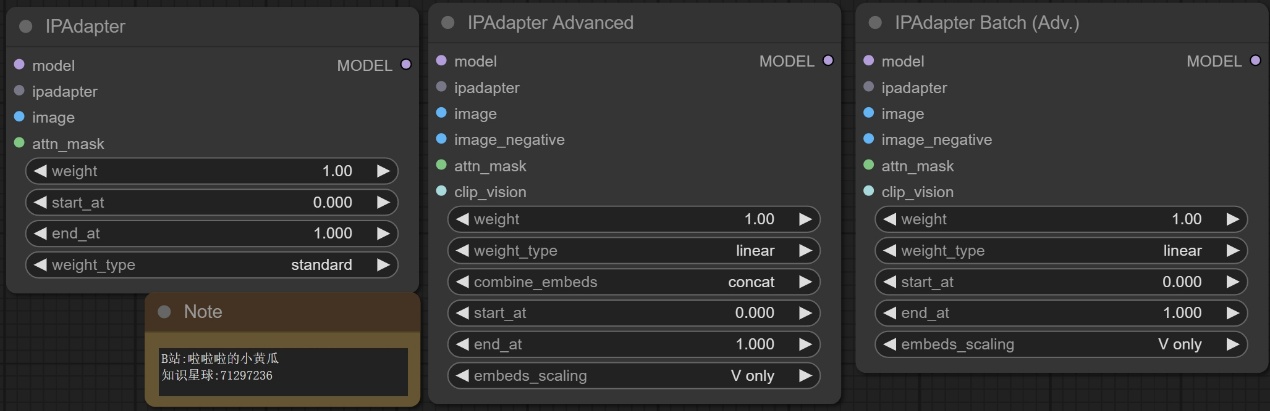
输入:
model -> 模型 ***输入模型***
ipadapter -> IP适配器 ***IP适配器模型或字典***
image -> 图像 ***输入图像***
image_negative -> 负图像 ***负图像***
attn_mask -> 注意力掩码 ***注意力掩码***
clip_vision -> CLIP视觉 ***CLIP视觉模型***
参数:
weight -> 权重 ***权重,默认为1.0,取值范围为-1到3,步长为0.05***
weight_type -> 权重类型 ***权重类型***
combine_embeds -> 合并嵌入 ***合并嵌入方式,可选项为concat、add、subtract、average、norm average***
start_at -> 起始位置 ***起始位置,默认为0.0,取值范围为0.0到1.0,步长为0.001***
end_at -> 结束位置 ***结束位置,默认为1.0,取值范围为0.0到1.0,步长为0.001***
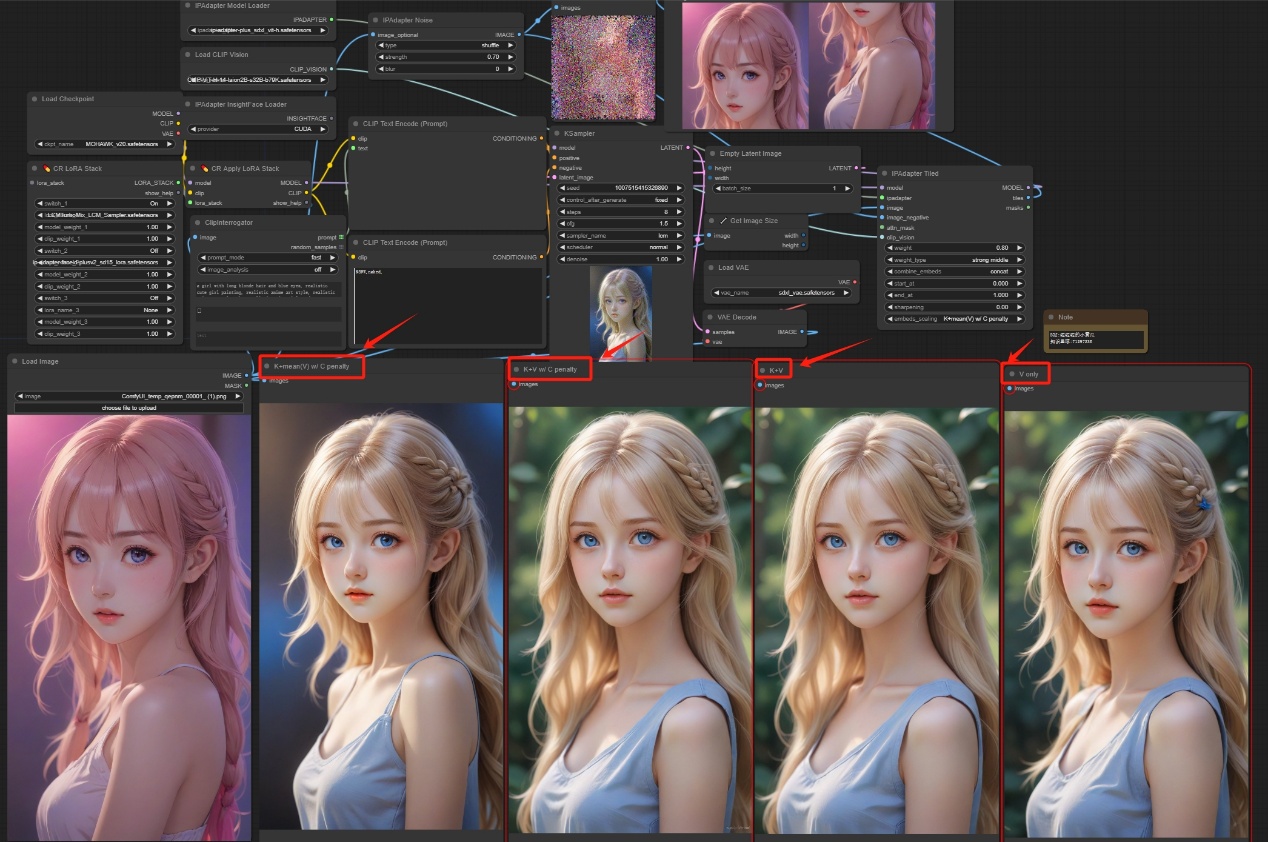
embeds_scaling -> 嵌入缩放 ***嵌入缩放方式,默认为’V only’,可选项为’V only’、‘K+V’、‘K+V w/ C penalty’、‘K+mean(V) w/ C penalty’***
- ‘V only’:仅对视觉嵌入(V)进行缩放操作,保持其他嵌入不变。
- ‘K+V’:对键(K)和视觉嵌入(V)进行缩放操作,保持其他嵌入不变。
