【ComfyUI插件】ComfyUI Impact 插件(一)
前言:
ComfyUI Impact 是一个庞大的模块节点库,内置许多非常实用且强大的功能节点 ,例如检测器、细节强化器、预览桥、通配符、Hook、图片发送器、图片接收器等等。通过这些节点的组合运用,我们可以实现的工作有很多,例如__自动人脸检测和优化修复、区域增强、局部重绘、控制人群、发型设计、更换模特服饰__等。在ComfyUI的进阶之路上,ComfyUI Impact是每个人不可绕过的一条大河,所以本篇文章将带领大家理解并学会使用这些节点。
__Comfy Impact插件(二): __https://articles.zsxq.com/impact/2.html
__Comfy Impact插件(三): __https://articles.zsxq.com/impact/3.html
__Comfy Impact插件(四): __https://articles.zsxq.com/imapct/4.html
目录:
先行:安装方式
一、SAMLoader节点
二、UltralyticsDetectorProvider节点
三、BBOX Detector(SEGS) / BBOX Detector(combined)节点
四、SAMDetector(combined) / SAMDetector(segmented)节点
五、Simple Detector(SEGS) / Simple Detector(SEGS/pipe) / Simple Detector for AnimateDiff(SEGS)
六、DetailerDebug(SEGS)节点
示例工作流
安装方法:
方法一:通过ComfyUI Manager安装(推荐)
打开Manager界面
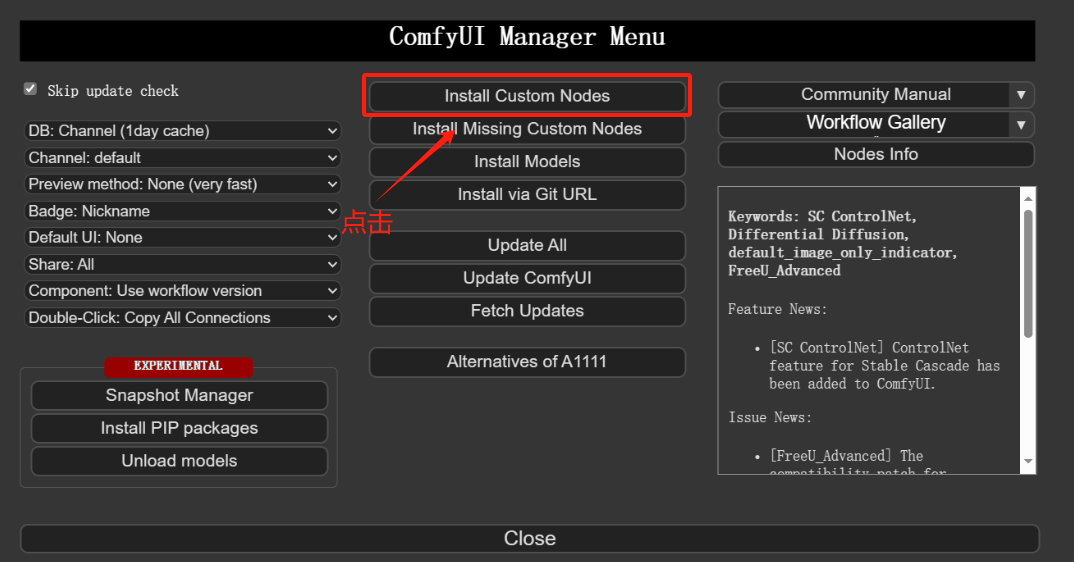