- ‘K+V w/ C penalty’:对键(K)和视觉嵌入(V)进行缩放操作,并在缩放过程中对C惩罚,保持其他嵌入不变。
- ‘K+mean(V) w/ C penalty’:对键(K)和视觉嵌入(V)进行缩放操作,但是在缩放视觉嵌入时使用均值进行,同时对C进行惩罚,保持其他嵌入不变。
输出:
MODEL -> 输出嵌入信息之后的模型
注意:如下图所示,使用SDXL的大模型,对weight_type的四种变化方式进行了测试,可以看出权重类型的不同变换方式对最终图像的生成有很大的影响。
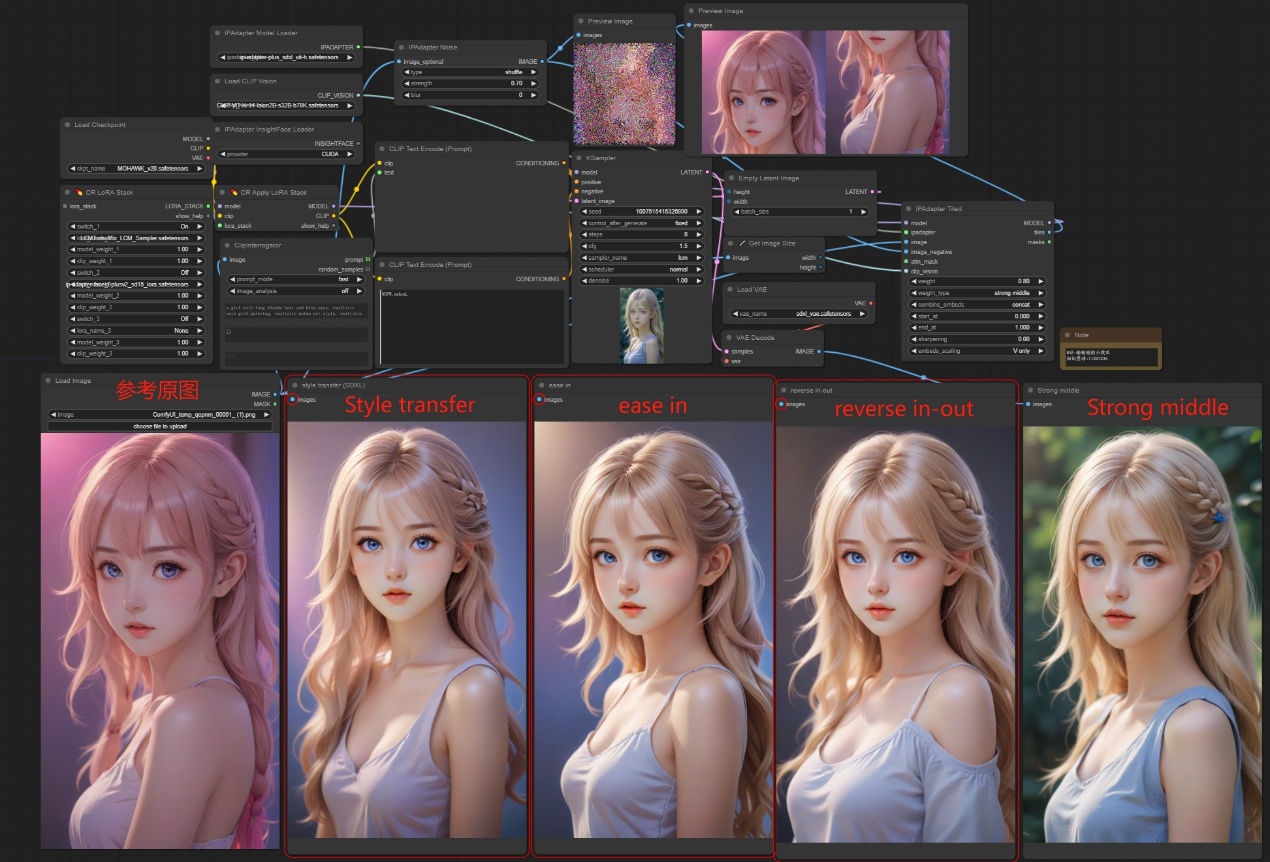
注意:如下图所示,对四种不同的嵌入方式进行了一一实验,大家可自行对比择优选择。
二、IPAdapter Unified Loader FaceID/ IPAdapter Unified Loader/ IPAdapter Unified Loader Community节点
__
__
节点功能:这三个节点是用来自动加载IPAdapter和其对应的CLIP version模型的,不需要自己对应加载。
注意:您需要将各个模型放入到对应的地方,这个节点才可以正确的加载这些模型。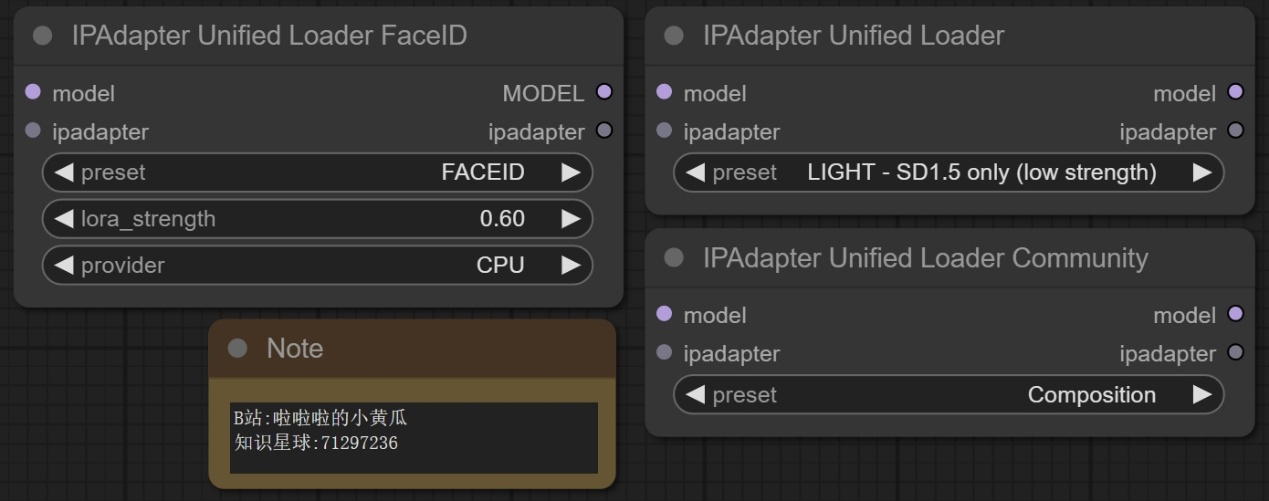
输入:
model -> 要应用模型的对象 ***包含要应用 IPAdapter 的模型对象***
ipadapter -> IPAdapter 模型的配置信息
参数:
preset -> 预设的模型配置 ***可选的预设模型配置,用于加载不同配置的模型***
lora_strength -> LoRA 模型的强度参数 ***控制 LoRA 模型的强度,用于增强模型的效果***
provider -> InsightFace 模型的提供程序 ***用于加载 InsightFace 模型的提供程序,例如 “CPU” 或 “GPU”***
输出:
MODEL -> 输出选择的模型
ipadapter -> IPAdapter 模型的配置信息
注意:如下图所示,给出了IPAdapter Unified Loader FaceID的一般用法,该节点可以自动加载对应的lora,clip version和insightface模型,不需要自己进行指定,同理另外两个节点也可以自行适配不需额外的指定。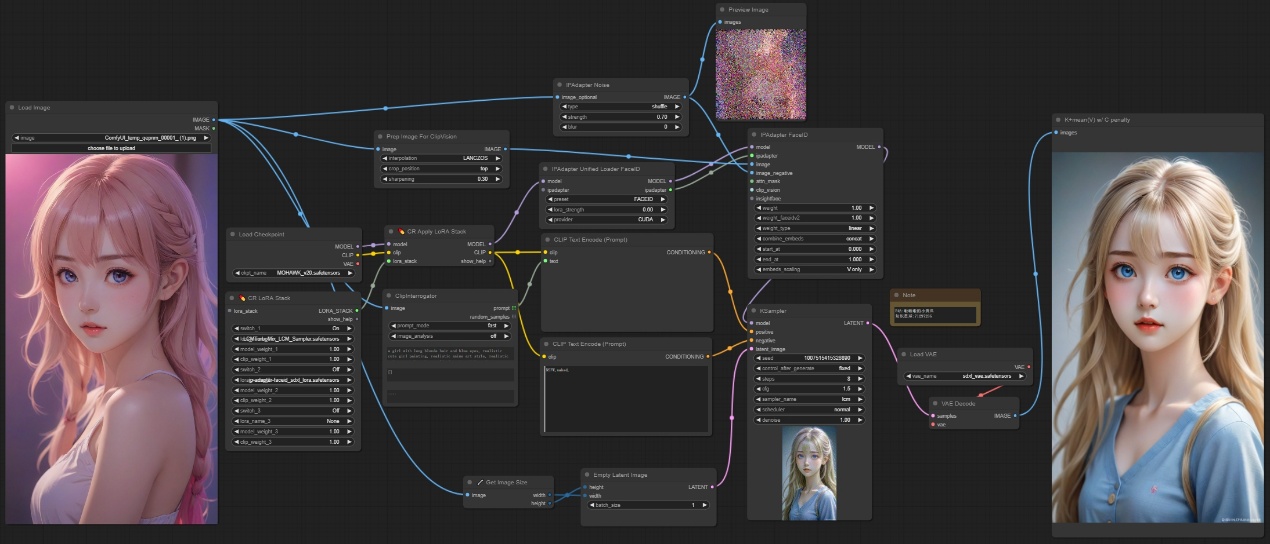
三、IPAdapter FaceID/ IPAdapter FaceID Batch节点
节点功能:这两个节点是用来识别人物的脸部,然后控制生成的图像跟参考图像的脸部相似,Batch节点可以批量的输入参考图像。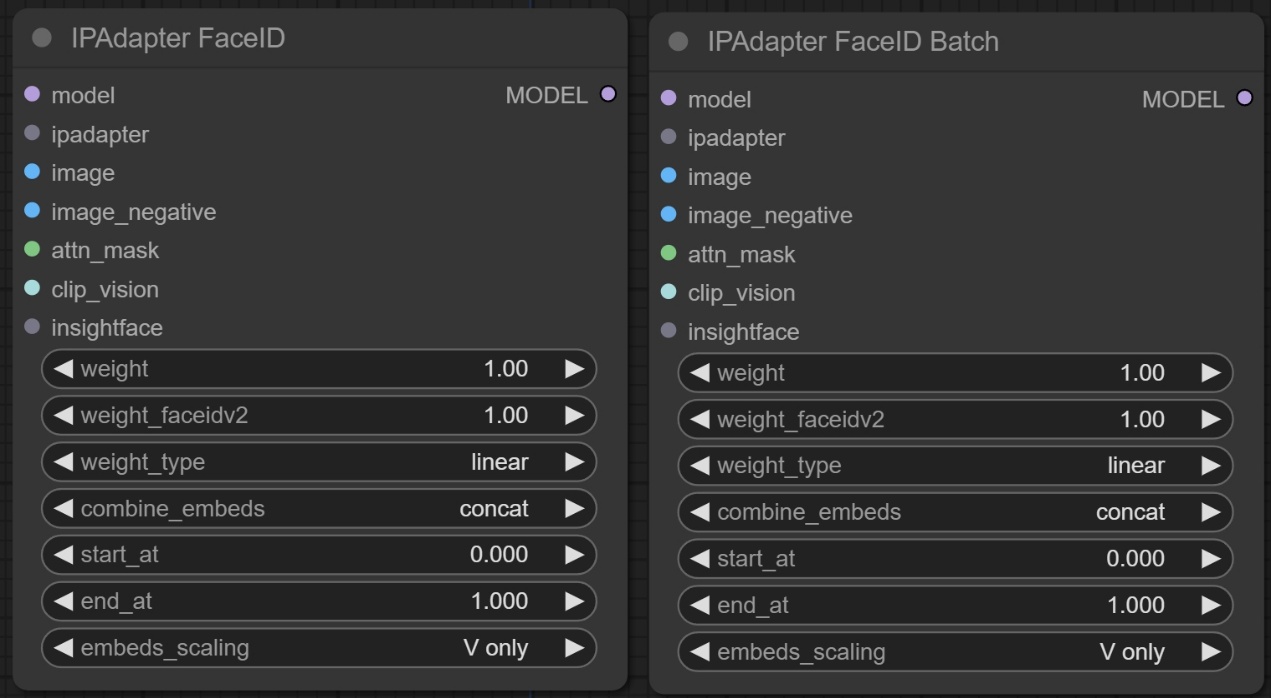
输入:
model -> 要应用模型的对象 ***包含要应用 IPAdapter 的模型对象***
ipadapter -> IPAdapter 模型的配置 ***包含 IPAdapter 模型的文件路径和模型对象***
image -> 图像输入 ***用于 IPAdapter 的图像输入***
image_negative -> 负图像输入 ***用于 IPAdapter 的负图像输入,用于负样本***
attn_mask -> 注意力掩码 ***用于指定注意力的掩码,用于指导 IPAdapter 的注意力***