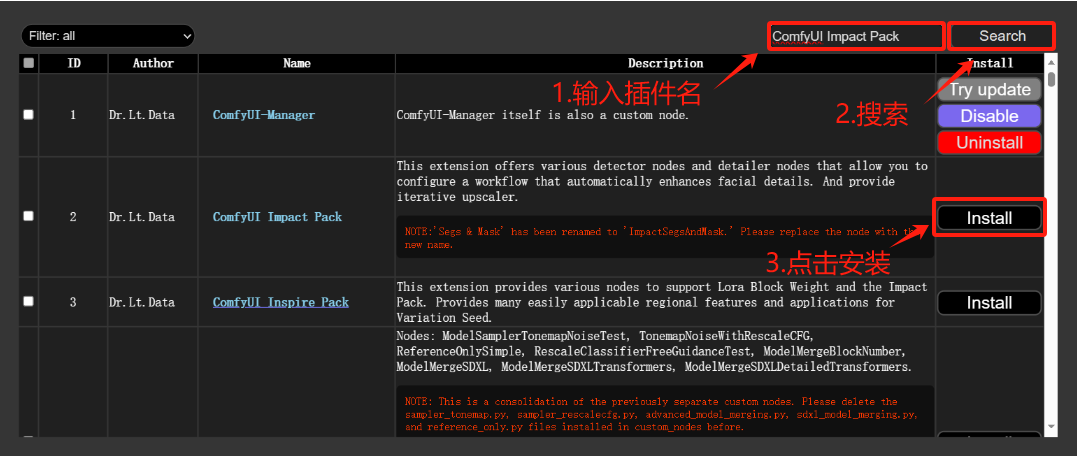
方法二:使用git clone命令安装
在ComfyUI/custom_nodes目录下输入cmd按回车进入电脑终端
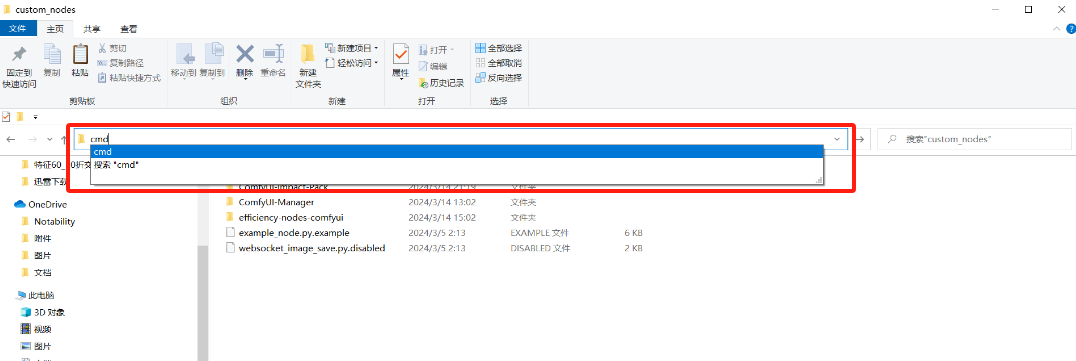
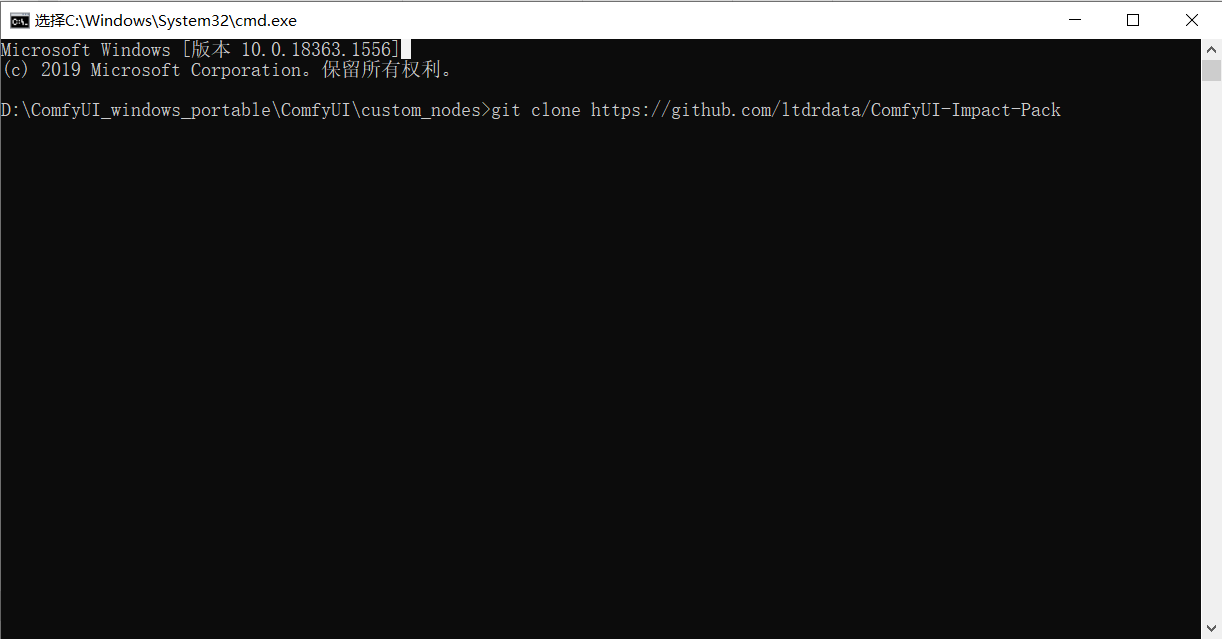
__在终端输入下面这行代码开始下载 __
__git clone __https://github.com/ltdrdata/ComfyUI-Impact-Pack
一、SAMLoader节点
节点功能:加载SAM模型。SAM是Segment Anything Model的缩写,顾名思义SAM模型是一种可以根据我们的需求分割一切东西的模型 。
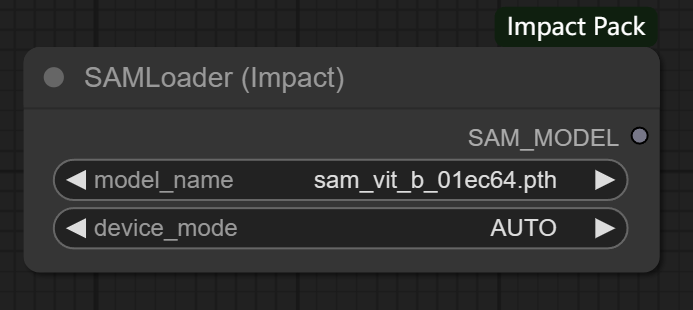
输入:
SAM模型的路径 **假如配置好了路径文件,模型可自行选择**
device_name -> 设备模式,可以选择在GPU或CPU上运行,推荐选择自动即可
输出:
SAM_MODEL -> 根据调用该模型的节点情况对目标进行分割,生成目标的轮廓
注意:该模型不能单独使用,需要其他模型为其指定分割区域,随后该模型可以做到精细的分割。
下面两张图片说明SAM模型在工作流中的位置和它起到的作用:
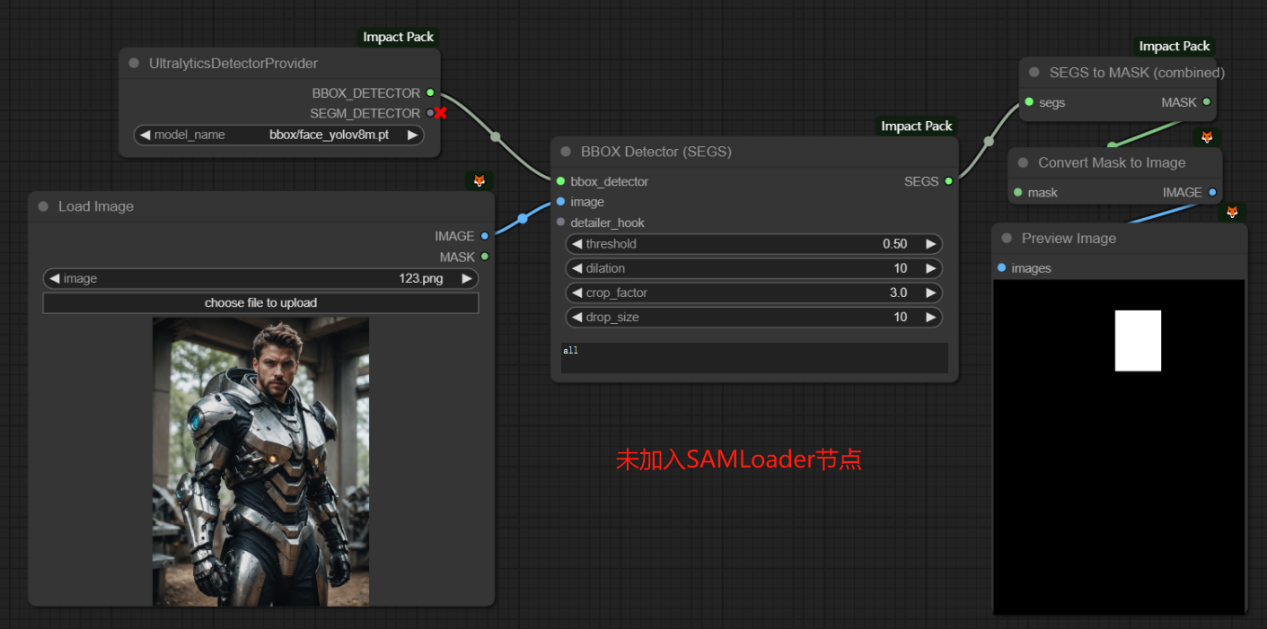
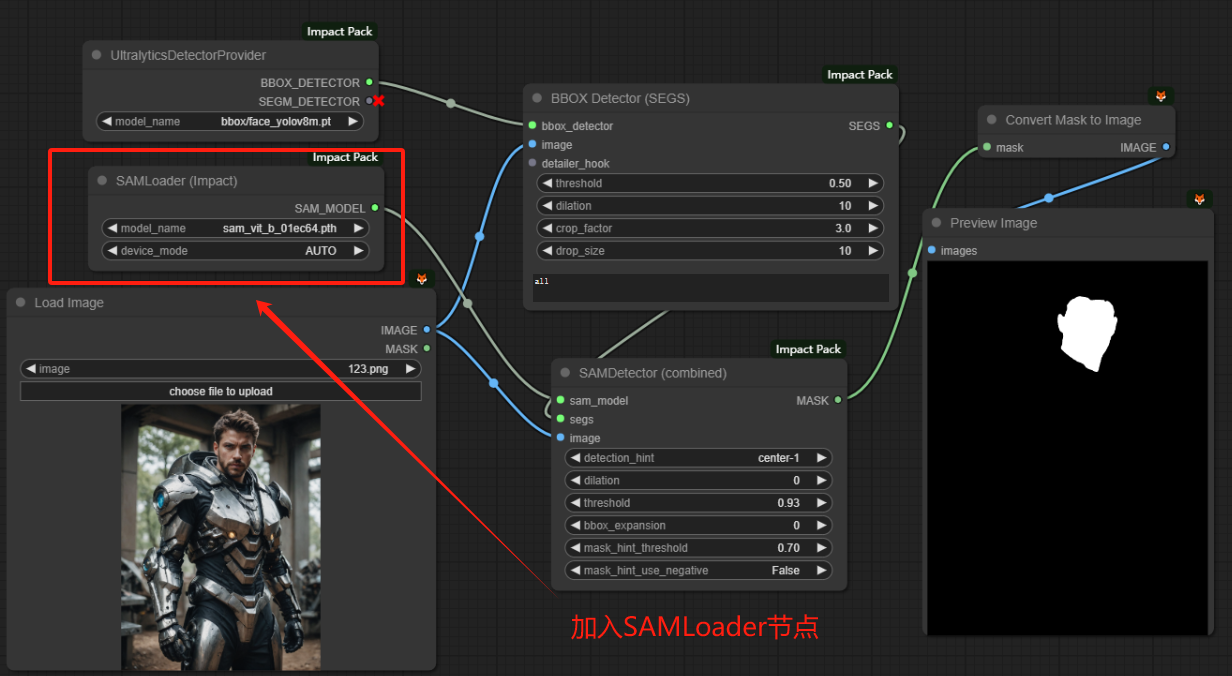
二、UltralyticsDetectorProvider节点
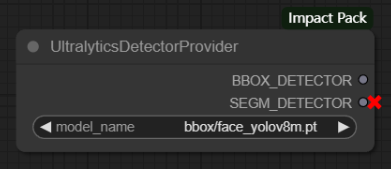
节点功能:此节点提供一个基于Ultralytics的目标检测器,用于替换现有基于mmdet的检测器,可加载BBOX_Model和SEGM_Model两种模型之一。
输入:
目标检测模型的路径 **主流的模型有脸部检测、手部检测、身体检测等,假如配置好了路径文件,模型可自行选择**
输出:
BBOX_DETECTOR -> 使用矩形框进行检测
SEGM_DETECTOR -> 检测出目标的轮廓
注意:该节点只能加载BBOX和SEGM中的一种模型,并且要根据model_name中所选的模型类型进行连接,例如我的bbox/face_yolov8m.pt是一个BBOX类型的脸部检测模型,所以再连线时我就要选择BBOX_DETECTOR进行连线,这也是SEGM_DETECTOR会显示红叉的原因。
下面两张图片说明BBOX模型和SEGM模型的区别:
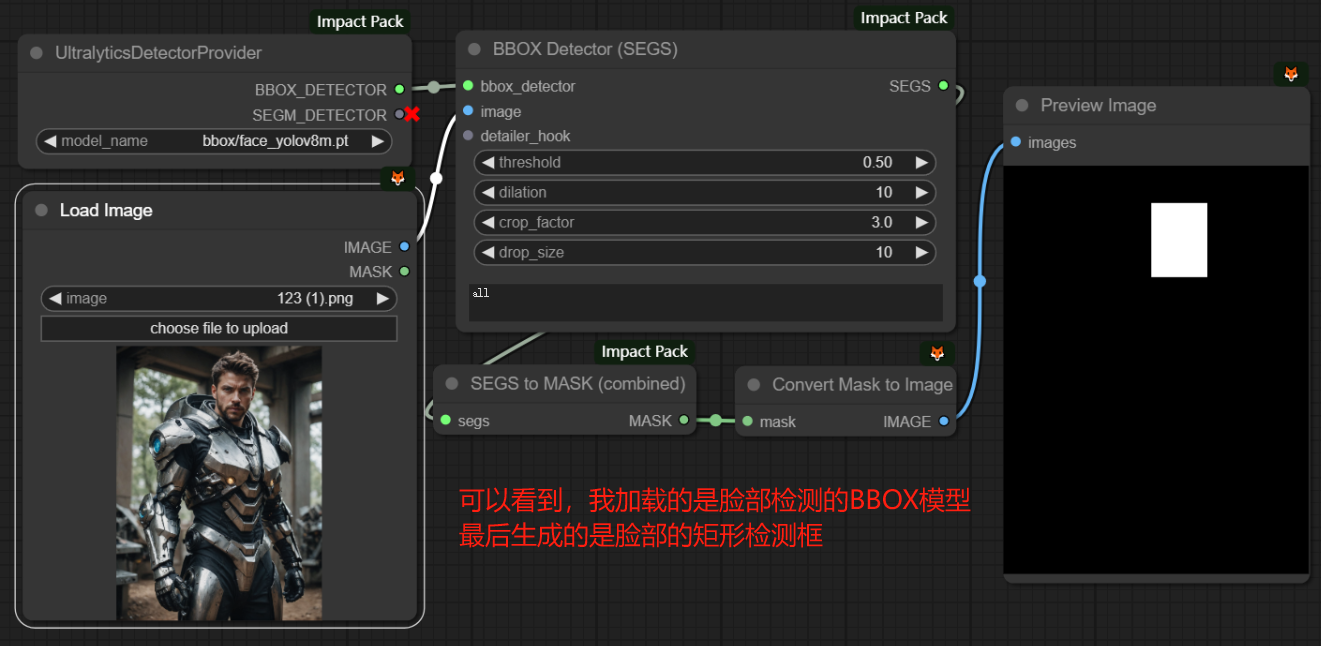
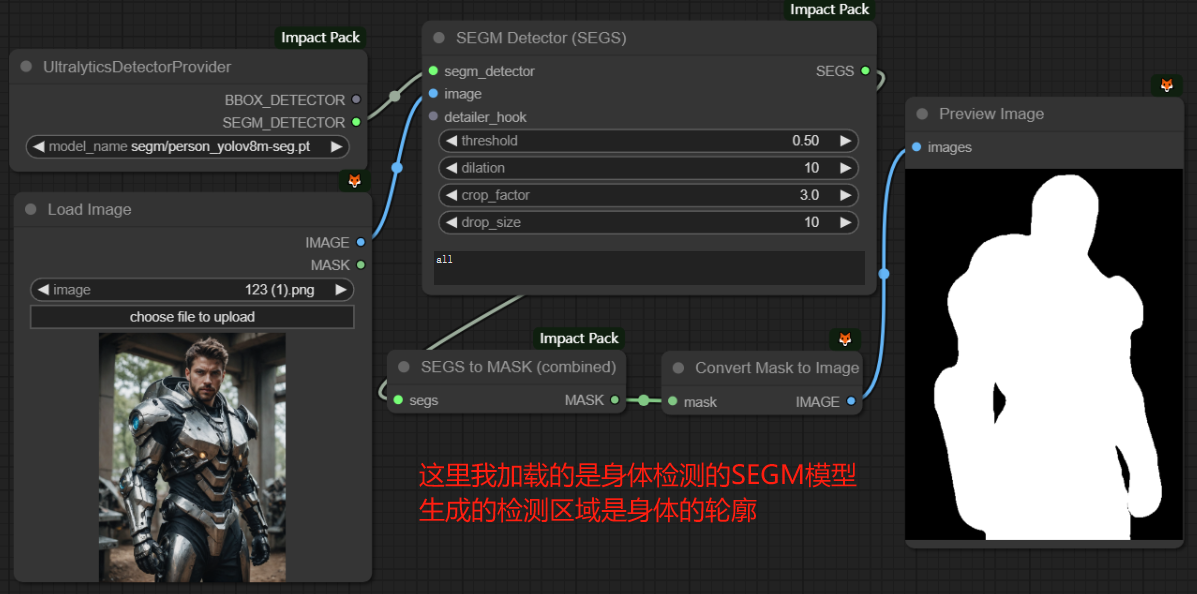
三、BBOX Detector(SEGS) / BBOX Detector(combined)节点
节点功能:根据输入的模型的功能对图片进行目标检测,输出带有检测信息的数据。这两个节点的区别在于输出的数据类型不同,前者输出的SEGS数据包括每次检测的裁剪图像、掩码图案、裁剪位置和置信度;后者输出的MASK数据是将所有检测到的矩形框组合得到的单个掩码。
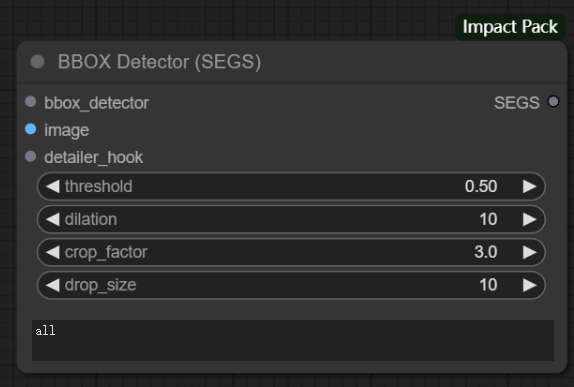
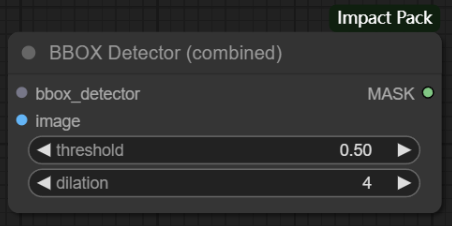
输入:
bbox_detector -> BBOX类型的检测模型
image -> 输入加载的图片
detailer_hook -> impact库的一个特殊参数,用于在模型的不同阶段或特定事件发生时执行一些额外的操作
参数:
threshold -> 阈值,仅检测已识别置信度高于此值的对象
dilation -> 调整最终显示时,检测到的掩码区域的大小
crop_factor -> 根据检测到的掩码区域,确定应将周围区域包含在细节修复过程中的次数 **如果此值较小,则修复可能无法正常工作,因为无法知道周围的上下文**
drop_size -> 降低尺寸,用于控制细节增强过程中的图像降低尺寸的大小。
文本框 -> 用于输入文本指定被允许检测的地方
输出:
SEGS -> 包含每次检测的裁剪图像、掩码图案、裁剪位置和置信度
MASK -> 所有检测到的矩形框组合而成的单个掩码
四、SAMDetector(combined) / SAMDetector(segmented)节点
节点功能:SAM模型对应的检测器,可以接收加载的SAM模型并对图像进行分割,最后输出分割后的结果。
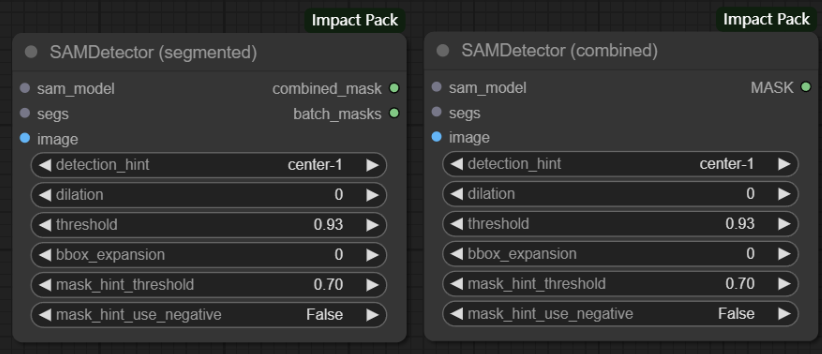
输入:
sam_model -> 接收SAMLoader节点加载的SAM模型
segs -> 接收UltralyticsDetectorProvider节点加载的目标检测模型 **前面说过SAM模型不能单独使用**
image -> 接收加载的图片
参数:
detection_hint -> 用来指定在分割时使用哪种类型的检测结果作为提示来帮助生成掩码
dilation -> 膨胀分割结果的边界
threshold -> 阈值,仅检测已识别置信度高于此值的对象
bbox_expansion -> 控制在生成轮廓时扩展边界的大小,以确保更好地包含目标对象
mask_hint_threshold -> 与mask_hint_use_nagative参数一起使用,用于指定detection_hint的阈值,将掩码区域中的掩码值等于或高于阈值的情况解释为正提示
注意:大于 0 但小于mask_hint_threshold的值不用作否定提示。
mask_hint_use_nagative -> 控制是否使用负提示来辅助分割 **设置为True时,非常小的点被解释为掩码点中的负面提示,而掩码值为0的一些区域被解释为掩码区域中的负面提示**