clip_vision -> CLIP 视觉模型 ***用于提取图像特征的 CLIP 视觉模型***
insightface -> InsightFace 模型 ***用于人脸识别的 InsightFace 模型***
参数:
weight -> 权重参数 ***用于控制 IPAdapter 对图像的影响程度***
weight_faceidv2 -> FaceIDv2 权重参数 ***用于控制 FaceIDv2 对图像的影响程度***
weight_type -> 权重类型 ***指定用于加权的类型***
combine_embeds -> 嵌入组合方式 ***指定如何组合嵌入***
start_at -> 起始位置 ***控制应用 IPAdapter 的起始位置***
end_at -> 结束位置 ***控制应用 IPAdapter 的结束位置***
embeds_scaling -> 嵌入缩放方式 ***指定如何缩放嵌入**
输出:
MODEL -> 输出选择的模型
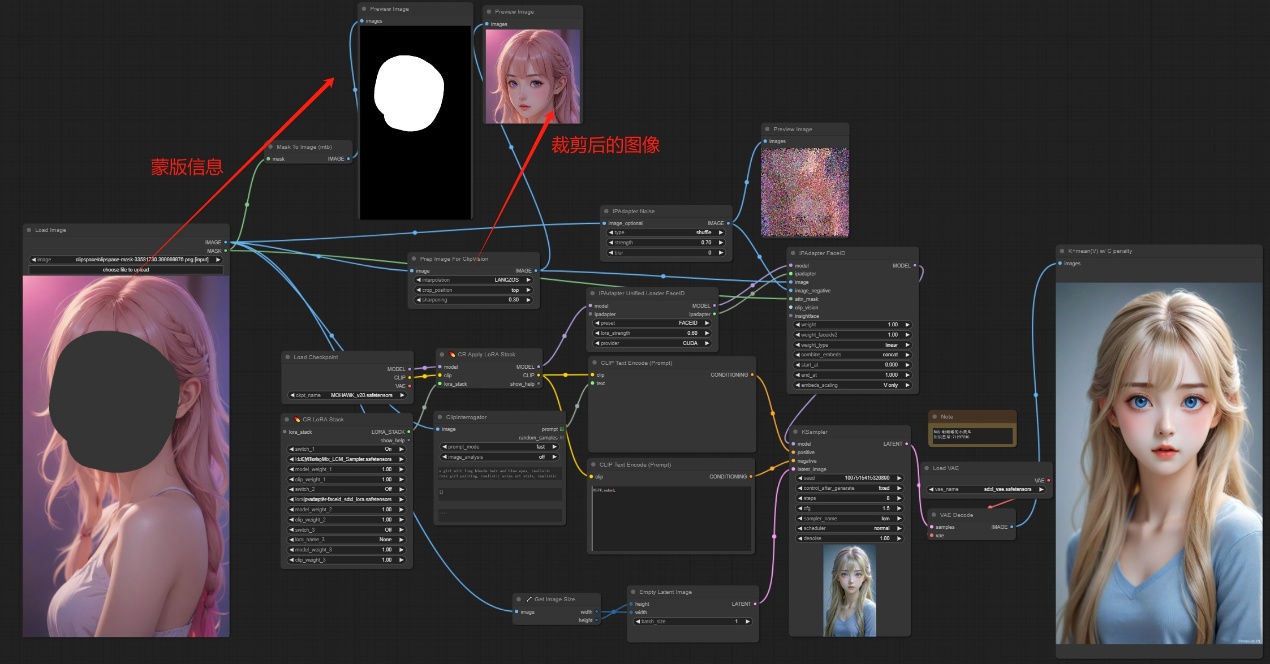
注意:如下图所示,使用faceID之前,对图片要进行预处理,处理成为224*224的正方形才能提供给视觉编码模型,还有就是加入传入的图像不是正方形,裁剪后给到的视觉图像会经过处理,如果在原始图像中画蒙版,那么蒙版区域与处理后的图像并不贴合,所以会导致生成的图像并不像原图。
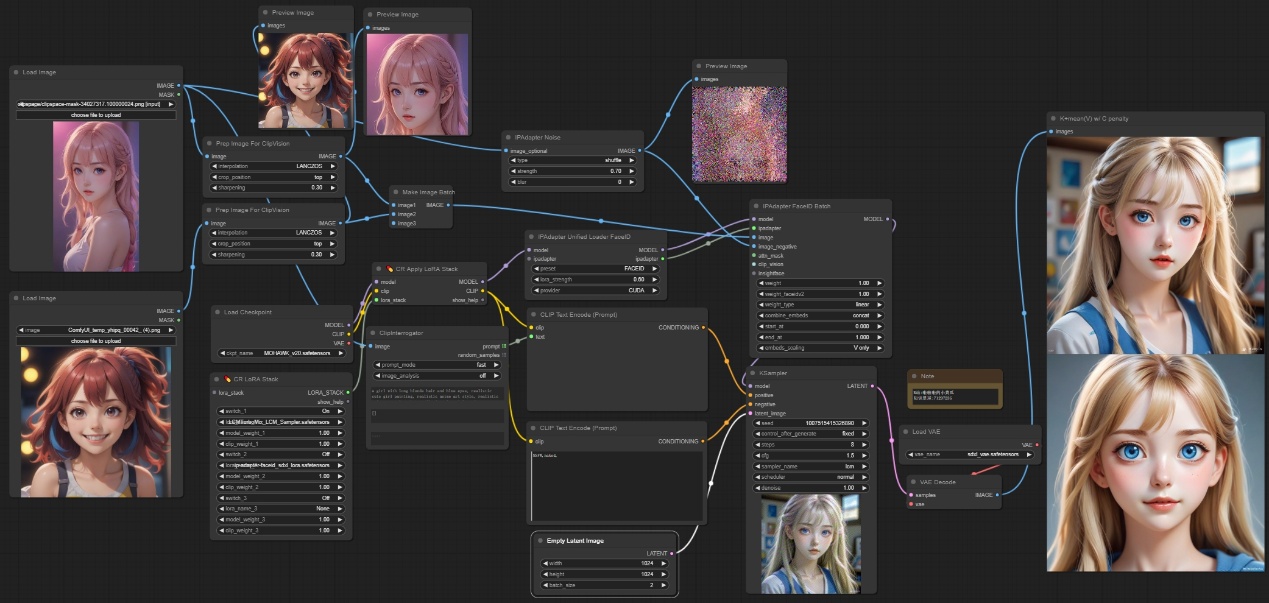