输出:
combined_mask -> 分割节点的深度信息,包含整个图像的分割结果
batch_masks -> 分割节点的深度信息,包含批处理中每个样本的分割结果
MASK -> 分割节点的深度信息,包含整个图像的分割结果
注意:1.这两个节点本质上没有任何区别。当需要的是整个图像的分割结果时,这两个节点可以二选一进行使用;当需要每个样本的分割结果时就需要选择SAMDetector(segmented)节点;2.若要连接MaskToSegs节点,需将 “combined” 参数设置为False。
五、Simple Detector(SEGS)/Simple Detector(SEGS/pipe)/Simple Detector for AnimateDiff(SEGS)节点
节点功能:与前面几个检测器的功能类似,都是接收模型->分割->输出分割结果。其中Simple Detector for AnimateDiff(SEGS)节点是专门针对动画帧序列中图像裁剪任务的。
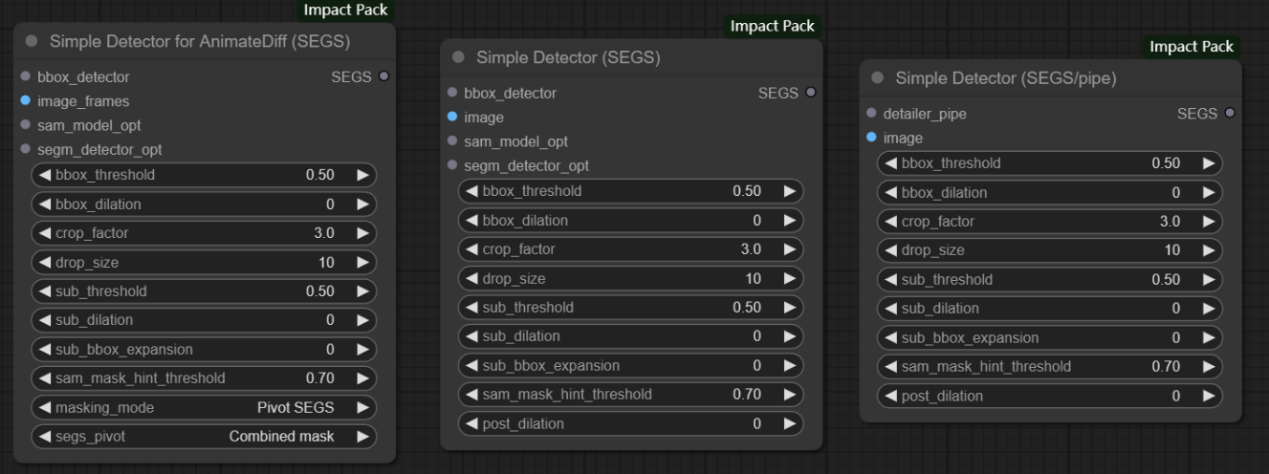
输入:
bbox_detector -> 接收BBOX模型
image_frames -> 动画帧的输入图像序列
image -> 接收待分割的图片
sam_model_opt -> 接收SAM模型
segm_detector_opt -> 接收SEGM模型
detailer_pipe -> 输入细节调整的参数,使分割结果更加完美
参数:
bbox_threshold -> BBOX模型的检测阈值
bbox_dilation -> BBOX模型边界框的膨胀参数,用于扩展边界框的范围
crop_factor -> 裁剪因子,用于裁剪图像
drop_size -> 设置一个尺寸阈值,用于过滤较小目标的参数 **去除噪声或不相关的小目标,使得检测结果更加可靠和准确**