注意:如下图所示ipadapter faceID batch节点可以同时批量处理图像,对原始图像进行裁剪后,组合成一个批量,然后传入该节点,设置latent为2,最终生成参考两个人的面部分别生成两个图像。
四、IPAdapter Tiled/ IPAdapter Tiled Batch节点
节点功能:这两个节点可以输入非正方形的图像,然后对整体分块进行参考,让最终生成的图像参考原图的全部信息。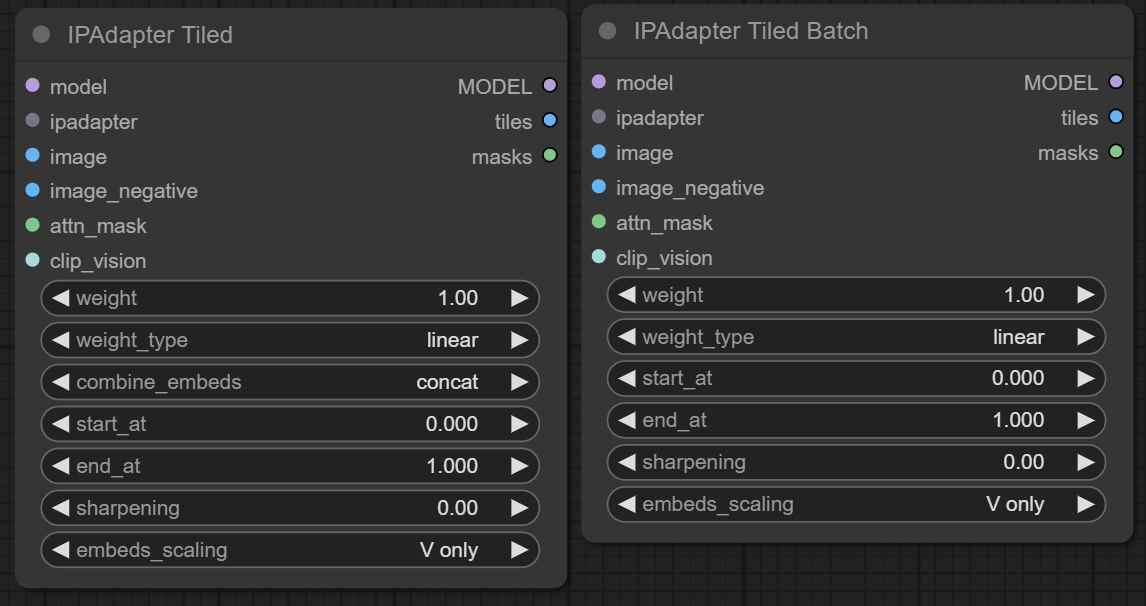
输入:
model -> 要应用模型的对象 ***包含要应用 IPAdapter 的模型对象***
ipadapter -> IPAdapter 模型的配置 ***包含 IPAdapter 模型的文件路径和模型对象***
image -> 图像输入 ***用于 IPAdapter 的图像输入***
image_negative -> 负图像输入 ***用于 IPAdapter 的负图像输入,用于负样本***
attn_mask -> 注意力掩码 ***用于指定注意力的掩码,用于指导 IPAdapter 的注意力***
clip_vision -> CLIP 视觉模型 ***用于提取图像特征的 CLIP 视觉模型***
参数:
weight -> 权重参数 ***用于控制 IPAdapter 对图像的影响程度***
weight_type -> 权重类型 ***指定用于加权的类型***
combine_embeds -> 嵌入组合方式 ***指定如何组合嵌入***
start_at -> 起始位置 ***控制应用 IPAdapter 的起始位置***
end_at -> 结束位置 ***控制应用 IPAdapter 的结束位置***
sharpening -> 锐化程度 ***控制图像的锐化程度***
embeds_scaling -> 嵌入缩放方式 ***指定如何缩放嵌入***
输出:
MODEL -> 输出最终的模型信息
mask -> 如果输入有蒙版,会输出分块后的蒙版信息
tiles -> 输出分块的结果
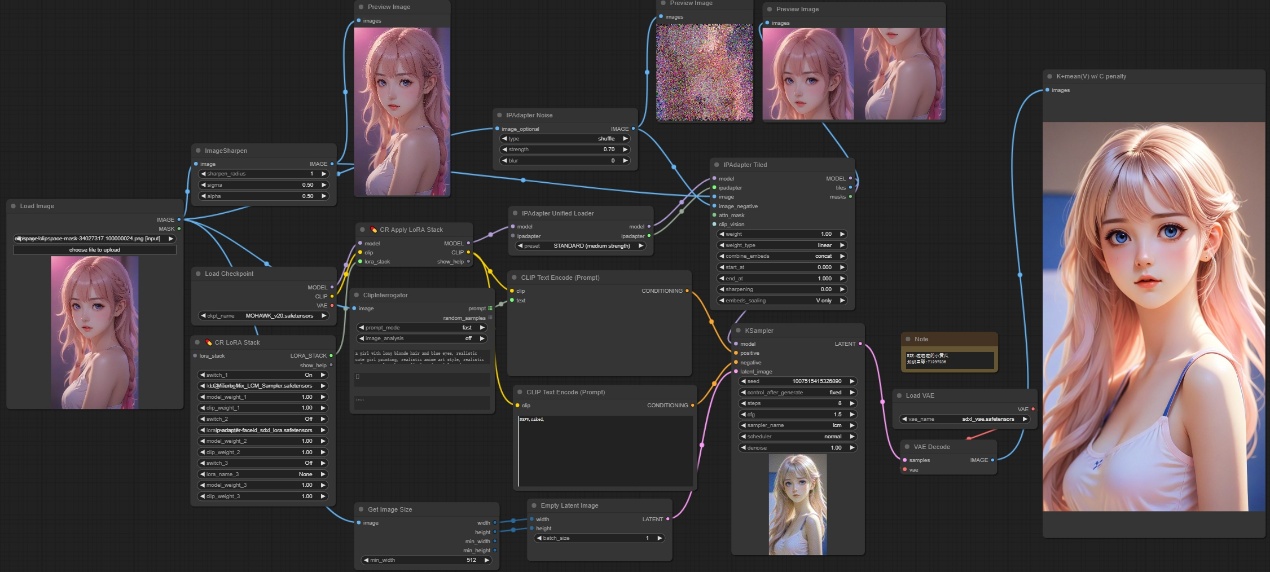
注意:如下图所示,输入图像为长方形,而且并没有对原始图像进行预处理裁剪,经过Tile节点之后,对原始图像进行分割,输出为两块参考图像,最终生成的图像参考了原图的上下两部分,然后生成如图所示的图像。
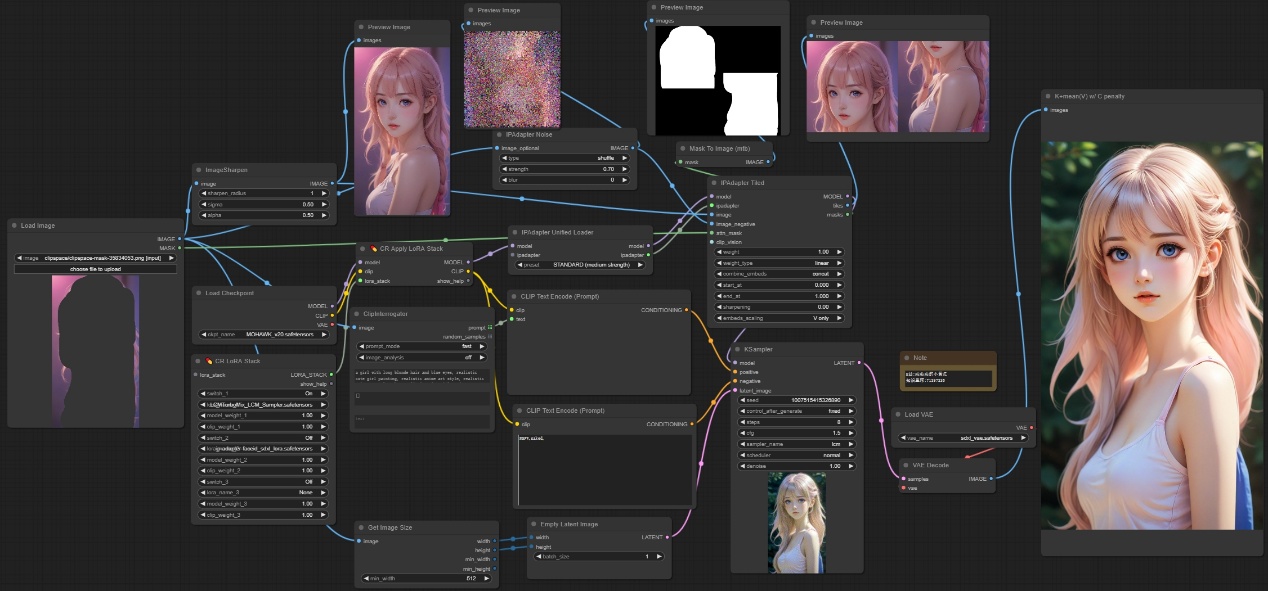
注意:如下图所示,在原图中绘制蒙版,然后将蒙版传入Tiled节点之后,节点会对蒙版也进行相应的裁剪和原始图像一一对应,最终生成的图像只参考蒙版区域进行模仿。
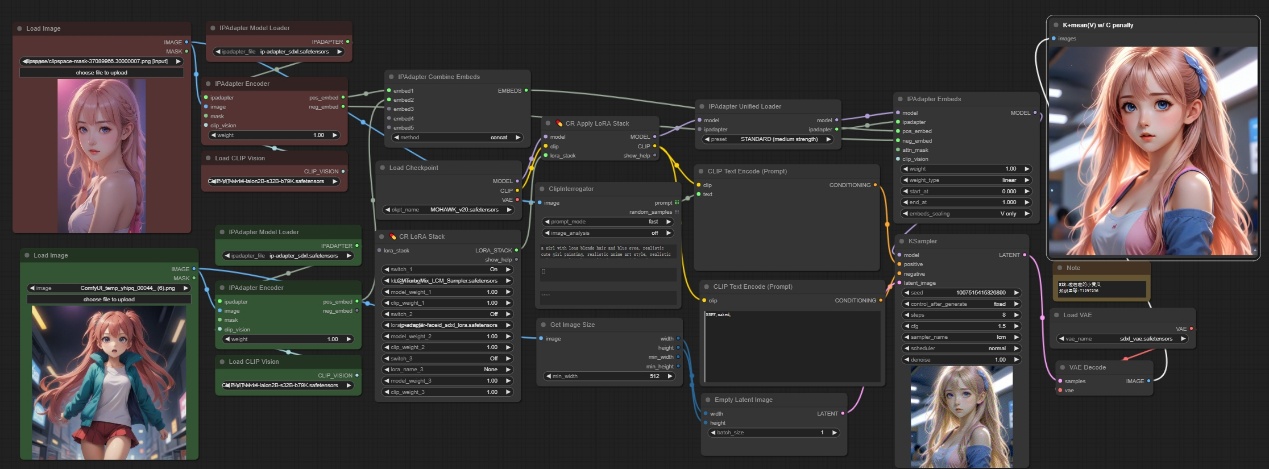
五、IPAdapter Embeds/ IPAdapter Combine Embeds/ IPAdapter Encoder节点
节点功能:这三个节点组合使用,分别是对原始图像进行编码处理,合并编码后的结果,编码结果来影响模型的扩散。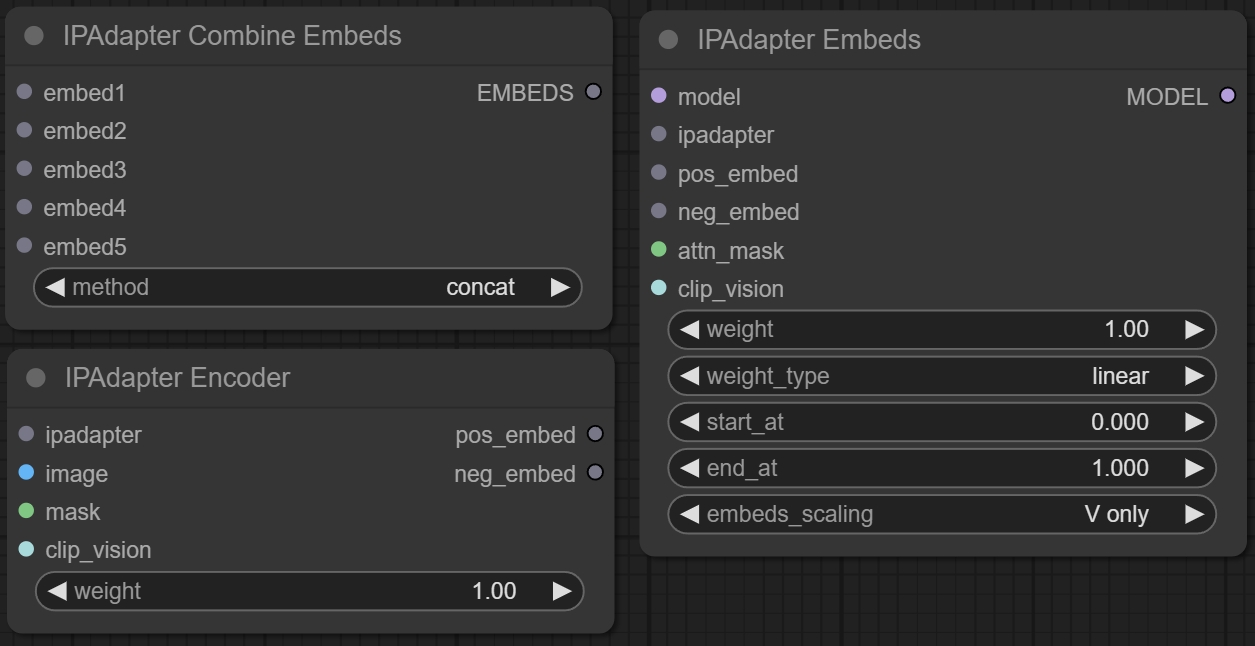
输入:
model -> 要应用模型的对象 ***包含要应用 IPAdapter 的模型对象***
ipadapter -> IPAdapter 模型的配置 ***包含 IPAdapter 模型的文件路径和模型对象***