sub_dilation -> 子图的膨胀参数
sub_bbox_expansion -> 子图BBOX模型的边界框扩展参数
sam_mask_hint_threshold -> SAM模型的掩码提示阈值
masking_mode -> 调节掩码模式
segs_pivot -> 选择动画差异检测的基准点
post_dilation -> 后期处理膨胀参数,用于对结果进行完善 **改善检测结果的连通性或者填补检测结果中的小孔洞**
输出:
SEGS -> 分割结果的深度信息 **Simple Detector for AnimateDiff(SEGS)节点则是输出检测到的动画差异**
六、DetailerDebug(SEGS)节点
节点功能:放大图像并在内部利用 KSampler 对图像进行绘制。
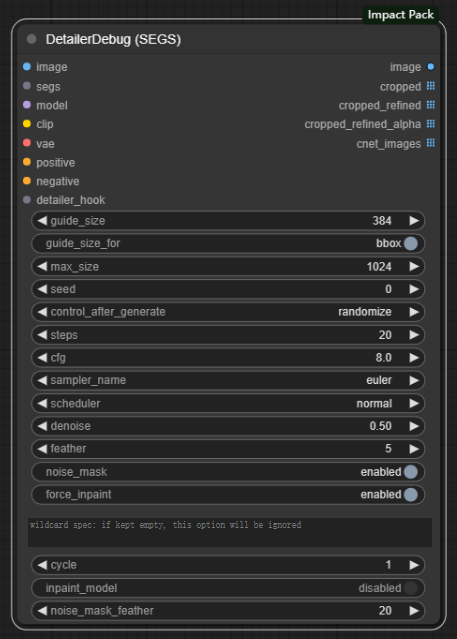
输入:
image -> 需要重绘的原始图像
segs -> 输入分割模型得到的分割结果
model -> checkpoints大模型
clip -> 提示词编码模型
vae -> vae模型
positive -> 正向提示词
negative -> 反向提示词
detailer_hook -> 对模型进行更加精细调整的拓展接口
注意:这里的正向提示词和反向提示词都是针对重绘部分的,用于指导重绘后的图像。
参数:
guide_size -> 参考尺寸 **小于的目标图像被放大以匹配,而大于的图像将被跳过,因为它们不需要细节处理**
guide_size_for -> 设置guide_size基于什么 **当设置为bbox时,它使用检测器检测到的bbox作为参考;当设置为crop_region时,它使用基于检测到的bbox所识别的裁剪区域作为参考**
注意:选择BBOX时,基于crop_factor的放大图像的大小可能比guide_size大几倍。