pos_embed -> 正向嵌入 ***用于 IPAdapter 的正向嵌入***
neg_embed -> 负向嵌入 ***用于 IPAdapter 的负向嵌入,用于负样本***
image -> 图像输入 ***用于 IPAdapter 的图像输入***
attn_mask -> 注意力掩码 ***用于指定注意力的掩码,用于指导 IPAdapter 的注意力***
clip_vision -> CLIP 视觉模型 ***用于提取图像特征的 CLIP 视觉模型***
embedx -> 嵌入的条件信息
参数:
weight -> 权重参数 ***用于控制 IPAdapter 对图像的影响程度***
weight_type -> 权重类型 ***指定用于加权的类型***
combine_embeds -> 嵌入组合方式 ***指定如何组合嵌入***
start_at -> 起始位置 ***控制应用 IPAdapter 的起始位置***
end_at -> 结束位置 ***控制应用 IPAdapter 的结束位置***
输出:
MODEL -> 输出最终的模型信息
embed -> 嵌入编码信息
注意:如下图所示,我们对两张图想分别进行视觉编码然后嵌入,并没有更改原始图像的分辨率,后续将嵌入条件去控制扩散过程,最终出图为融合了两张图像的信息。
六、IPAdapter Noise/ Prep Image For ClipVision节点
节点功能:这两个节点,一个是用来将原图加上噪声,并可以设置一定的控制方法,比如shuffle,第二个节点是将原始图像进行裁剪去生成适合视觉编码的图像。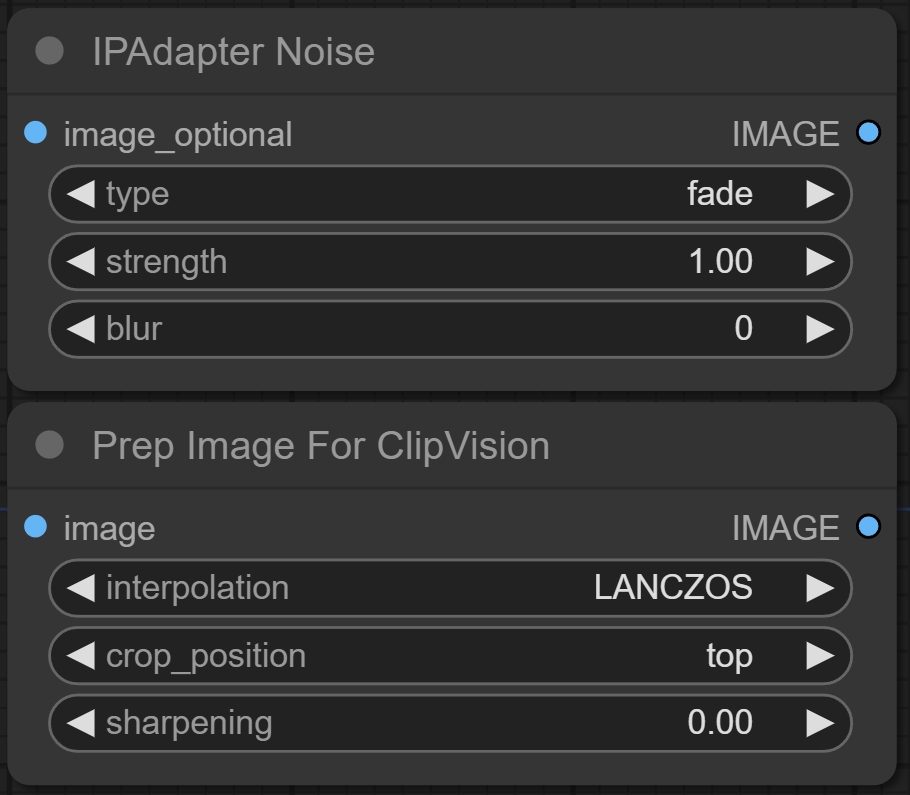
输入:
图像信息
参数:
type -> 噪声类型 ***指定要生成的噪声类型***
strength -> 强度 ***控制噪声的强度,值在 0 到 1 之间,值越大,噪声越明显***
blur -> 模糊程度 ***控制噪声的模糊程度,指定要应用的高斯模糊的半径***
interpolation -> 插值方式 ***指定图像缩放时使用的插值方法***
crop_position -> 裁剪位置 ***指定图像裁剪的位置***
sharpening -> 锐化程度 ***控制图像的锐化程度,值在 0 到 1 之间***
输出:
处理后的图像信息
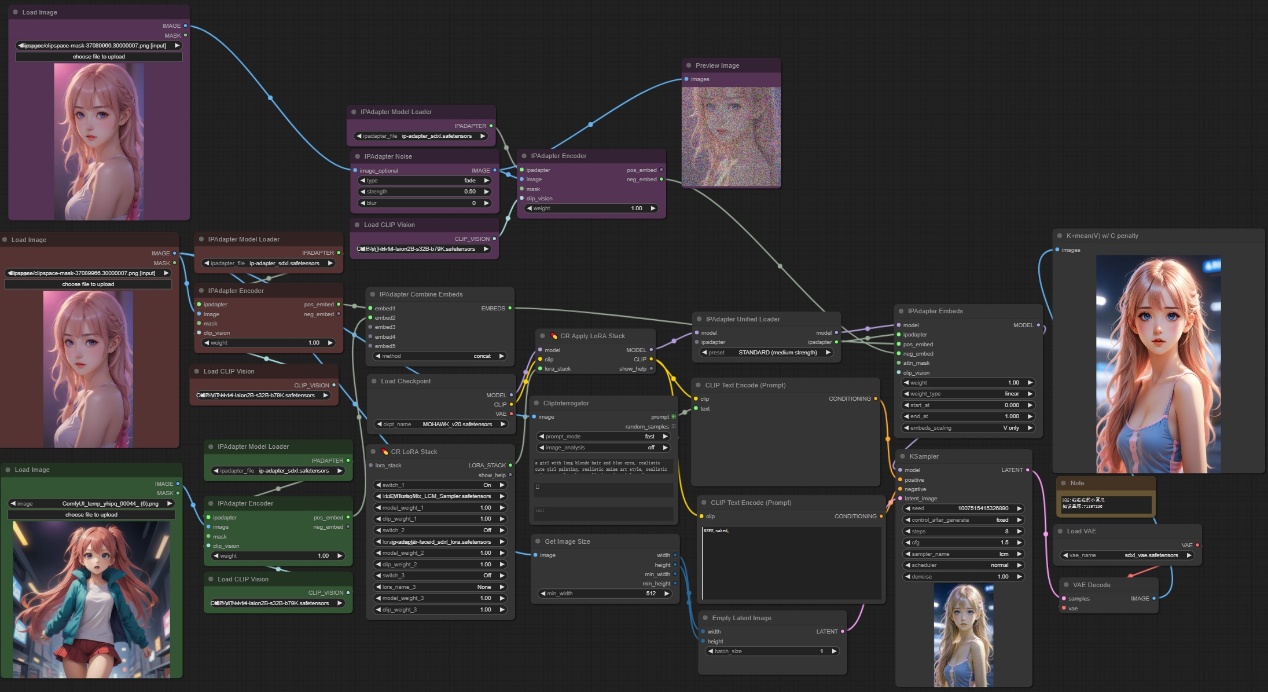
注意:如下图所示,我们可以将原图加上噪声后编码作为反向条件来进行使用,噪声图做反向影响,那么最终出图会更加清晰,也可以直接将噪声图用于ipadapter节点或者faceID节点。
"参考人物换装更换"示例工作流:
学习完以上节点,您就可以搭建“参考人物换装”示例工作流了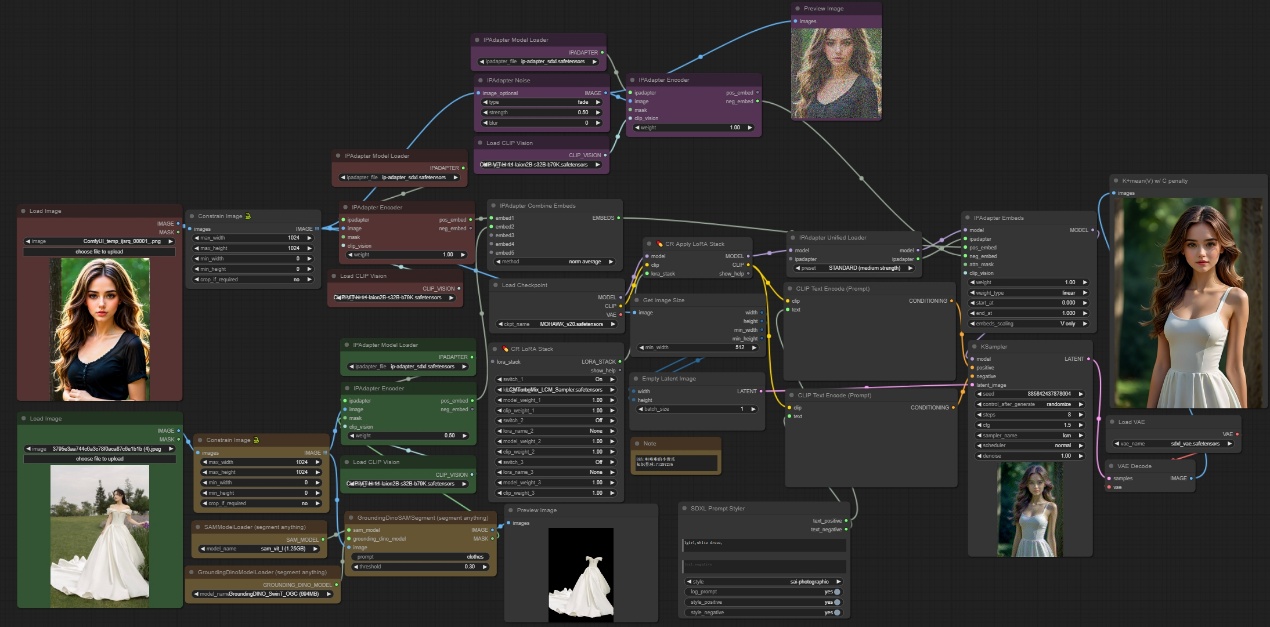
注意:该工作流输入两张图像,一张原始人物图像用来参考脸部和发型,一张一幅图像,用来作为衣服参考,衣服参考图像通过segment anything节点去抠图生成衣服对应的蒙版然后进行embed,人物直接进行embed,人物图像会加入噪声编码后去作为neg embed,然后去控制采样器出图,最终结果如下。
工作流地址:https://pan.quark.cn/s/cd9611fb42eb
孜孜不倦,方能登峰造极。坚持不懈,乃是成功关键。