max_size -> 最大尺寸 **将目标图像的最长边限制为小于max_size的安全措施,它解决了bbox可能变得过大的问题,特别是如果它有细长的形状**
seed -> 内置KSampler的种子
contorl_after_generate -> 控制种子的变更方式 **fixed为固定种子,increment为每次增加1,decrement为每次减少1,randomize为种子随机**
steps -> 去噪步数(也可以理解成生成图片的步数)
cfg -> 提示词引导系数,即提示词对结果产生影响的大小 **过高会产生负面影响**
sampler_name -> 选择采样器
scheduler -> 选择调度器
denoise -> 去噪幅度 **值越大对图片产生的影响和变化越大**
feather -> 羽化的大小
noise_mask -> 控制在修复过程中是否使用噪声掩码 **虽然在不用噪声掩码的情况下,较低的去噪值有时会产生更自然的结果,但通常建议将该参数设置为enabled**
force_inpaint -> 防止跳过基于guide_size的所有过程 **当目标是修复而不是细化时,这很有用。小于guide_size的SEGS不会通过减小去匹配guide_size;相反,它们会被修复为原来的大小**
文本框 -> 输入通配符的规范,如果保持为空,此选项将被忽略
cycle -> 采样的迭代次数 **当与Detailer_hook一起使用时,此选项允许添加间歇性噪声,也可用于逐渐减小去噪大小,最初建立基本结构,然后对其进行细化。
inpaint_model -> 使用修复模型时,需要启用此选项,以确保在低于1.0的降噪值下进行正确的内补
noise_mask_feather -> 控制羽化操作是否应用于修复过程的蒙版
注意:此选项不能保证图像更自然,同时它可能会在边缘产生伪影,大家按需设置!
输出:
image -> 最终重绘后的图片
cropped -> 调整图像的大小、去除不必要的部分、集中注意力于特定区域的效果图
cropped_refined -> 经过剪裁和进一步处理的图像
cropped_refined_alpha -> 经过裁剪和精细化处理后的alpha通道
cnet_images -> 蒙版位置图
注意:!!!cnet_images参数的含义是我个人的推测,因为该参数使用的频率极少,也查询不到关于它的资料,同时我使用Preview Image预览该图时,图片只显示在重绘部分的黑色矩形图。关于这个参数请大家思考后吸收!
“AI换脸”示例工作流:
学习完以上节点,您就可以搭建一个简易的“AI换脸”工作流了
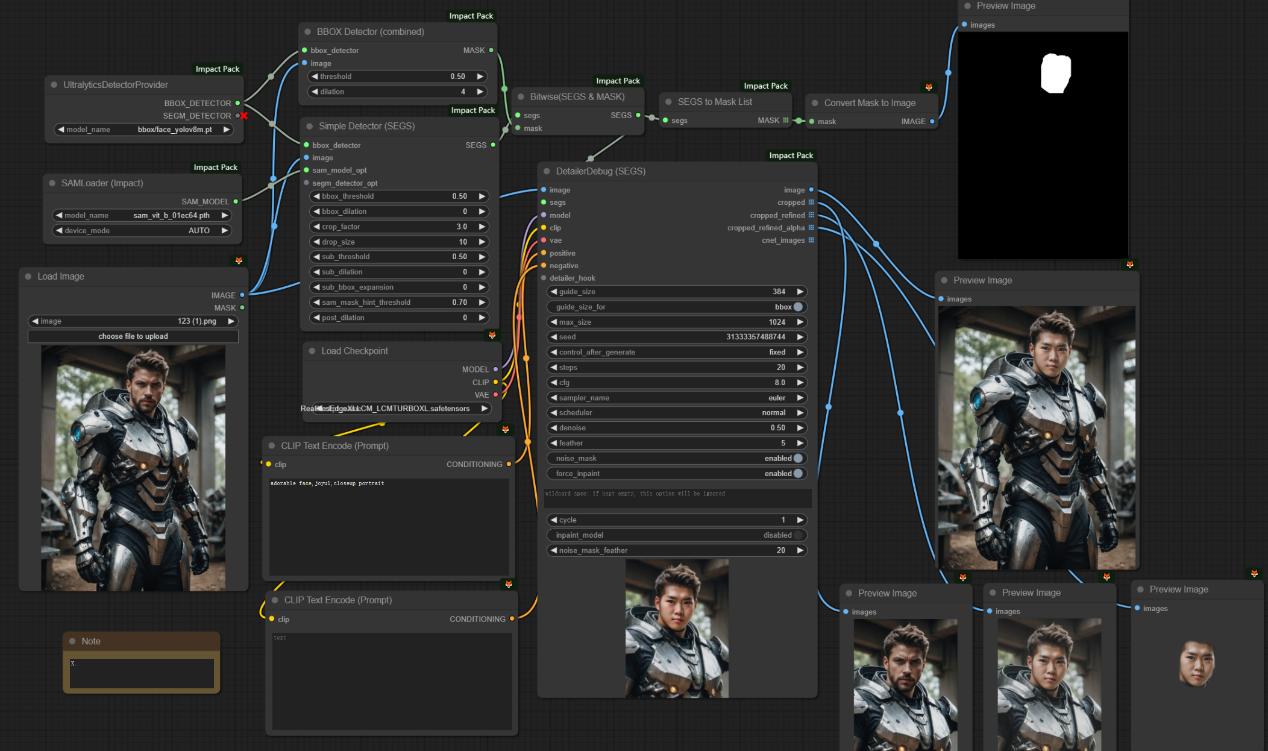
该工作流先是对加载的图片进行脸部的检测和分割,然后将分割的结果、原图、重绘的提示词输入细节修复器中,在细节修复器中,内置的采样器会根据提示词对图片的脸部进行重新扩散,最后输出换脸之后的图。原图和换脸后的图如下所示:


__Comfy Impact插件(二): __https://articles.zsxq.com/impact/2.html
__Comfy Impact插件(三): __https://articles.zsxq.com/impact/3.html
__Comfy Impact插件(四): __https://articles.zsxq.com/imapct/4.html
